Pipelines and activities in Azure Data Factory and Azure Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Important
Support for Azure Machine Learning Studio (classic) will end on August 31, 2024. We recommend that you transition to Azure Machine Learning by that date.
As of December 1, 2021, you can't create new Machine Learning Studio (classic) resources (workspace and web service plan). Through August 31, 2024, you can continue to use the existing Machine Learning Studio (classic) experiments and web services. For more information, see:
- Migrate to Azure Machine Learning from Machine Learning Studio (classic)
- What is Azure Machine Learning?
Machine Learning Studio (classic) documentation is being retired and might not be updated in the future.
This article helps you understand pipelines and activities in Azure Data Factory and Azure Synapse Analytics and use them to construct end-to-end data-driven workflows for your data movement and data processing scenarios.
Overview
A Data Factory or Synapse Workspace can have one or more pipelines. A pipeline is a logical grouping of activities that together perform a task. For example, a pipeline could contain a set of activities that ingest and clean log data, and then kick off a mapping data flow to analyze the log data. The pipeline allows you to manage the activities as a set instead of each one individually. You deploy and schedule the pipeline instead of the activities independently.
The activities in a pipeline define actions to perform on your data. For example, you can use a copy activity to copy data from SQL Server to an Azure Blob Storage. Then, use a data flow activity or a Databricks Notebook activity to process and transform data from the blob storage to an Azure Synapse Analytics pool on top of which business intelligence reporting solutions are built.
Azure Data Factory and Azure Synapse Analytics have three groupings of activities: data movement activities, data transformation activities, and control activities. An activity can take zero or more input datasets and produce one or more output datasets. The following diagram shows the relationship between pipeline, activity, and dataset:

An input dataset represents the input for an activity in the pipeline, and an output dataset represents the output for the activity. Datasets identify data within different data stores, such as tables, files, folders, and documents. After you create a dataset, you can use it with activities in a pipeline. For example, a dataset can be an input/output dataset of a Copy Activity or an HDInsightHive Activity. For more information about datasets, see Datasets in Azure Data Factory article.
Note
There's a default soft limit of maximum 80 activities per pipeline, which includes inner activities for containers.
Data movement activities
Copy Activity in Data Factory copies data from a source data store to a sink data store. Data Factory supports the data stores listed in the table in this section. Data from any source can be written to any sink.
For more information, see Copy Activity - Overview article.
Select a data store to learn how to copy data to and from that store.
Note
If a connector is marked Preview, you can try it out and give us feedback. If you want to take a dependency on preview connectors in your solution, contact Azure support.
Data transformation activities
Azure Data Factory and Azure Synapse Analytics support the following transformation activities that can be added either individually or chained with another activity.
For more information, see the data transformation activities article.
| Data transformation activity | Compute environment |
|---|---|
| Data Flow | Apache Spark clusters managed by Azure Data Factory |
| Azure Function | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop Streaming | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| ML Studio (classic) activities: Batch Execution and Update Resource | Azure VM |
| Stored Procedure | Azure SQL, Azure Synapse Analytics, or SQL Server |
| U-SQL | Azure Data Lake Analytics |
| Custom Activity | Azure Batch |
| Databricks Notebook | Azure Databricks |
| Databricks Jar Activity | Azure Databricks |
| Databricks Python Activity | Azure Databricks |
| Synapse Notebook Activity | Azure Synapse Analytics |
Control flow activities
The following control flow activities are supported:
| Control activity | Description |
|---|---|
| Append Variable | Add a value to an existing array variable. |
| Execute Pipeline | Execute Pipeline activity allows a Data Factory or Synapse pipeline to invoke another pipeline. |
| Filter | Apply a filter expression to an input array |
