Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktivitet i Azure Data Factory- och Synapse Analytics-pipelines för att kopiera data från och till Azure Database for PostgreSQL. Och hur du använder Data Flow för att transformera data i Azure Database for PostgreSQL. Mer information finns i introduktionsartiklarna för Azure Data Factory och Synapse Analytics.
Viktigt!
Azure Database for PostgreSQL version 2.0 ger förbättrat inbyggt stöd för Azure Database for PostgreSQL. Om du använder Azure Database for PostgreSQL version 1.0 i din lösning rekommenderar vi att du uppgraderar Azure Database for PostgreSQL-anslutningsprogrammet så snart som möjligt.
Den här anslutningsappen är specialiserad för Azure Database for PostgreSQL-tjänsten. Om du vill kopiera data från en allmän PostgreSQL-databas som finns lokalt eller i molnet använder du PostgreSQL-anslutningsappen.
Funktioner som stöds
Den här Azure Database for PostgreSQL-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | Infrarött | Hanterad privat slutpunkt | Versioner som stöds av anslutningsappen |
|---|---|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) | ✓ | 1,0 & 2,0 |
| Kartläggning av dataflöde (källa/slutpunkt) | (1) | ✓ | 1,0 & 2,0 |
| Sökningsaktivitet | (1) (2) | ✓ | 1,0 & 2,0 |
| Skriptaktivitet | (1) (2) | ✓ | 2.0 |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
De tre aktiviteterna fungerar på Azure Database for PostgreSQL – enskild server, flexibel server och Azure Cosmos DB för PostgreSQL.
Viktigt!
Azure Database for PostgreSQL – enskild server dras tillbaka den 28 mars 2025. Migrera till flexibel server vid det datumet. Du kan läsa den här artikeln och vanliga frågor och svar om migreringsvägledningen.
Komma igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Kopiera data-verktyget
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST-API
- mall för Azure Resource Manager
Skapa en länkad tjänst till Azure Database for PostgreSQL med hjälp av användargränssnittet
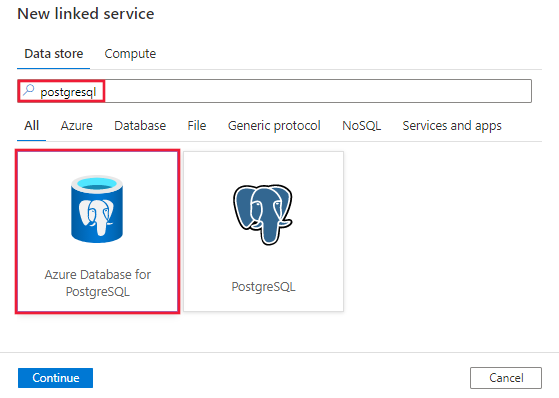
Använd följande steg för att skapa en länkad tjänst till Azure Database for PostgreSQL i Azure Portal användargränssnittet.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och välj sedan Nytt:
Sök efter PostgreSQL och välj Azure-databasen för PostgreSQL-anslutningsprogrammet.
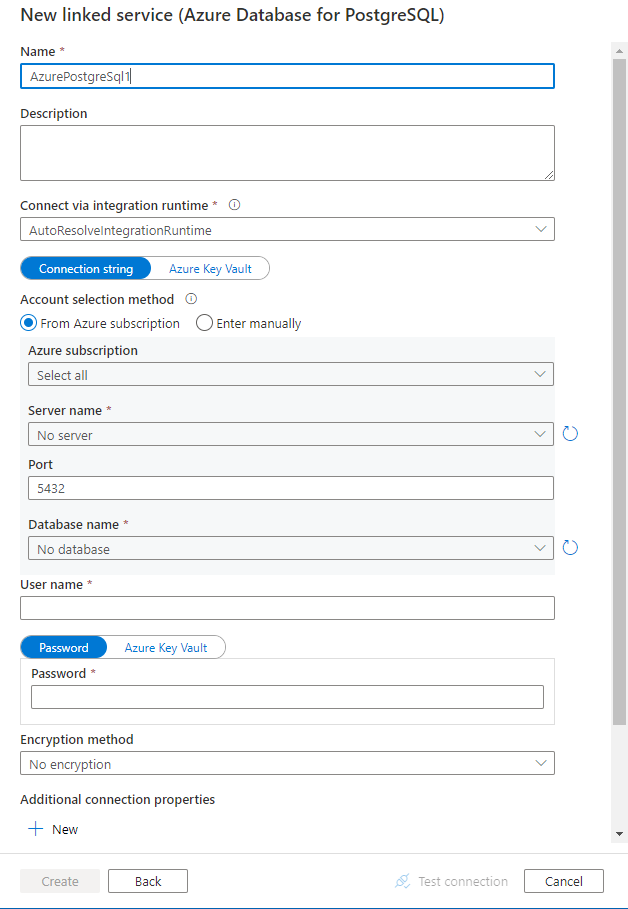
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Konfigurationsinformation för anslutning
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Azure Database for PostgreSQL-anslutningstjänsten.
