Få Azure-rekommendationer för att migrera din SQL Server-databas
Azure SQL Migration-tillägget för Azure Data Studio hjälper dig att utvärdera dina databaskrav, få rätt SKU-rekommendationer för Azure-resurser och migrera din SQL Server-databas till Azure.
Lär dig hur du använder den här enhetliga upplevelsen och samlar in prestandadata från din SQL Server-källinstans för att få rätt storlek på Azure-rekommendationer för dina Azure SQL-mål.
Innan du migrerar till Azure SQL kan du använda SQL Migration-tillägget i Azure Data Studio för att generera rekommendationer med rätt storlek för Azure SQL Database, Azure SQL Managed Instance och SQL Server på Azure Virtual Machines-mål. Verktyget hjälper dig att samla in prestandadata från din SQL-källinstans (som körs lokalt eller i annat moln) och rekommenderar en beräknings- och lagringskonfiguration för att uppfylla arbetsbelastningens behov.
Diagrammet visar arbetsflödet för Azure-rekommendationer i Azure SQL Migration-tillägget för Azure Data Studio:

Anteckning
Utvärdering och azure-rekommendationsfunktionen i Azure SQL Migration-tillägget för Azure Data Studio stöder SQL Server-källinstanser som körs i Windows eller Linux.
För att komma igång med Azure-rekommendationer för sql Server-databasmigreringen måste du uppfylla följande krav:
Installera Azure SQL Migration-tillägget från Azure Data Studio Marketplace.
Se till att inloggningen som du använder för att ansluta SQL Server-källinstansen har de lägsta behörigheterna.
Azure-rekommendationer kan genereras för följande SQL Server-versioner:
- SQL Server 2008 och senare versioner i Windows eller Linux stöds.
- SQL Server som körs i andra moln kan stödjas, men resultatens noggrannhet kan variera
Azure-rekommendationer kan genereras för följande Azure SQL-mål:
- Azure SQL Database
- Maskinvarufamiljer: Standard-serien (Gen5)
- Tjänstnivåer: Generell användning, Affärskritisk, Hyperskala
- Azure SQL Managed Instance
- Maskinvarufamiljer: Standard-serien (Gen5), Premium-serien, Premium-serien minnesoptimerad
- Tjänstnivåer: Generell användning, Affärskritisk
- SQL Server på en virtuell Azure-dator
- VM-familjer: Generell användning, minnesoptimerad
- Lagringsfamiljer: Premium SSD
Innan rekommendationer kan genereras måste prestandadata samlas in från SQL Server-källinstansen. Under det här datainsamlingssteget efterfrågas flera dynamiska systemvyer (DMV:er) från din SQL Server-instans för att samla in prestandaegenskaperna för din arbetsbelastning. Verktyget samlar in mått som CPU, minne, lagring och I/O-användning var 30:e sekund och sparar prestandaräknarna lokalt på datorn som en uppsättning CSV-filer.
Dessa prestandadata samlas in en gång per SQL Server-instans:
| Prestandadimension | beskrivning | Dynamisk hanteringsvy (DMV) |
|---|---|---|
SqlInstanceCpuPercent |
Mängden CPU som SQL Server-processen använde i procent | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Övergripande minnesfotavtryck för SQL Server-processen | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
SQL Server-minnesanvändning | sys.dm_os_process_memory |
| Prestandadimension | beskrivning | Dynamisk hanteringsvy (DMV) |
|---|---|---|
DatabaseCpuPercent |
Den totala procentandelen cpu som används av en databas | sys.dm_exec_query_stats |
CachedSizeInMb |
Total storlek i megabyte cache som används av en databas | sys.dm_os_buffer_descriptors |
| Prestandadimension | beskrivning | Dynamisk hanteringsvy (DMV) |
|---|---|---|
ReadIOInMb |
Det totala antalet mb som lästs från den här filen | sys.dm_io_virtual_file_stats |
WriteIOInMb |
Det totala antalet megabyte som skrivits till den här filen | sys.dm_io_virtual_file_stats |
NumOfReads |
Det totala antalet läsningar som utfärdats för den här filen | sys.dm_io_virtual_file_stats |
NumOfWrites |
Det totala antalet skrivningar som utfärdats för den här filen | sys.dm_io_virtual_file_stats |
ReadLatency |
I/O-svarstiden för den här filen | sys.dm_io_virtual_file_stats |
WriteLatency |
I/O-skrivfördröjningen för den här filen | sys.dm_io_virtual_file_stats |
Minst 10 minuters datainsamling krävs innan en rekommendation kan genereras, men för att kunna utvärdera din arbetsbelastning korrekt rekommenderar vi att du kör datainsamlingen under en tillräckligt lång tid för att samla in både användning med hög belastning och låg belastning.
Om du vill initiera datainsamlingsprocessen börjar du med att ansluta till sql-källinstansen i Azure Data Studio och sedan starta sql-migreringsguiden. I steg 2 väljer du "Hämta Azure-rekommendation". Välj "Samla in prestandadata nu" och välj en mapp på datorn där insamlade data ska sparas.