| For Each | ForEach Activity defines a repeating control flow in your pipeline. This activity is used to iterate over a collection and executes specified activities in a loop. The loop implementation of this activity is similar to the Foreach looping structure in programming languages. |
| Get Metadata | GetMetadata activity can be used to retrieve metadata of any data in a Data Factory or Synapse pipeline. |
| If Condition Activity | The If Condition can be used to branch based on condition that evaluates to true or false. The If Condition activity provides the same functionality that an if statement provides in programming languages. It evaluates a set of activities when the condition evaluates to true and another set of activities when the condition evaluates to false. |
| Lookup Activity | Lookup Activity can be used to read or look up a record/ table name/ value from any external source. This output can further be referenced by succeeding activities. |
| Set Variable | Set the value of an existing variable. |
| Until Activity | Implements Do-Until loop that is similar to Do-Until looping structure in programming languages. It executes a set of activities in a loop until the condition associated with the activity evaluates to true. You can specify a time-out value for the until activity. |
| Validation Activity | Ensure a pipeline only continues execution if a reference dataset exists, meets a specified criteria, or a time-out is reached. |
| Wait Activity | When you use a Wait activity in a pipeline, the pipeline waits for the specified time before continuing with execution of subsequent activities. |
| Web Activity | Web Activity can be used to call a custom REST endpoint from a pipeline. You can pass datasets and linked services to be consumed and accessed by the activity. |
| Webhook Activity | Using the webhook activity, call an endpoint, and pass a callback URL. The pipeline run waits for the callback to be invoked before proceeding to the next activity. |
Creating a pipeline with UI
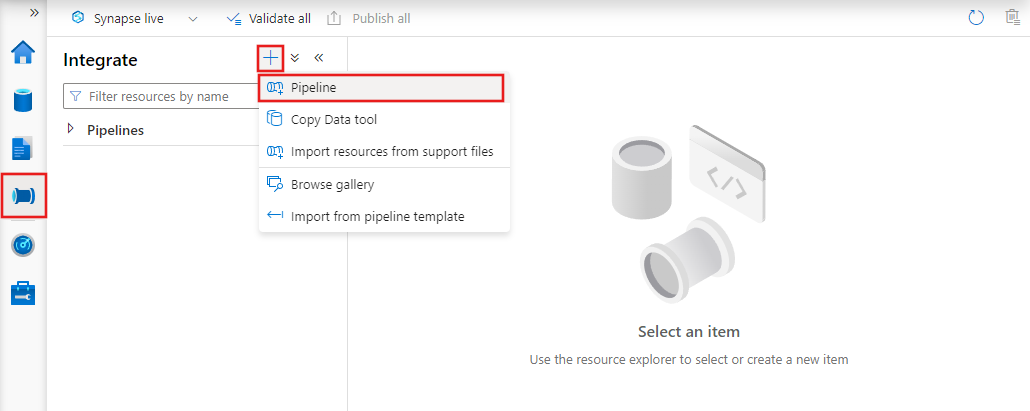
To create a new pipeline, navigate to the Author tab in Data Factory Studio (represented by the pencil icon), then select the plus sign and choose Pipeline from the menu, and Pipeline again from the submenu.
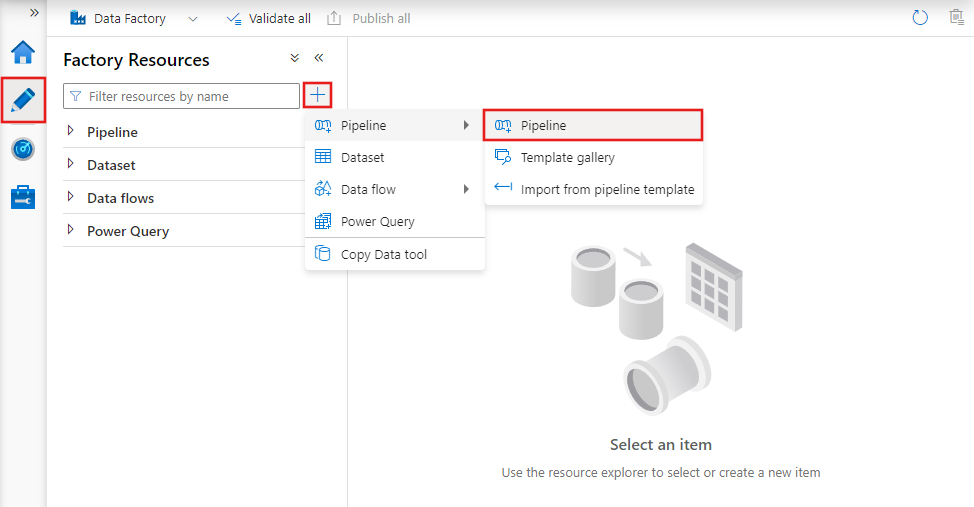
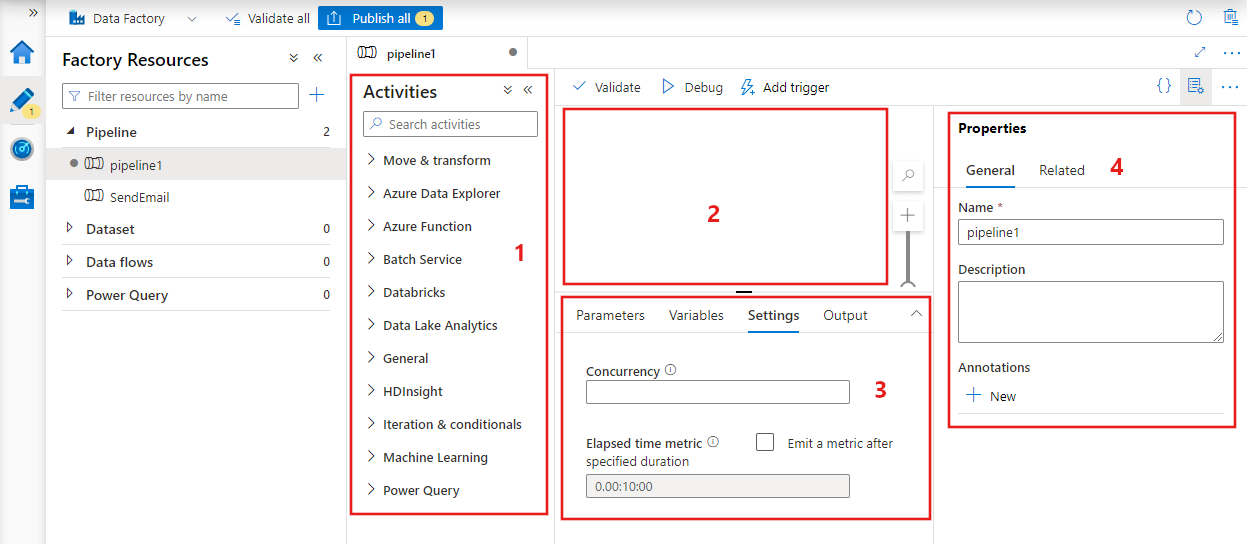
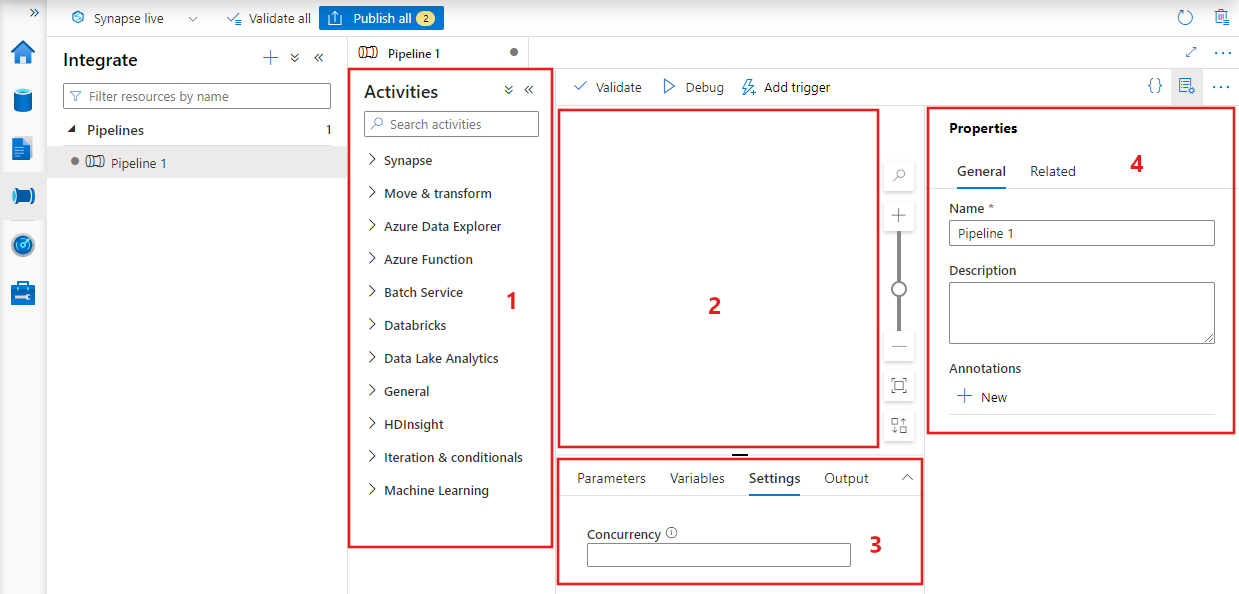
Data factory displays the pipeline editor where you can find:
- All activities that can be used within the pipeline.