Länkade tjänstegenskaper
Azure Database for PostgreSQL-anslutningsappen version 2.0 stöder TLS (Transport Layer Security) 1.3 och flera SSL-lägen (Secured Socket Layer). Se det här avsnittet om du vill uppgradera azure SQL Database-anslutningsversionen från version 1.0. Information om fastigheten finns i de motsvarande avsnitten.
Version 2.0
Följande egenskaper stöds för den länkade tjänsten Azure Database for PostgreSQL när du tillämpar version 2.0:
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen måste anges till: AzurePostgreSql. | Ja |
| version | Den version som du anger Värdet är 2.0. |
Ja |
| autentiseringstyp | Välj mellan grundläggande, tjänstens huvudnamn, systemtilldelade hanterade identiteter eller användartilldelade autentiseringstyper för hanterade identiteter | Ja |
| server | Anger värdnamnet och valfri port som Azure Database for PostgreSQL körs på. | Ja |
| port/hamn | TCP-porten för Azure Database for PostgreSQL-servern. Standardvärdet är 5432. |
Nej |
| databas | Namnet på den Azure Database for PostgreSQL-databas som ska anslutas till. | Ja |
| ssl-läge | Styr om SSL används, beroende på serversupport. - Inaktivera: SSL är inaktiverat. Om servern kräver SSL misslyckas anslutningen. - Tillåt: Föredrar icke-SSL-anslutningar om servern tillåter dem, men tillåter SSL-anslutningar. - Föredrar: Föredrar SSL-anslutningar om servern tillåter dem, men tillåter anslutningar utan SSL. - Kräv: Anslutningen misslyckas om servern inte stöder SSL. - Verify-ca: Anslutningen misslyckas om servern inte stöder SSL. Verifierar även servercertifikatet. - Verifiera: Anslutningen misslyckas om servern inte stöder SSL. Verifierar även servercertifikatet med värdnamn. Alternativ: Inaktivera (0) / Tillåt (1) / Föredrar (2) (standard) / Kräv (3) / Verify-ca (4) / Verifiera fullständig (5) |
Nej |
| connectVia | Den här egenskapen representerar den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
| Ytterligare anslutningsegenskaper: | ||
| Schemat | Anger sökvägen till schemasökningen. | Nej |
| sammanslagning | Om anslutningspooler ska användas. | Nej |
| anslutningstidsgräns | Tiden att vänta (i sekunder) när du försöker upprätta en anslutning innan du avslutar försöket och genererar ett fel. | Nej |
| kommandoTidsgräns | Tiden att vänta (i sekunder) när du försöker köra ett kommando innan du avslutar försöket och genererar ett fel. Ställ in på noll för oändligheten. | Nej |
| litaPåServercertifikat | Om du vill lita på servercertifikatet utan att verifiera det. | Nej |
| läsbuffertstorlek | Avgör storleken på den interna buffert som Npgsql använder vid läsning. Att öka kan förbättra prestanda om du överför stora värden från databasen. | Nej |
| tidszon | Hämtar eller ställer in sessionens tidszon. | Nej |
| kodning | Hämtar eller anger .NET-kodningen för kodning/avkodning av PostgreSQL-strängdata. | Nej |
Grundläggande autentisering
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| användarnamn | Användarnamnet som ska anslutas till. Krävs inte om du använder IntegratedSecurity. | Ja |
| lösenord | Lösenordet som ska anslutas till. Krävs inte om du använder IntegratedSecurity. Markera det här fältet som SecureString för att lagra det på ett säkert sätt. Eller så kan du referera till en hemlighet som lagras i Azure Key Vault. | Ja |
Exempel:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Exempel:
Lagra lösenord i Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Systemtilldelad autentisering av hanterad identitet
En datafabrik eller Synapse-arbetsyta kan associeras med en systemtilldelad hanterad identitet som representerar tjänsten när den autentiseras mot andra resurser i Azure. Du kan använda den här hanterade identiteten för Azure Database for PostgreSQL-autentisering. Den avsedda fabriken eller Synapse-arbetsytan kan komma åt och kopiera data från eller till databasen med hjälp av den här identiteten.
