استخدام Azure Toolkit for Eclipse لإنشاء تطبيقات Apache Spark لنظام مجموعة HDInsight
استخدام HDInsight Tools في Azure Toolkit for Eclipse لتطوير تطبيقات Apache Spark المكتوبة في Scala وإرسالها إلى نظام مجموعة Azure HDInsight Spark، مباشرة من Eclipse IDE. يمكنك استخدام المكون الإضافي HDInsight Tools بعدة طرق مختلفة:
- لتطوير تطبيق Scala Spark وإرساله في نظام مجموعة HDInsight Spark.
- للوصول إلى موارد نظام مجموعة Azure HDInsight Spark.
- لتطوير تطبيق Scala Spark وتشغيله محليًا.
المتطلبات الأساسية
نظام مجموعة Apache Spark على HDInsight. للحصول على إرشادات، يرجى مراجعة إنشاء مجموعات Apache Spark في Azure HDInsight.
Eclipse IDE. تستخدم هذه المقالة Eclipse IDE for Java Developers.
تثبيت المكونات الإضافية المطلوبة
ثبت Azure Toolkit لـ Eclipse.
للحصول على إرشادات التثبيت، راجع تثبيت Azure Toolkit for Eclipse.
تثبيت المكون الإضافي Scala
عند فتح Eclipse، يكتشف HDInsight Tools تلقائيًا ما إذا كنت قد قمت بتثبيت المكون الإضافي Scala. حدد موافق للمتابعة، ثم اتبع الإرشادات لتثبيت المكون الإضافي من Eclipse Marketplace. أعد تشغيل IDE بعد اكتمال التثبيت.
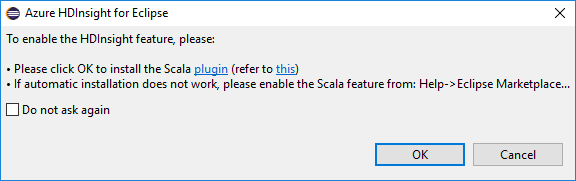
تأكيد المكونات الإضافية
انتقل إلى التعليمات>Eclipse Marketplace....
حدد علامة التبويب مثبّت.
من المفترض أن ترى على الأقل ما يلي:
- <إصدار> Azure Toolkit for Eclipse.
- <إصدار> Scala IDE.
تسجيل الدخول إلى اشتراك Azure الخاص بك
قم بتشغيل Eclipse IDE.
انتقل إلى نافذة>طريقة العرض>أخرى...>تسجيل الدخول...
من مربع الحوار طريقة العرض، انتقل إلى Azure>Azure Explorer، ثم حدد فتح.
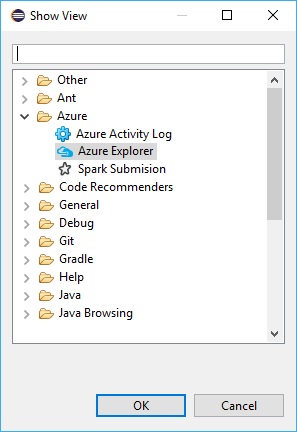
من Azure Explorer، انقر بزر الماوس الأيمن فوق عقدة Azure، ثم حدد تسجيل الدخول.
في مربع الحوار تسجيل الدخول إلى Azure، اختر طريقة المصادقة، وحدد تسجيل الدخول، وأكمل عملية تسجيل الدخول.
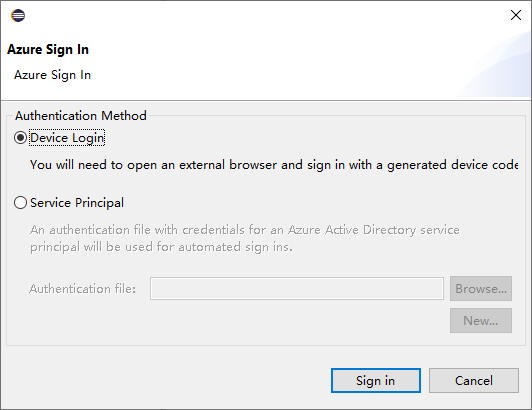
بعد تسجيل الدخول، يسرد مربع الحوار اشتراكاتك جميع اشتراكات Azure المقترنة ببيانات الاعتماد. اضغط على تحديد لإغلاق مربع الحوار.