- The pipeline editor canvas, where activities appear when added to the pipeline.
- The pipeline configurations pane, including parameters, variables, general settings, and output.
- The pipeline properties pane, where the pipeline name, optional description, and annotations can be configured. This pane also shows any related items to the pipeline within the data factory.
Pipeline JSON
Here's how a pipeline is defined in JSON format:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Tag | Description | Type | Required |
|---|---|---|---|
| name | Name of the pipeline. Specify a name that represents the action that the pipeline performs.
|
String | Yes |
| description | Specify the text describing what the pipeline is used for. | String | No |
| activities | The activities section can have one or more activities defined within it. See the Activity JSON section for details about the activities JSON element. | Array | Yes |
| parameters | The parameters section can have one or more parameters defined within the pipeline, making your pipeline flexible for reuse. | List | No |
| concurrency | The maximum number of concurrent runs the pipeline can have. By default, there's no maximum. If the concurrency limit is reached, extra pipeline runs are queued until earlier ones complete | Number | No |
| annotations | A list of tags associated with the pipeline | Array | No |
Activity JSON
The activities section can have one or more activities defined within it. There are two main types of activities: Execution and Control Activities.
Execution activities
Execution activities include data movement and data transformation activities. They have the following top-level structure:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
Following table describes properties in the activity JSON definition:
| Tag | Description | Required |
|---|---|---|
| name | Name of the activity. Specify a name that represents the action that the activity performs.
|
Yes |
| description | Text describing what the activity or is used for | Yes |
| type | Type of the activity. See the Data Movement Activities, Data Transformation Activities, and Control Activities sections for different types of activities. | Yes |
| linkedServiceName | Name of the linked service used by the activity. An activity might require that you specify the linked service that links to the required compute environment. |
Yes for HDInsight Activity, ML Studio (classic) Batch Scoring Activity, Stored Procedure Activity. No for all others |
| typeProperties | Properties in the typeProperties section depend on each type of activity. To see type properties for an activity, select links to the activity in the previous section. | No |
| policy | Policies that affect the run-time behavior of the activity. This property includes a time-out and retry behavior. If it isn't specified, default values are used. For more information, see Activity policy section. | No |
| dependsOn | This property is used to define activity dependencies, and how subsequent activities depend on previous activities. For more information, see Activity dependency | No |
Activity policy
Policies affect the run-time behavior of an activity, giving configuration options. Activity Policies are only available for execution activities.
Activity policy JSON definition
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| JSON name | Description | Allowed Values | Required |
|---|---|---|---|
| timeout | Specifies the time-out for the activity to run. | Timespan | No. Default time-out is 12 hours, minimum 10 minutes. |
| retry | Maximum retry attempts | Integer | No. Default is 0 |
| retryIntervalInSeconds | The delay between retry attempts in seconds | Integer | No. Default is 30 seconds |
| secureOutput | When set to true, the output from activity is considered as secure and aren't logged for monitoring. | Boolean | No. Default is false. |
Control activity
Control activities have the following top-level structure:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Tag | Description | Required |
|---|---|---|
| name | Name of the activity. Specify a name that represents the action that the activity performs.
|
Yes |
| description | Text describing what the activity or is used for | Yes |
| type | Type of the activity. See the data movement activities, data transformation activities, and control activities sections for different types of activities. | Yes |
| typeProperties | Properties in the typeProperties section depend on each type of activity. To see type properties for an activity, select links to the activity in the previous section. | No |
| dependsOn | This property is used to define Activity Dependency, and how subsequent activities depend on previous activities. For more information, see activity dependency. | No |
Activity dependency
Activity Dependency defines how subsequent activities depend on previous activities, determining the condition of whether to continue executing the next task. An activity can depend on one or multiple previous activities with different dependency conditions.