Följ stegen för att använda systemtilldelad hanterad identitet:
En datafabrik eller Synapse-arbetsyta kan associeras med en systemtilldelad hanterad identitet. Läs mer, Generera systemtilldelad hanterad identitet
Azure-datatjänst för PostgreSQL med systemtilldelad hanterad identitet på.

I din PostgreSQL-databasresurs i Azure under Säkerhet
Välj autentisering
Välj antingen Endast Microsoft Entra-autentisering eller PostgreSQL- och Microsoft Entra-autentiseringsmetod .
Välj + Lägg till Microsoft Entra-administratörer
Lägg till den systemtilldelade hanterade identiteten för Azure Data Factory-resursen som en av Microsoft Entra-administratörerna

Konfigurera en ansluten Azure-databas för PostgreSQL-tjänst.


Exempel:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "SystemAssignedManagedIdentity"
}
}
}
Anmärkning
Den här autentiseringstypen stöds inte på den lokala integrationskörningen.
Användartilldelad hanterad identitetsautentisering
En datafabrik eller Synapse-arbetsyta kan associeras med en användartilldelad hanterad identitet som representerar tjänsten när den autentiseras mot andra resurser i Azure. Du kan använda den här hanterade identiteten för Azure Database for PostgreSQL-autentisering. Den avsedda fabriken eller Synapse-arbetsytan kan komma åt och kopiera data från eller till databasen med hjälp av den här identiteten.
Om du vill använda användartilldelad hanterad identitetsautentisering anger du, förutom de allmänna egenskaper som beskrivs i föregående avsnitt, följande egenskaper:
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| förtroendeuppgift | Ange den användartilldelade hanterade identiteten som autentiseringsobjekt. | Ja |
Du måste också följa stegen:
Se till att skapa en användartilldelad hanterad identitetsresurs på Azure-portalen. Mer information finns i Hantera användartilldelade hanterade identiteter
Tilldela den användartilldelade hanterade identiteten till din Azure-databas för PostgreSQL-resursen
I din Azure-databas för PostgreSQL-serverresursen under Säkerhet
Välj autentisering
Kontrollera om autentiseringsmetoden endast är Microsoft Entra-autentisering eller PostgreSQL- och Microsoft Entra-autentisering
Välj + Lägg till microsoft entra-administratörslänk och välj din användartilldelade hanterade identitet

Tilldela den användartilldelade hanterade identiteten till din Azure Data Factory-resurs
Välj Inställningar och sedan Hanterade identiteter
Under fliken Användartilldelade . Välj länken + Lägg till och välj din användarhanterade identitet

Konfigurera en ansluten Azure-databas för PostgreSQL-tjänst.


Exempel:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "<your credential>",
"type": "CredentialReference"
}
}
}
}
Tjänstens huvudautentisering
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| användarnamn | Visningsnamnet för tjänsthuvudmannen | Ja |
| hyresgäst | Hyresgästen där Azure-databasen för PostgreSQL-servern finns | Ja |
| tjänsthuvudId | Applikations-ID för tjänstehuvud | Ja |
| tjänstehuvudautentiseringstyp | Välj om certifikat för tjänsteprincip eller nyckel för tjänsteprincip ska användas som autentiseringsmetod. - ServicePrincipalCert: Ställ in på tjänstens huvudnamnscertifikat för tjänstens huvudnamnscertifikat. - ServicePrincipalKey: Ange till nyckeln för tjänstens huvudnamnsautentisering. |
Ja |
| servicePrincipalKey | Värdet på klienthemligheten. Används när tjänstens huvudnyckel har valts | Ja |
| azureCloudType | Välj Azure-molntypen för din Azure-databas för PostgreSQL-servern | Ja |
| servicePrincipalInbäddatCertifikat | Fil med certifikat för tjänsthuvudman | Ja |
| servicePrincipalInbäddadCertifikatLösenord | Certifikatlösenord för tjänstens huvudnamn om det behövs | Nej |
Exempel:
Nyckel för tjänstens huvudnamn
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalKey": "<service principal key>"
}
}
}
Exempel:
Service Principal-certifikat
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalEmbeddedCert": "<service principal certificate>",
"servicePrincipalEmbeddedCertPassword": "<service principal embedded certificate password>"
}
}
}
Anmärkning
Microsoft Entra ID-autentisering med tjänstehuvudnamn och användartilldelad hanterad identitet stöds på den självhostade integrationskörningsversionen 5.50 eller senare.