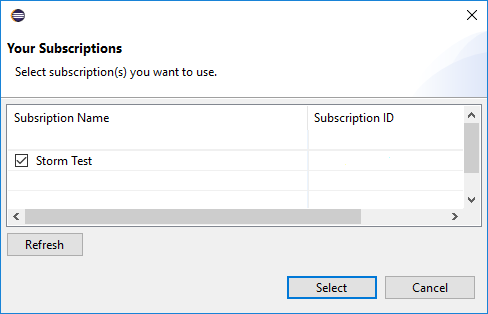
من Azure Explorer، انتقل إلى Azure>HDInsight للاطلاع على أنظمة مجموعات HDInsight Spark ضمن اشتراكك.
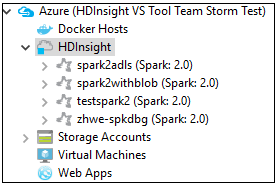
يمكنك أيضًا توسيع عقدة اسم نظام المجموعة للاطلاع على الموارد (على سبيل المثال، حسابات التخزين) المقترنة بنظام المجموعة.
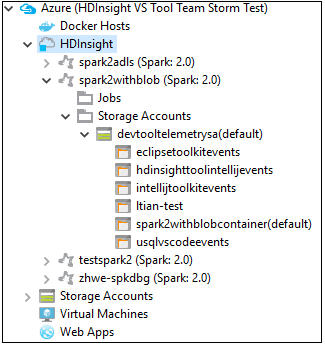
ربط النظام
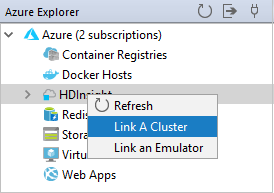
يمكنك ربط نظام مجموعة عادي باستخدام اسم المستخدم المُدار بواسطة Ambari. وبالمثل، بالنسبة لنظام مجموعة HDInsight المُنضم إلى المجال، يمكنك الربط باستخدام المجال واسم المستخدم، مثل user1@contoso.com.
من Azure Explorer، انقر بزر الماوس الأيمن فوق HDInsight، وحدد ربط نظام مجموعة.
أدخل اسم نظام المجموعة، واسم المستخدم، وكلمة المرور، ثم حدد موافق. اختياريًا، أدخل حساب التخزين، ومفتاح التخزين، ثم حدد حاوية التخزين لمستكشف التخزين للعمل في العرض الشجري على اليسار
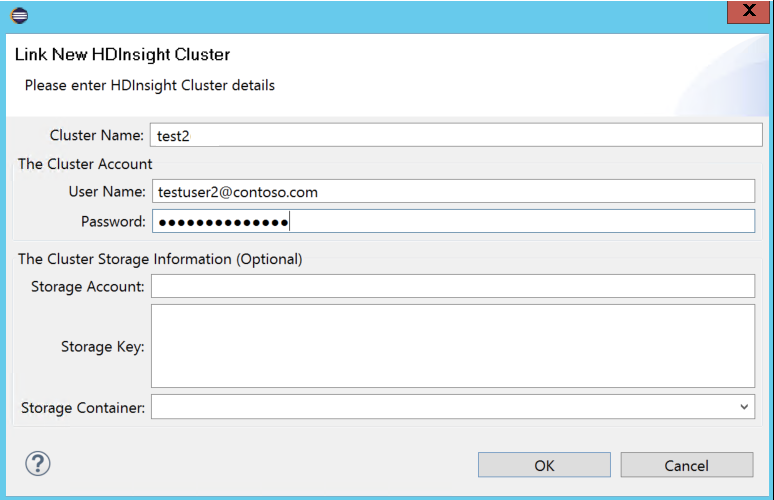
إشعار
نستخدم مفتاح التخزين المرتبط، واسم المستخدم، وكلمة المرور إذا قام نظام المجموعة بتسجيل الدخول إلى اشتراك Azure وربط نظام مجموعة.
بالنسبة لمستخدم لوحة المفاتيح فقط، عندما يكون التركيز الحالي على مفتاح التخزين، تحتاج إلى استخدام Ctrl+TAB للتركيز على الحقل التالي في مربع الحوار.
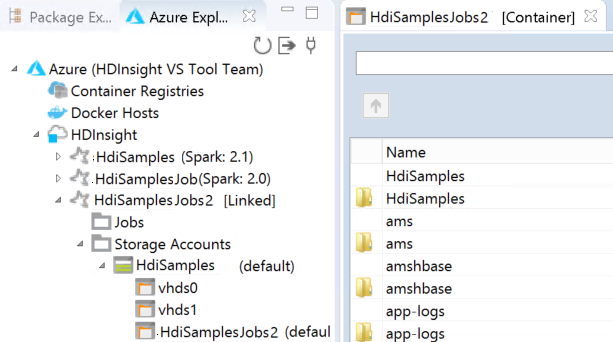
يمكنك رؤية نظام المجموعة المرتبط تحت HDInsight. الآن يمكنك إرسال تطبيق إلى نظام المجموعة المرتبط هذا.