The different dependency conditions are: Succeeded, Failed, Skipped, Completed.
For example, if a pipeline has Activity A -> Activity B, the different scenarios that can happen are:
- Activity B has dependency condition on Activity A with succeeded: Activity B only runs if Activity A has a final status of succeeded
- Activity B has dependency condition on Activity A with failed: Activity B only runs if Activity A has a final status of failed
- Activity B has dependency condition on Activity A with completed: Activity B runs if Activity A has a final status of succeeded or failed
- Activity B has a dependency condition on Activity A with skipped: Activity B runs if Activity A has a final status of skipped. Skipped occurs in the scenario of Activity X -> Activity Y -> Activity Z, where each activity runs only if the previous activity succeeds. If Activity X fails, then Activity Y has a status of "Skipped" because it never executes. Similarly, Activity Z has a status of "Skipped" as well.
Example: Activity 2 depends on the Activity 1 succeeding
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Sample copy pipeline
In the following sample pipeline, there's one activity of type Copy in the activities section. In this sample, the copy activity copies data from an Azure Blob storage to a database in Azure SQL Database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Note the following points:
- In the activities section, there's only one activity whose type is set to Copy.
- Input for the activity is set to InputDataset and output for the activity is set to OutputDataset. See Datasets article for defining datasets in JSON.
- In the typeProperties section, BlobSource is specified as the source type and SqlSink is specified as the sink type. In the data movement activities section, select the data store that you want to use as a source or a sink to learn more about moving data to/from that data store.
For a complete walkthrough of creating this pipeline, see Quickstart: create a Data Factory.
Sample transformation pipeline
In the following sample pipeline, there's one activity of type HDInsightHive in the activities section. In this sample, the HDInsight Hive activity transforms data from an Azure Blob storage by running a Hive script file on an Azure HDInsight Hadoop cluster.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Note the following points:
- In the activities section, there's only one activity whose type is set to HDInsightHive.
- The Hive script file, partitionweblogs.hql, is stored in the Azure Storage account (specified by the scriptLinkedService, called AzureStorageLinkedService), and in script folder in the container
adfgetstarted. - The
definessection is used to specify the runtime settings that are passed to the hive script as Hive configuration values (for example, ${hiveconf:inputtable},${hiveconf:partitionedtable}).
The typeProperties section is different for each transformation activity. To learn about type properties supported for a transformation activity, select the transformation activity in the Data transformation activities.
For a complete walkthrough of creating this pipeline, see Tutorial: transform data using Spark.
Multiple activities in a pipeline
The previous two sample pipelines have only one activity in them. You can have more than one activity in a pipeline. If you have multiple activities in a pipeline and subsequent activities aren't dependent on previous activities, the activities might run in parallel.
You can chain two activities by using activity dependency, which defines how subsequent activities depend on previous activities, determining the condition whether to continue executing the next task. An activity can depend on one or more previous activities with different dependency conditions.
Scheduling pipelines
Pipelines are scheduled by triggers. There are different types of triggers (Scheduler trigger, which allows pipelines to be triggered on a wall-clock schedule, and the manual trigger, which triggers pipelines on-demand). For more information about triggers, see pipeline execution and triggers article.
To have your trigger kick off a pipeline run, you must include a pipeline reference of the particular pipeline in the trigger definition. Pipelines & triggers have an n-m relationship. Multiple triggers can kick off a single pipeline, and the same trigger can kick off multiple pipelines. Once the trigger is defined, you must start the trigger to have it start triggering the pipeline. For more information about triggers, see pipeline execution and triggers article.
For example, say you have a Scheduler trigger, "Trigger A," that I wish to kick off my pipeline, "MyCopyPipeline." You define the trigger, as shown in the following example:
Trigger A definition
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}