Version 1.0
Följande egenskaper stöds för den länkade tjänsten Azure Database for PostgreSQL när du tillämpar version 1.0:
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen måste anges till: AzurePostgreSql. | Ja |
| version | Den version som du anger Värdet är 1.0. |
Ja |
| anslutningssträng | En Npgsql-anslutningssträng för att ansluta till Azure Database for PostgreSQL. Du kan också placera ett lösenord i Azure Key Vault och hämta ut konfigurationen från password anslutningssträngen. Mer information finns i följande exempel och Lagra autentiseringsuppgifter i Azure Key Vault . |
Ja |
| connectVia | Den här egenskapen representerar den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
En typisk anslutningssträng är host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>. Här är fler egenskaper som du kan ange per ditt ärende:
| Fastighet | Beskrivning | Alternativ | Obligatoriskt |
|---|---|---|---|
| EncryptionMethod (EM) | Den metod som drivrutinen använder för att kryptera data som skickas mellan drivrutinen och databasservern. Till exempel: EncryptionMethod=<0/1/6>; |
0 (Ingen kryptering) (standard) / 1 (SSL) / 6 (RequestSSL) | Nej |
| ValidateServerCertificate (VSC) | Avgör om drivrutinen validerar certifikatet som skickas av databasservern när SSL-kryptering är aktiverat (krypteringsmetod=1). Till exempel: ValidateServerCertificate=<0/1>; |
0 (inaktiverad) (standard) /1 (aktiverad) | Nej |
Exempel:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>"
}
}
}
Exempel:
Lagra lösenord i Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Egenskaper för dataset
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i Datauppsättningar. Det här avsnittet innehåller en lista över egenskaper som Azure Database for PostgreSQL stöder i datauppsättningar.
Om du vill kopiera data från Azure Database for PostgreSQL anger du datauppsättningens typegenskap till AzurePostgreSqlTable. Följande egenskaper stöds:
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen för datamängden måste anges till AzurePostgreSqlTable. | Ja |
| Schemat | Namnet på schemat. | Nej (om "fråga" i aktivitetskällan har angetts) |
| bord/tabell | Namnet på tabellen/vyn. | Nej (om "fråga" i aktivitetskällan har angetts) |
| tabellnamn | Tabellens namn. Den här egenskapen stöds för bakåtkompatibilitet. För ny arbetsbelastning använder du schema och table. |
Nej (om "fråga" i aktivitetskällan har angetts) |
Exempel:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i Pipelines och aktiviteter. Det här avsnittet innehåller en lista över egenskaper som stöds av en Azure Database for PostgreSQL-källa.
Azure Database for PostgreSql som källa
Om du vill kopiera data från Azure Database for PostgreSQL anger du källtypen i kopieringsaktiviteten till AzurePostgreSqlSource. Följande egenskaper stöds i sektionen för kopieringsaktivitetens källa:
| Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen för kopieringsaktivitetskällan måste anges till AzurePostgreSqlSource | Ja |
| förfrågan | Använd den anpassade SQL-frågan för att läsa data. Till exempel: SELECT * FROM mytable eller SELECT * FROM "MyTable". Obs! I PostgreSQL behandlas entitetsnamnet som skiftlägesokänsligt om det inte anges. |
Nej (om egenskapen tableName i datauppsättningen har angetts) |
| förfråganTidsgräns | Den väntetid som standard används innan försöket att köra ett kommando avslutas och ett fel genereras är 120 minuter. Om parametern har angetts för den här egenskapen är tillåtna värden tidsintervall, till exempel "02:00:00" (120 minuter). Mer information finns i CommandTimeout. | Nej |
| partitioneringsalternativ | Anger de datapartitioneringsalternativ som används för att läsa in data från Azure SQL Database. Tillåtna värden är: Ingen (standard), PhysicalPartitionsOfTable och DynamicRange. När ett partitionsalternativ är aktiverat (dvs. inte None) styrs graden av parallellitet för samtidig inläsning av data från en Azure SQL Database av parallelCopies inställningen för kopieringsaktiviteten. |
Nej |
| partitionsinställningar | Ange gruppen med inställningarna för datapartitionering. Använd när partitionsalternativet inte är None. |
Nej |
Under partitionSettings: |
||
| partitionsnamn | Listan över fysiska partitioner som måste kopieras. Använd när partitionsalternativet är PhysicalPartitionsOfTable. Om du använder en fråga för att hämta källdata, koppla in ?AdfTabularPartitionName i WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL . |
Nej |
| partitionskolumnnamn | Ange namnet på källkolumnen i heltal eller datum/datetime-typ (int, , smallintbigint, date, timestamp without time zonetimestamp with time zone eller time without time zone) som ska användas av intervallpartitionering för parallell kopiering. Om den inte anges identifieras den primära nyckeln i tabellen automatiskt och används som partitionskolumn.Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata, koppla in ?AdfRangePartitionColumnName i WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL . |
Nej |
| partitionens övre gräns | Det maximala värdet för partitionskolumnen för att kopiera ut data. Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata, koppla in ?AdfRangePartitionUpbound i WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL . |
Nej |
| partitionens nedre gräns | Det minsta värdet för partitionskolumnen för att kopiera ut data. Använd när partitionsalternativet är DynamicRange. Om du använder en fråga för att hämta källdata, koppla in ?AdfRangePartitionLowbound i WHERE-satsen. Ett exempel finns i avsnittet Parallell kopia från Azure Database for PostgreSQL . |
Nej |
Exempel:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database för PostgreSQL som mottagare
Om du vill kopiera data till Azure Database for PostgreSQL anger du mottagartypen i kopieringsaktiviteten till SqlSink. Följande egenskaper stöds i avsnittet för kopieringsaktivitetens sänke:
| Fastighet | Beskrivning | Obligatoriskt | Anslutnings stödversion |
|---|---|---|---|
| typ | Typegenskapen för kopieringsaktivitetsmottagaren måste anges till AzurePostgreSQLSink. | Ja | Version 1.0 och version 2.0 |
| preCopyScript | Ange en SQL-fråga för kopieringsaktiviteten som ska köras innan du skriver data till Azure Database for PostgreSQL i varje körning. Du kan använda den här egenskapen för att rensa inlästa data. | Nej | Version 1.0 och version 2.0 |
| skrivMetod | Den metod som används för att skriva data till Azure Database for PostgreSQL. Tillåtna värden är: CopyCommand (standard, vilket är mer högpresterande), BulkInsert och Upsert (endast version 2.0). |
Nej | Version 1.0 och version 2.0 |
| upsertSettings | Ange gruppen med inställningarna för skrivbeteende. Använd när alternativet WriteBehavior är Upsert. |
Nej | Version 2.0 |
Under upsertSettings: |
|||
| nycklar | Ange kolumnnamnen för unik radidentifiering. Antingen kan en enskild nyckel eller en serie nycklar användas. Nycklar måste vara en primärnyckel eller en unik kolumn. Om den inte anges används primärnyckeln. | Nej | Version 2.0 |
| writeBatchSize | Antalet rader som läses in i Azure Database for PostgreSQL per batch. Tillåtet värde är ett heltal som representerar antalet rader. |
Nej (standardvärdet är 1 000 000) | Version 1.0 och version 2.0 |
| writeBatchTidsgräns | Väntetid för att batchinfogningsoperationen ska slutföras innan den avbryts. Tillåtna värden är tidsintervallsträngar. Ett exempel är 00:30:00 (30 minuter). |
Nej (standardvärdet är 00:30:00) | Version 1.0 och version 2.0 |
Exempel 1: Kopiera kommando
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSqlSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Exempel 2: Upsert-data
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"writeMethod": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
]
},
}
}
}
]
Infoga eller uppdatera data
Kopieringsaktivitet har inbyggt stöd för upsert-åtgärder. För att utföra en upsert bör användaren ange nyckelkolumner som antingen är primära nycklar eller unika kolumner. Om användaren inte tillhandahåller nyckelkolumner används de primära nyckelkolumnerna i mottagartabellen. Kopieringsaktiviteten kommer att uppdatera icke-nyckelkolumner i mottagartabellen där nyckelkolumnvärdena matchar de i källtabellen; annars kommer den att infoga nya data.
Parallell kopia från Azure Database for PostgreSQL
Azure Database for PostgreSQL-anslutningsappen i kopieringsaktiviteten tillhandahåller inbyggd datapartitionering för att kopiera data parallellt. Du hittar alternativ för datapartitionering på fliken Källa i kopieringsaktiviteten.
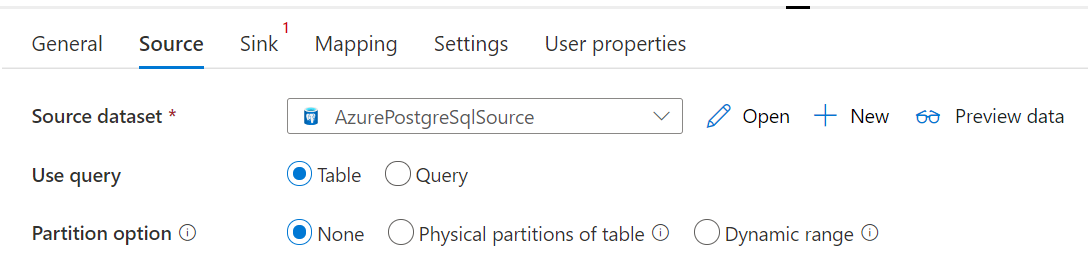
När du aktiverar partitionerad kopiering kör kopieringsaktiviteten parallella frågor mot din Azure Database for PostgreSQL-källa för att läsa in data efter partitioner. Den parallella graden styrs av parallelCopies inställningen för kopieringsaktiviteten. Om du till exempel anger parallelCopies till fyra genererar och kör tjänsten samtidigt fyra frågor baserat på det angivna partitionsalternativet och inställningarna, och varje fråga hämtar en del data från Azure Database for PostgreSQL.
Du rekommenderas att aktivera parallell kopiering med datapartitionering, särskilt när du läser in stora mängder data från din Azure Database for PostgreSQL. Följande är föreslagna konfigurationer för olika scenarier. När du kopierar data till filbaserat datalager är rekommendationen att skriva till en mapp som flera filer (ange endast mappnamn), i vilket fall prestandan är bättre än att skriva till en enda fil.
| Scenarie | Föreslagna inställningar |
|---|---|
| Fullständig lastning från en stor tabell med fysiska partitioner. |
Partitionsalternativ: Fysiska partitioner i tabellen. Under processen identifierar tjänsten automatiskt de fysiska partitionerna och kopierar data enligt partitioner. |
| Full belastning från en stor tabell, utan fysiska partitioner, men med en heltalskolumn för att partitionera data. |
Partitionsalternativ: Partition med dynamiskt intervall. Partitionskolumn: Ange den kolumn som används för att partitionera data. Om den inte anges används primärnyckelkolumnen. |
| Läs in en stor mängd data med hjälp av en anpassad fråga med fysiska partitioner. |
Partitionsalternativ: Fysiska partitioner i tabellen. Fråga: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Partitionsnamn: Ange ett eller flera partitionsnamn att kopiera data från. Om det inte anges identifierar tjänsten automatiskt de fysiska partitionerna i tabellen som du angav i PostgreSQL-datauppsättningen. Under körningen ersätter tjänsten ?AdfTabularPartitionName med det faktiska partitionsnamnet och skickar det till Azure Database for PostgreSQL. |
| Läs in en stor mängd data med hjälp av en anpassad fråga, utan fysiska partitioner, medan du har en heltalskolumn för datapartitionering. |
Partitionsalternativ: Partition med dynamiskt intervall. Fråga: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Partitionskolumn: Ange den kolumn som används för att partitionera data. Du kan partitionera på kolumnen med heltals- eller datum/datum-tid-datatyp. Partitionens övre gräns och partitionens nedre gräns: Ange om du vill filtrera mot partitionskolumnen för att hämta data endast mellan det nedre och det övre intervallet. Under körning ersätter tjänsten ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound och ?AdfRangePartitionLowbound med det faktiska kolumnnamnet och värdeintervallen för varje partition och skickar dem till Azure Database för PostgreSQL. Om till exempel partitionskolumnen "ID" har angetts med den nedre gränsen som 1 och den övre gränsen som 80, med parallell kopiering inställd som 4, hämtar tjänsten data med fyra partitioner. Deras ID:n är mellan [1,20], [21, 40], [41, 60] respektive [61, 80]. |
Metodtips för att läsa in data med partitionsalternativet:
- Välj distinkt kolumn som partitionskolumn (till exempel primärnyckel eller unik nyckel) för att undvika datasnedvridning.