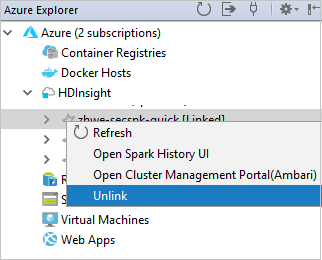
يمكنك أيضاً إلغاء ارتباط نظام من مستكشف Azure.
إعداد مشروع Spark Scala لنظام مجموعة HDInsight Spark
من مساحة عمل Eclipse IDE، حدد ملف>جديد>مشروع....
في معالج مشروع جديد، حدد مشروع HDInsight>Spark on HDInsight (Scala). بعد ذلك حدد التالي.
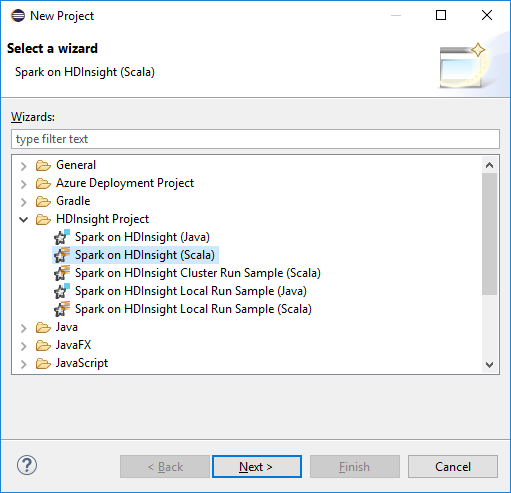
في مربع الحوار مشروع HDInsight Scala جديد، قم بتوفير القيم التالية، ثم حدد التالي:
- أدخل اسمًا للمشروع.
- في منطقة JRE، تأكد من تعيين استخدام بيئة تنفيذ JRE إلى JavaSE-1.7 أو إصدار أحدث.
- في منطقة مكتبة Spark، يمكنك اختيار خيار استخدام Maven لتكوين Spark SDK. تقوم أداتنا بدمج الإصدار المناسب لـ Spark SDK وScala SDK. يمكنك أيضًا اختيار خيار إضافة Spark SDK يدويًا، وتنزيل وإضافة Spark SDK يدويًا.
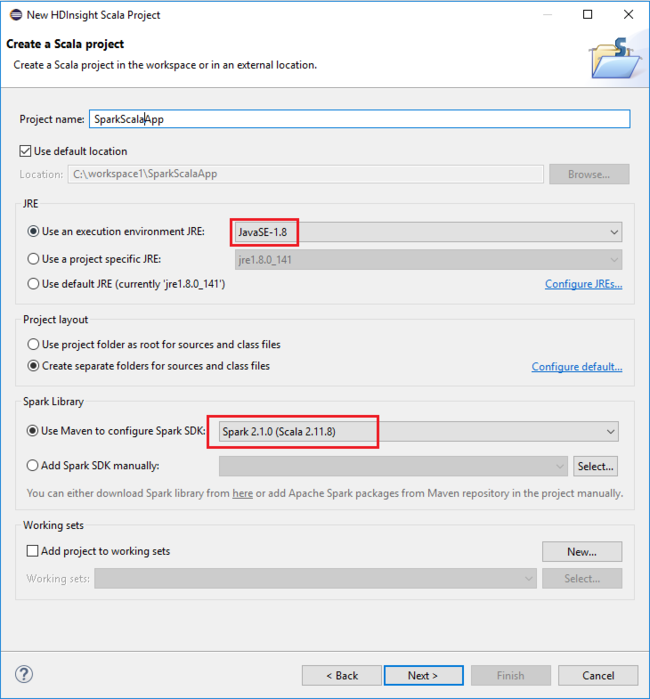
في مربع الحوار التالي، راجع التفاصيل، ثم حدد إنهاء.
إنشاء تطبيق Scala لنظام مجموعة HDInsight Spark
من Package Explorer، قم بتوسيع المشروع الذي قمت بإنشائه مسبقًا. انقر بزر الماوس الأيمن فوق src، وحدد جديد>أخرى....
في مربع الحوار تحديد معالج، حدد معالجات Scala>مشروع Scala. بعد ذلك حدد التالي.
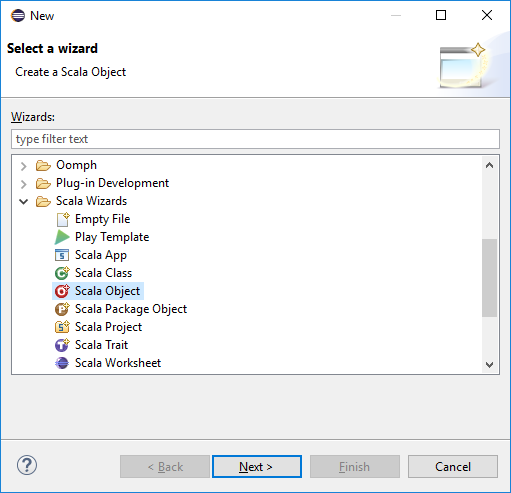
في مربع الحوار إنشاء ملف جديد، أدخل اسمًا للعنصر، ثم حدد إنهاء. سيتم فتح محرر نص.
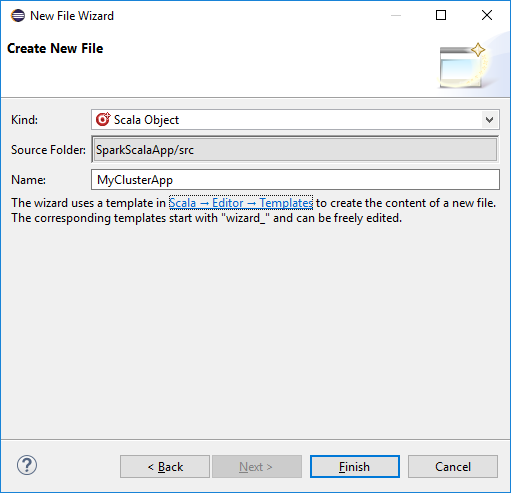
في محرر النص، استبدل المحتويات الحالية بالتعليمات البرمجية أدناه:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }قم بتشغيل التطبيق على نظام مجموعة HDInsight Spark:
أ. من Package Explorer، انقر بزر الماوس الأيمن فوق اسم المشروع، ثم حدد إرسال تطبيق Spark إلى HDInsight.
ب. في مربع الحوار إرسال Spark، قم بتوفير القيم التالية، ثم حدد إرسال:
بالنسبة إلى اسم نظام المجموعة، حدد نظام مجموعة HDInsight Spark الذي تريد تشغيل تطبيقك عليه.
حدد بيانات اصطناعية من مشروع Eclipse، أو حدد واحدة من محرك الأقراص الثابتة. تعتمد القيمة الافتراضية على العنصر الذي تنقر فوقه بزر الماوس الأيمن من Package Explorer.
في القائمة المنسدلة اسم الفئة الرئيسية، يعرض معالج الإرسال جميع أسماء العناصر من مشروعك. حدد أو أدخل واحدًا تريد تشغيله. إذا قمت بتحديد بيانات اصطناعية من محرك الأقراص الثابتة، فيجب عليك إدخال اسم الفئة الرئيسية يدويًا.
نظرًا لأن التعليمات البرمجية للتطبيق في هذا المثال لا تتطلب أي وسيطات سطر أوامر أو ملفات JAR أو ملفات مرجعية، يمكنك ترك مربعات النص المتبقية فارغة.
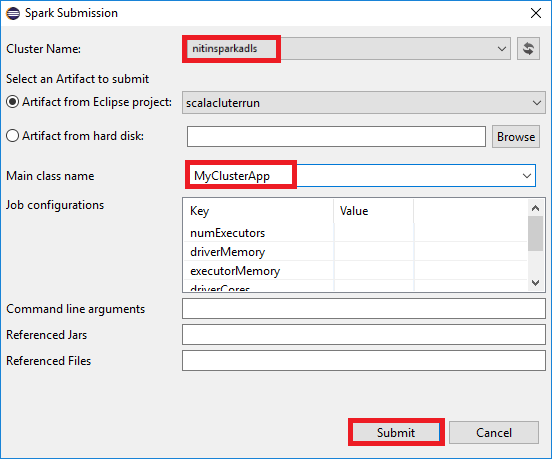
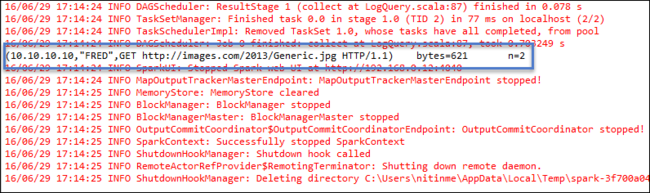
يجب أن تبدأ علامة التبويب إرسال Spark في عرض التقدم. يمكنك إيقاف التطبيق عن طريق تحديد الزر الأحمر في نافذة إرسال Spark. يمكنك أيضًا عرض السجلات الخاصة بتشغيل هذا التطبيق المحدد عن طريق تحديد أيقونة الكرة الأرضية (المشار إليها بالمربع الأزرق في الصورة).
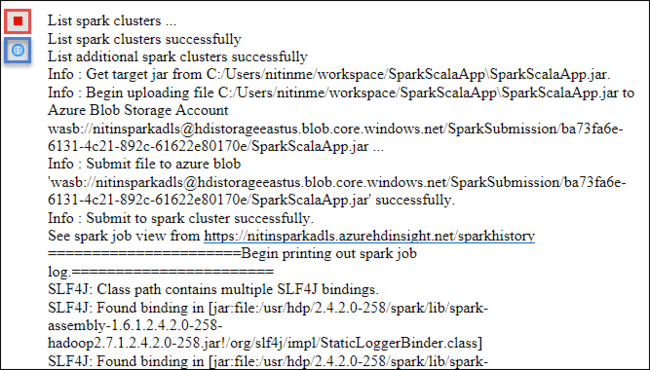
الوصول إلى أنظمة مجموعات HDInsight Spark وإدارتها باستخدام HDInsight Tools في Azure Toolkit for Eclipse
يمكنك تنفيذ العديد من العمليات باستخدام HDInsight Tools، بما في ذلك الوصول إلى إخراج المهمة.
الوصول إلى طريقة عرض المهمة
في Azure Explorer، قم بتوسيع HDInsight، ثم اسم نظام مجموعة Spark، ثم حدد المهام.
حدد عقدة المهام. إذا كان إصدار Java أقل من 1.8، فإن HDInsight Tools يذكرك تلقائيًا بتثبيت المكون الإضافي E(fx)clipse. حدد موافق للمتابعة، ثم اتبع المعالج لتثبيته من Eclipse Marketplace وأعد تشغيل Eclipse.
افتح عرض المهمة من عقدة المهام. في الجزء الأيسر، تعرض علامة التبويب عرض مهمة Spark جميع التطبيقات التي تم تشغيلها في نظام المجموعة. حدد اسم التطبيق الذي تريد الاطلاع على مزيد من التفاصيل عنه.
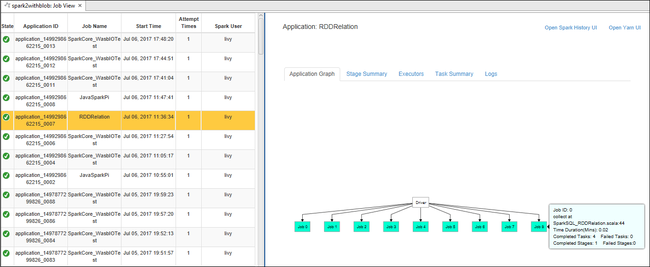
يمكنك بعد ذلك اتخاذ أي من هذه الإجراءات:
قم بالمرور فوق الرسم البياني للمهمة. يعرض معلومات أساسية حول المهمة قيد التشغيل. حدد الرسم البياني للمهمة، ويمكنك مشاهدة المراحل والمعلومات التي تنشأها كل مهمة.
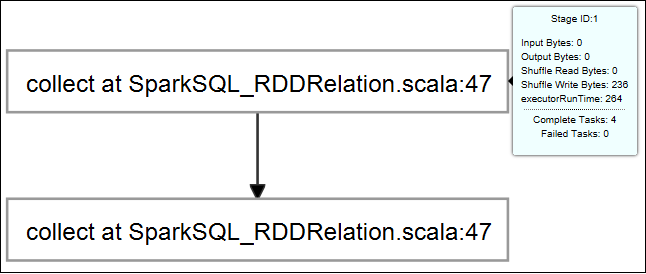
حدد علامة التبويب سجل لعرض السجلات المستخدمة بشكل متكرر، بما في ذلك برنامج التشغيل Stderr، وبرنامج التشغيل Stdout، ومعلومات الدليل.
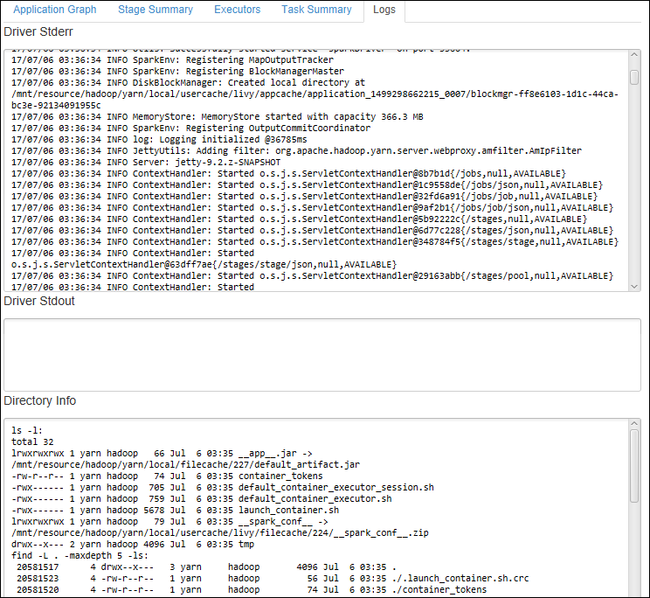
افتح واجهة مستخدم محفوظات Spark وواجهة مستخدم Apache Hadoop YARN (على مستوى التطبيق) عن طريق تحديد الارتباطات التشعبية الموجودة أعلى النافذة.
الوصول إلى حاوية تخزين نظام المجموعة
في Azure Explorer، قم بتوسيع عقدة جذر HDInsight لرؤية قائمة بأنظمة مجموعات HDInsight Spark المتوفرة.
قم بتوسيع اسم نظام المجموعة لرؤية حساب التخزين وحاوية التخزين الافتراضية لنظام المجموعة.
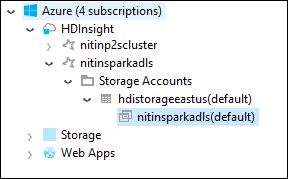
حدد اسم حاوية التخزين المقترنة بنظام المجموعة. في الجزء الأيسر، انقر نقرًا مزدوجًا فوق المجلد HVACOut. افتح أحد ملفات الأجزاء لرؤية إخراج التطبيق.
الوصول إلى خادم محفوظات Spark
في Azure Explorer، انقر بزر الماوس الأيمن فوق اسم نظام مجموعة Spark، ثم حدد فتح واجهة مستخدم محفوظات Spark. أدخل بيانات اعتماد المسؤول لنظام المجموعة عند مطالبتك بذلك. لقد قمت بتحديدها أثناء تزويد نظام المجموعة.
في لوحة معلومات خادم محفوظات Spark، يمكنك استخدام اسم التطبيق للبحث عن التطبيق الذي انتهيت للتو من تشغيله. في التعليمات البرمجية السابقة، قمت بتعيين اسم التطبيق باستخدام
val conf = new SparkConf().setAppName("MyClusterApp"). لذلك، كان اسم تطبيق Spark الخاص بك MyClusterApp.
بدء تشغيل مدخل Apache Ambari
في Azure Explorer، انقر بزر الماوس الأيمن فوق اسم نظام مجموعة Spark، ثم حدد فتح مدخل إدارة نظام المجموعة (Ambari).
أدخل بيانات اعتماد المسؤول لنظام المجموعة عند مطالبتك بذلك. لقد قمت بتحديدها أثناء تزويد نظام المجموعة.
إدارة اشتراكات Azure
بشكل افتراضي، يسرد HDInsight Tool في Azure Toolkit for Eclipse أنظمة مجموعات Spark من جميع اشتراكات Azure الخاصة بك. إذا لزم الأمر، يمكنك تحديد الاشتراكات التي تريد الوصول إلى نظام المجموعة الخاص بها.
في Azure Explorer، انقر بزر الماوس الأيمن فوق عقدة جذر Azure، ثم حدد إدارة الاشتراكات.
في مربع الحوار، قم بإلغاء تحديد خانات الاختيار الخاصة بالاشتراك الذي لا تريد الوصول إليه، ثم حدد إغلاق. يمكنك أيضًا تحديد تسجيل الخروج إذا كنت ترغب في تسجيل الخروج من اشتراك Azure الخاص بك.
تشغيل تطبيق Spark Scala محليًا
يمكنك استخدام HDInsight Tools في Azure Toolkit for Eclipse لتشغيل تطبيقات Spark Scala محليًا في محطة العمل الخاصة بك. عادةً، لا تحتاج هذه التطبيقات إلى الوصول إلى موارد نظام المجموعة مثل حاوية التخزين، ويمكنك تشغيلها واختبارها محليًا.
المتطلب الأساسي
أثناء تشغيل تطبيق Spark Scala المحلي على جهاز كمبيوتر يعمل بنظام Windows، قد تحصل على استثناء كما هو موضح في SPARK-2356. يحدث هذا الاستثناء لأن WinUtils.exe مفقود في Windows.
لحل هذا الخطأ، تحتاج Winutils.exe إلى موقع مثل C:\WinUtils\bin، ثم قم بإضافة متغير البيئة HADOOP_HOME وتعيين قيمة المتغير إلى C\WinUtils.
تشغيل تطبيق Spark Scala محلي
ابدأ تشغيل Eclipse وأنشئ مشروعًا. في مربع الحوار مشروع جديد، حدد الخيارات التالية، ثم حدد التالي.
في معالج مشروع جديد، حدد مشروع HDInsight>تشغيل نموذج Spark on HDInsight محلي (Scala). بعد ذلك حدد التالي.
لتوفير تفاصيل المشروع، اتبع الخطوات من 3 إلى 6 من القسم السابق إعداد مشروع Spark Scala لنظام مجموعة HDInsight Spark.
يضيف القالب نموذج التعليمات البرمجية (LogQuery) ضمن المجلد src الذي يمكنك تشغيله محليًا على جهاز الكمبيوتر الخاص بك.
انقر بزر الماوس الأيمن فوق LogQuery.scala، وحدد تشغيل كـ>1 تطبيق Scala. يظهر مثل هذا الإخراج في علامة التبويب وحدة التحكم:
دور القارئ فقط
عندما يرسل المستخدمون مهمة إلى نظام مجموعة بإذن دور «قارئ فقط»، تكون بيانات اعتماد Ambari مطلوبة.
ربط نظام مجموعة من قائمة السياق
قم بتسجيل الدخول بحساب دور «قارئ فقط».
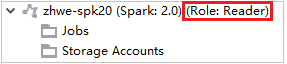
من Azure Explorer، قم بتوسيع HDInsight لعرض أنظمة مجموعات HDInsight الموجودة في اشتراكك. أنظمة المجموعات المميزة بعلامة "دور:قارئ" لها إذن دور للقارئ فقط.
انقر بزر الماوس الأيمن فوق نظام المجموعة الذي له إذن دور قارئ فقط. حدد ربط نظام المجموعة هذا من قائمة السياق لربط نظام المجموعة. أدخل اسم المستخدم وكلمة المرور لـ Ambari.
إذا تم ربط نظام المجموعة بنجاح، فسيتم تحديث HDInsight. وستصبح مرحلة نظام المجموعة مرتبطة.
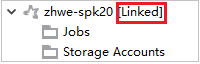
ربط نظام المجموعة عن طريق توسيع عقدة المهام
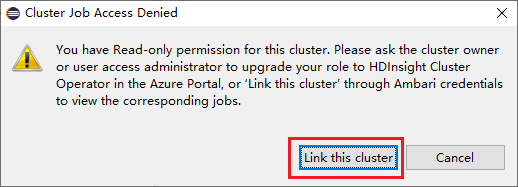
انقر فوق عقدة Jobs، تنبثق نافذة رفض الوصول إلى مهمة نظام المجموعة.
انقر فوق Link this cluster لربط نظام المجموعة.
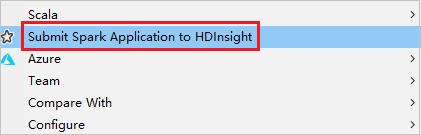
ربط نظام المجموعة من نافذة إرسال Spark
قم بإنشاء مشروع HDInsight.
انقر بزر الماوس الأيمن فوق الحزمة. ثم حدد إرسال تطبيق Spark إلى HDInsight.
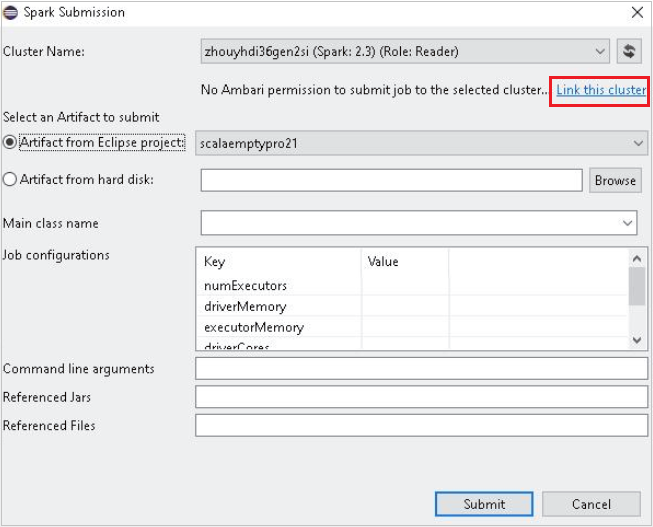
حدد نظام مجموعة، له إذن دور قارئ فقط لـ اسم نظام المجموعة. تظهر رسالة تحذير. يمكنك النقر فوق ربط نظام المجموعة هذا لربط نظام المجموعة.
عرض حسابات التخزين
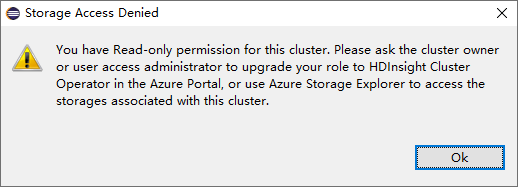
بالنسبة لأنظمة المجموعات التي لها إذن دور قارئ فقط، انقر فوق عقدة Storage Accounts، وستنبثق نافذة رفض الوصول إلى التخزين.
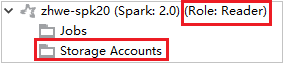
بالنسبة لأنظمة المجموعات المرتبطة، انقر فوق عقدة Storage Accounts، وستنبثق نافذة رفض الوصول إلى التخزين.
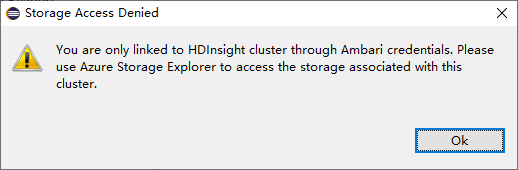
المشاكل المعروفة
عند استخدام ربط نظام مجموعة، أقترح عليك إدخال بيانات اعتماد التخزين.
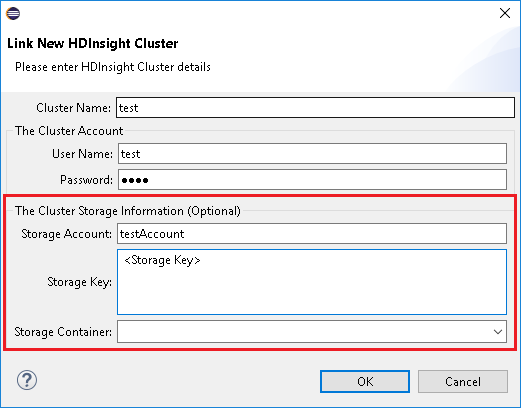
هناك وضعان لإرسال المهام. إذا تم إدخال بيانات اعتماد التخزين، فسيتم استخدام الوضع الدفعي لإرسال المهمة. خلاف ذلك، سيتم استخدام الوضع التفاعلي. إذا كان نظام المجموعة مشغولاً، فقد تتلقى الخطأ أدناه.


(راجع أيضًا )
السيناريوهات
- Apache Spark مع المعلومات المهنية: إجراء تحليل تفاعلي للبيانات باستخدام Spark in HDInsight مع أدوات المعلومات المهنية
- Apache Spark مع التعلم الآلي: استخدام Spark في HDInsight لتحليل درجة حرارة المبنى باستخدام بيانات HVAC
- Apache Spark مع التعلم الآلي: استخدم Spark في HDInsight للتنبؤ بنتائج فحص الأغذية
- تحليل سجل موقع الويب باستخدام Apache Spark في HDInsight
إنشاء التطبيقات وتشغيلها
الأدوات والملحقات
- استخدام Azure Toolkit for IntelliJ لإنشاء تطبيقات Spark Scala وإرسالها
- استخدام مجموعة أدوات Azure لـ IntelliJ لتتبع أخطاء تطبيقات Apache Spark عن بُعد من خلال VPN
- استخدام Azure Toolkit لـ IntelliJ لتصحيح أخطاء تطبيقات Apache Spark عن بُعد من خلال SSH
- استخدام دفاتر ملاحظات Apache Zeppelin مع نظام مجموعة Apache Spark على HDInsight
- تتوفر Kernels لـ Jupyter Notebook في مجموعة Apache Spark لـ HDInsight
- استخدام الحزم الخارجية مع دفاتر ملاحظات Jupyter
- تثبيت Jupyter على جهاز الكمبيوتر الخاص بك، والاتصال بنظام مجموعة HDInsight Spark