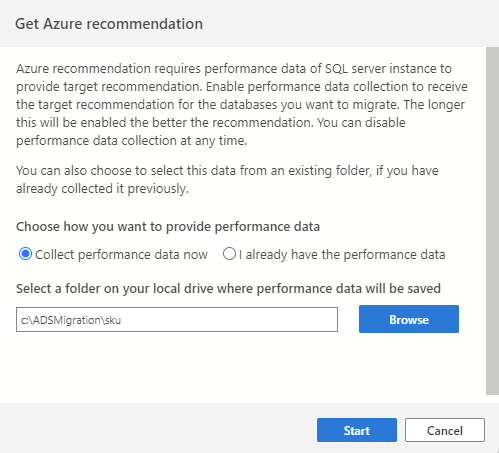
Datainsamlingsprocessen körs i 10 minuter för att generera den första rekommendationen. Det är viktigt att starta datainsamlingsprocessen när din aktiva databasarbetsbelastning återspeglar användning som liknar dina produktionsscenarier.
När den första rekommendationen har genererats kan du fortsätta att köra datainsamlingsprocessen för att förfina rekommendationerna. Det här alternativet är särskilt användbart om användningsmönstren varierar över tid.
Datainsamlingsprocessen börjar när du väljer Starta. Var 10:e minut aggregeras de insamlade datapunkterna och maxvärdet, medelvärdet och variansen för varje räknare skrivs till disken till en uppsättning med tre CSV-filer.
Du ser vanligtvis en uppsättning CSV-filer med följande suffix i den valda mappen:
SQLServerInstance_CommonDbLevel_Counters.csv: Innehåller statiska konfigurationsdata om databasfillayouten och metadata.SQLServerInstance_CommonInstanceLevel_Counters.csv: Innehåller statiska data om maskinvarukonfigurationen för serverinstansen.SQLServerInstance_PerformanceAggregated_Counters.csv: Innehåller aggregerade prestandadata som uppdateras ofta.
Under den här tiden lämnar du Azure Data Studio öppet, men du kan fortsätta med andra åtgärder. När som helst kan du stoppa datainsamlingsprocessen genom att gå tillbaka till den här sidan och välja Stoppa datainsamling.
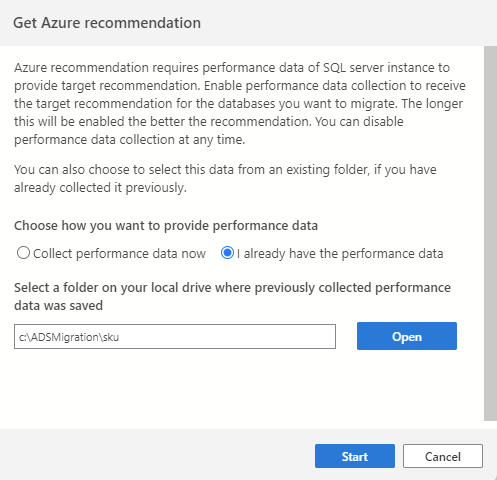
Om du redan har samlat in prestandadata från en tidigare session eller använder ett annat verktyg (till exempel Database Migration Assistant) kan du importera befintliga prestandadata genom att välja alternativet Jag har redan prestandadata. Fortsätt för att välja den mapp där dina prestandadata (tre .csv filer) sparas och välj Starta för att starta rekommendationsprocessen.
Steg ett i sql-migreringsguiden ber dig att välja en uppsättning databaser att utvärdera, och dessa är de enda databaser som kommer att beaktas under rekommendationsprocessen.
Processen för insamling av prestandadata samlar dock in prestandaräknare för alla databaser från SQL Server-källinstansen, inte bara de som har valts.
Det innebär att tidigare insamlade prestandadata kan användas för att återskapa rekommendationer upprepade gånger för en annan delmängd av databaser genom att ange en annan lista i steg ett.
Det finns flera konfigurerbara inställningar som kan påverka dina rekommendationer.

Välj alternativet Redigera parametrar för att justera dessa parametrar efter dina behov.