- Om tabellen har inbyggd partition använder du partitionsalternativet "Fysiska partitioner av tabellen" för att få bättre prestanda.
- Om du använder Azure Integration Runtime för att kopiera data kan du ange större "Dataintegration Units (DIU)" (>4) för att använda mer databehandlingsresurser. Kontrollera tillämpliga scenarier där.
- "Grad av kopieringsparallellitet" styr partitionsnumren och att ange det här talet för stort skadar ibland prestandan. Vi rekommenderar att du anger det här talet som (DIU eller antal lokalt installerade IR-noder) * (2 till 4).
Exempel: fullständig belastning från en stor tabell med fysiska partitioner
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exempel: fråga med partition för dynamiskt intervall
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Mappa dataflödesegenskaper
När du transformerar data i dataflödet för mappning kan du läsa och skriva till tabeller från Azure Database for PostgreSQL. För mer information, se källtransformation och slutrörstransformation i kartläggningen av dataflöden. Du kan välja att använda en Azure Database for PostgreSQL-datauppsättning eller en infogad datauppsättning som käll- och mottagartyp.
Anmärkning
För närvarande stöds endast grundläggande autentisering för både V1- och V2-versioner av Azure Database for PostgreSQL-anslutningsappen i Mappa dataflöden.
Källomvandling
I tabellen nedan visas de egenskaper som stöds av Azure Database for PostgreSQL-källan. Du kan redigera dessa egenskaper på fliken Källalternativ .
| Namn | Beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Tabell | Om du väljer Tabell som indata hämtar dataflödet alla data från tabellen som anges i datauppsättningen. | Nej | - |
(endast för inbäddad datamängd) tabellnamn |
| Sökfråga | Om du väljer Fråga som indata anger du en SQL-fråga för att hämta data från källan, vilket åsidosätter alla tabeller som du anger i datauppsättningen. Att använda frågor är ett bra sätt att minska antalet rader för testning eller sökningar. Order By-satsen stöds inte, men du kan ange en fullständig SELECT FROM-instruktion. Du kan också använda användardefinierade tabellfunktioner. select * from udfGetData() är en UDF i SQL som returnerar en tabell som du kan använda i dataflödet. Frågeexempel: select * from mytable where customerId > 1000 and customerId < 2000 eller select * from "MyTable". Obs! I PostgreSQL behandlas entitetsnamnet som skiftlägesokänsligt om det inte anges. |
Nej | Sträng | förfrågan |
| Schemanamn | Om du väljer Lagrad procedur som indata anger du ett schemanamn för den lagrade proceduren eller väljer Uppdatera för att be tjänsten att identifiera schemanamnen. | Nej | Sträng | schemanamn |
| Lagrad procedur | Om du väljer Lagrad procedur som indata anger du ett namn på den lagrade proceduren för att läsa data från källtabellen eller väljer Uppdatera för att be tjänsten att identifiera procedurnamnen. | Ja (om du väljer Lagrad procedur som indata) | Sträng | procedurnamn |
| Parameterar för procedurer | Om du väljer Lagrad procedur som indata anger du eventuella indataparametrar för den lagrade proceduren i orderuppsättningen i proceduren eller väljer Importera för att importera alla procedureparametrar med hjälp av formuläret @paraName. |
Nej | Samling | Ingångar |
| Batchstorlek | Ange en batchstorlek för att segmentera stora data i batchar. | Nej | Heltal | batchstorlek |
| Isoleringsnivå | Välj någon av följande isoleringsnivåer: - Läs bekräftad – Läs ej bekräftad (standard) – Repeterbar läsning - Serialiserbar – Ingen (ignorera isoleringsnivå) |
Nej | READ_COMMITTED READ_UNCOMMITTED upprepningsbar läsning SERIALISERBAR INGEN |
isolationsnivå |
Exempel på Azure Database for PostgreSQL-källskript
När du använder Azure Database for PostgreSQL som källtyp är det associerade dataflödesskriptet:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Avloppsomvandling
Tabellen nedan listar de egenskaper som stöds av Azure Database för PostgreSQL-sink. Du kan redigera dessa egenskaper på fliken Alternativ för avsänkningspunkt.
| Namn | Beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Uppdatera metod | Ange vilka åtgärder som tillåts på databasmålet. Standardvärdet är att endast tillåta infogningar. För att uppdatera, öka eller ta bort rader krävs en Alter row-transformering för att tagga rader för dessa åtgärder. |
Ja |
true eller false |
kan tas bort insättbar kan uppdateras uppdateringsbar |
| Nyckelkolumner | För uppdateringar, upserts och borttagningar måste nyckelkolumner anges för att avgöra vilken rad som ska ändras. Kolumnnamnet som du väljer som nyckel används som en del av den efterföljande uppdateringen, införandet eller borttagandet. Därför måste du välja en kolumn som finns i Sink-mappningen. |
Nej | Samling | nycklar |
| Hoppa över att skriva nyckelkolumner | Om du inte vill skriva värdet till nyckelkolumnen väljer du "Hoppa över att skriva nyckelkolumner". | Nej |
true eller false |
skipKeyWrites |
| Åtgärd för tabell | Avgör om du vill återskapa eller ta bort alla rader från måltabellen innan du skriver. - Ingen: Ingen åtgärd utförs på tabellen. - Återskapa: Tabellen tas bort och återskapas. Krävs om du skapar en ny tabell dynamiskt. - Trunkera: Alla rader från måltabellen tas bort. |
Nej |
true eller false |
återskapa avkorta |
| Batchstorlek | Ange hur många rader som skrivs i varje batch. Större batchstorlekar förbättrar komprimering och minnesoptimering, men riskerar att orsaka minnesfel när data cachelagras. | Nej | Heltal | batchstorlek |
| Välj användar-DB-schema | Som standard skapas en tillfällig tabell under mottagarschemat som mellanlagring. Du kan också avmarkera alternativet Använd mottagarschema och i stället ange ett schemanamn under vilket Data Factory skapar en mellanlagringstabell för att läsa in överordnade data och automatiskt rensa dem när de är klara. Kontrollera att du har behörigheten skapa tabell i databasen och ändra behörigheten för schemat. | Nej | Sträng | stagingSchemaName |
| Pre- och Post SQL-skript | Ange flerlinjiga SQL-skript som ska köras före (förbearbetning) och efter (efterbearbetning) att data har skrivits till din mottagardatabas. | Nej | Sträng | preSQLs postSQLs |
Tips
- Dela upp enskilda batchskript med flera kommandon i flera batchar.
- Endast Data Definition Language (DDL) och Data Manipulation Language (DML) instruktioner som returnerar ett enkelt uppdateringsantal kan köras som en del av en batch. Läs mer om att utföra batchåtgärder
Aktivera inkrementell extrahering: Använd det här alternativet för att be ADF att endast bearbeta rader som ändrats sedan den senaste gången pipelinen kördes.
Inkrementell kolumn: När du använder funktionen för inkrementell extrahering måste du välja den datum/tid eller numeriska kolumn som du vill använda som vattenstämpel i källtabellen.
Börja läsa från början: Om du anger det här alternativet med inkrementellt extrahering instrueras ADF att läsa alla rader vid första körningen av en pipeline med inkrementellt extrahering aktiverat.
Azure Database för PostgreSQL exempel på "sink script"
När du använder Azure Database för PostgreSQL som förbrukartyp är det associerade dataflödesskriptet:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSqlSink
Skriptaktivitet
Viktigt!
Skriptaktivitet stöds endast i version 2.0-anslutningsappen.
Viktigt!
Flera frågeinstruktioner som använder utdataparametrar stöds inte. Vi rekommenderar att du delar upp utdatafrågor i separata skriptblock inom samma eller olika skriptaktivitet.
Flera frågeinstruktioner som använder positionsparametrar stöds inte. Vi rekommenderar att du delar upp eventuella positionsfrågor i separata skriptblock inom samma eller olika skriptaktivitet.
Mer information om skriptaktivitet finns i Skriptaktivitet.
Uppslagsaktivitetens egenskaper
Mer information om egenskaperna finns i Sökningsaktivitet.
Uppgradera Azure Database for PostgreSQL-anslutningen
På sidan Redigera länkad tjänst väljer du 2.0 under Version och konfigurerar den länkade tjänsten genom att referera till Länkade tjänstegenskaper version 2.0.
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i Datalager som stöds.