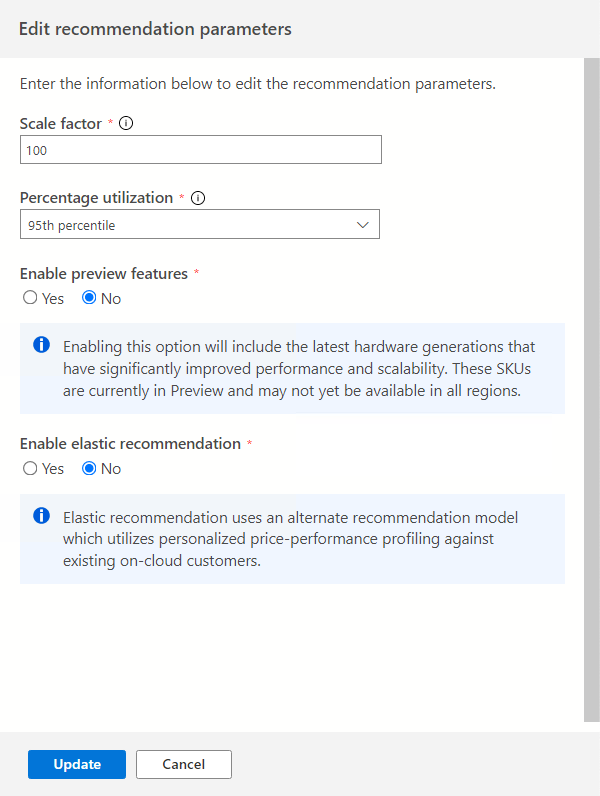
Skalningsfaktor:
Med det här alternativet kan du ange en buffert som ska tillämpas på varje prestandadimension. Det här alternativet står för problem som säsongsanvändning, kort prestandahistorik och sannolikt ökningar i framtida användning. Om du till exempel fastställer att ett cpu-krav på fyra virtuella kärnor har en skalningsfaktor på 150 %, är det verkliga CPU-kravet sex virtuella kärnor.
Standardvolymen för skalningsfaktorn är 100 %.
Procentuell användning:
Percentilen av datapunkter som ska användas när prestandadata aggregeras.
Standardvärdet är den 95:e percentilen.
Aktivera förhandsgranskningsfunktioner:
Med det här alternativet kan konfigurationer rekommenderas som kanske inte är allmänt tillgängliga för alla användare i alla regioner ännu.
Det här alternativet är inaktiverat som standard.
Aktivera elastisk rekommendation:
Det här alternativet använder en alternativ rekommendationsmodell som använder anpassad prisprestandaprofilering mot befintliga kunder i molnet.
Det här alternativet är inaktiverat som standard.
Datainsamlingsprocessen avslutas om du stänger Azure Data Studio. De data som har samlats in fram till den tidpunkten sparas i mappen.
Om du stänger Azure Data Studio medan datainsamling pågår använder du något av följande alternativ för att starta om datainsamlingen:
Öppna Azure Data Studio igen och importera de datafiler som sparas i din lokala mapp. Generera sedan en rekommendation från de insamlade data.
Öppna Azure Data Studio igen och starta datainsamlingen igen med hjälp av migreringsguiden.
För att köra frågor mot nödvändiga systemvyer för insamling av prestandadata krävs specifika behörigheter för SQL Server-inloggningen som används för den här uppgiften. Du kan skapa en lägsta privilegierad användare för insamling av utvärderings- och prestandadata med hjälp av följande skript:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Azure-rekommendationer inkluderar inte prisuppskattningar eftersom den här situationen kan variera beroende på region, valuta och rabatter, till exempel Azure Hybrid-förmån. Om du vill hämta prisuppskattningar använder du Priskalkylatorn för Azure eller skapar en SQL-utvärdering i Azure Migrate.
Rekommendationer för Azure SQL Database med den DTU-baserade inköpsmodellen stöds inte.
För närvarande stöds inte Azure-rekommendationer för serverlös beräkningsnivå i Azure SQL Database och elastiska pooler.
- Inga rekommendationer har genererats
- Om inga rekommendationer genererades kan den här situationen innebära att inga konfigurationer identifierades som helt kan uppfylla prestandakraven för källinstansen. För att se varför en viss storlek, tjänstnivå eller maskinvarufamilj diskvalificerades:
- Få åtkomst till loggarna från Azure Data Studio genom att gå till Hjälp > Visa alla kommandon Öppna tilläggsloggmapp >
- Gå till Microsoft.mssql > SqlAssessmentLogs > öppna SkuRecommendationEvent.log
- Loggen innehåller en spårning av varje potentiell konfiguration som utvärderades och orsaken till att den ansågs vara en berättigad konfiguration:
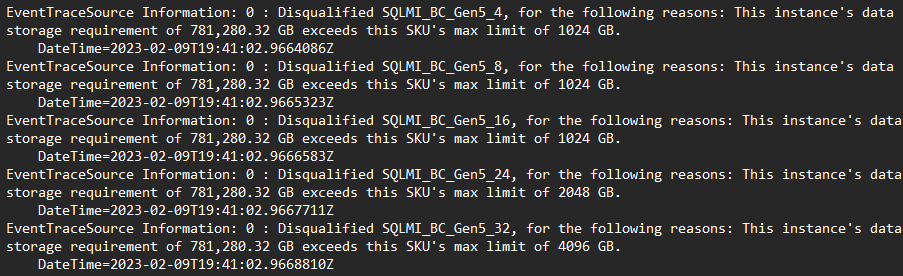
- Prova att återskapa rekommendationen med elastisk rekommendation aktiverad. Det här alternativet använder en alternativ rekommendationsmodell som använder anpassad prisprestandaprofilering mot befintliga kunder i molnet.
- Om inga rekommendationer genererades kan den här situationen innebära att inga konfigurationer identifierades som helt kan uppfylla prestandakraven för källinstansen. För att se varför en viss storlek, tjänstnivå eller maskinvarufamilj diskvalificerades:
