Shiny v Azure Databricks
Shiny je balíček R, který je k dispozici v CRAN, který slouží k vytváření interaktivních aplikací a řídicích panelů R. Shiny můžete použít uvnitř RStudio Serveru hostovaného v clusterech Azure Databricks. Můžete také vyvíjet, hostovat a sdílet aplikace Shiny přímo z poznámkového bloku Azure Databricks.
Pokud chcete začít se Shiny, podívejte se na Shiny návody. Tyto kurzy můžete spustit v poznámkových blocích Azure Databricks.
Tento článek popisuje, jak spouštět aplikace Shiny v Azure Databricks a používat Apache Spark v aplikacích Shiny.
Balíček Shiny je součástí databricks Runtime. Aplikace Shiny můžete interaktivně vyvíjet a testovat v poznámkových blocích Azure Databricks R podobně jako hostované RStudio.
Začněte tímto postupem:
Vytvořte poznámkový blok R.
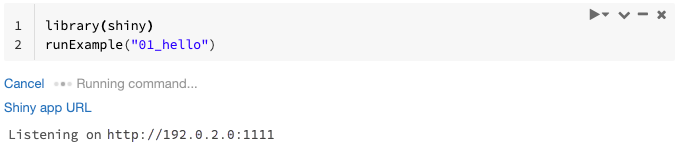
Naimportujte balíček Shiny a spusťte ukázkové aplikace
01_hellonásledujícím způsobem:library(shiny) runExample("01_hello")Až bude aplikace připravená, bude výstup obsahovat adresu URL aplikace Shiny jako odkaz, na který se dá kliknout a otevře se nová karta. Pokud chcete tuto aplikaci sdílet s ostatními uživateli, podívejte se na adresu URL aplikace Share Shiny.
Poznámka
- Zprávy protokolu se zobrazí ve výsledku příkazu, podobně jako výchozí zpráva protokolu (
Listening on http://0.0.0.0:5150) zobrazená v příkladu. - Chcete-li zastavit aplikaci Shiny, klepněte na tlačítko Storno.
- Aplikace Shiny používá proces poznámkového bloku R. Pokud poznámkový blok odpojete od clusteru nebo zrušíte buňku spuštěnou aplikaci, aplikace Shiny se ukončí. Jiné buňky nelze spustit, když je aplikace Shiny spuštěná.
Aplikace Shiny, které jsou rezervované do složek Git Databricks, můžete spustit.
Aplikaci spusťte.
library(shiny) runApp("006-tabsets")
Pokud je kód aplikace Shiny součástí projektu spravovaného správou verzí, můžete ho spustit v poznámkovém bloku.
Poznámka
Musíte použít absolutní cestu nebo nastavit pracovní adresář s setwd().
Podívejte se na kód z úložiště pomocí podobného kódu:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Pokud chcete aplikaci spustit, zadejte kód podobný následujícímu v jiné buňce:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Adresa URL aplikace Shiny vygenerovaná při spuštění aplikace se dá sdílet s ostatními uživateli. Každý uživatel Azure Databricks s oprávněním PŘIPOJIT SE KE clusteru může zobrazit aplikaci a pracovat s ní, pokud je spuštěná aplikace i cluster.
Pokud se cluster, na kterém aplikace běží, ukončí, aplikace už nebude přístupná. Automatické ukončení můžete zakázat v nastavení clusteru.
Pokud připojíte a spustíte poznámkový blok hostující aplikaci Shiny v jiném clusteru, změní se adresa URL Shiny. Pokud aplikaci restartujete ve stejném clusteru, shiny může vybrat jiný náhodný port. Pokud chcete zajistit stabilní adresu URL, můžete nastavit možnost shiny.port nebo při restartování aplikace ve stejném clusteru zadat port argument.
Důležité
V případě RStudio Serveru Pro je nutné zakázat ověřování pomocí proxy serveru.
Ujistěte se, že auth-proxy=1 uvnitř není /etc/rstudio/rserver.conf.
Otevřete RStudio v Azure Databricks.
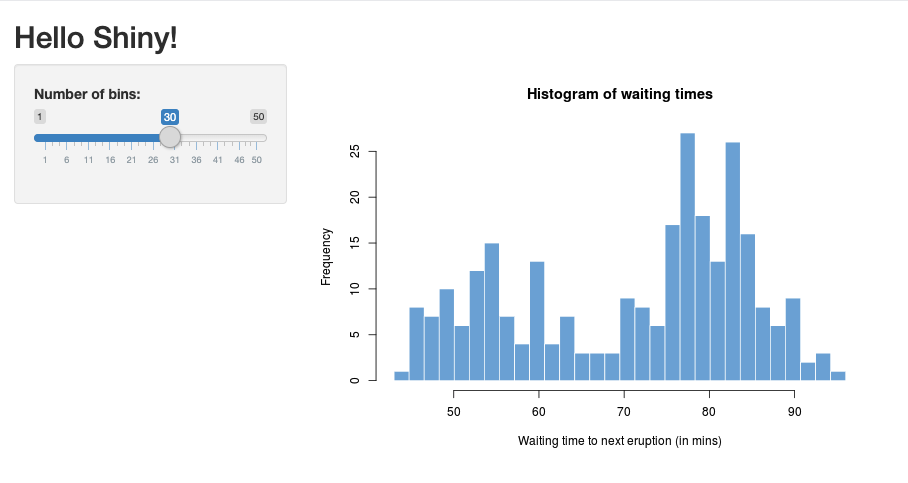
V RStudio naimportujte balíček Shiny a spusťte ukázkové aplikace
01_hellonásledujícím způsobem:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Zobrazí se nové okno zobrazující aplikaci Shiny.
Pokud chcete spustit aplikaci Shiny ze skriptu jazyka R, otevřete skript R v editoru RStudio a klikněte na tlačítko Spustit aplikaci v pravém horním rohu.
Apache Spark můžete použít v aplikacích Shiny s SparkR nebo sparklyr.
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
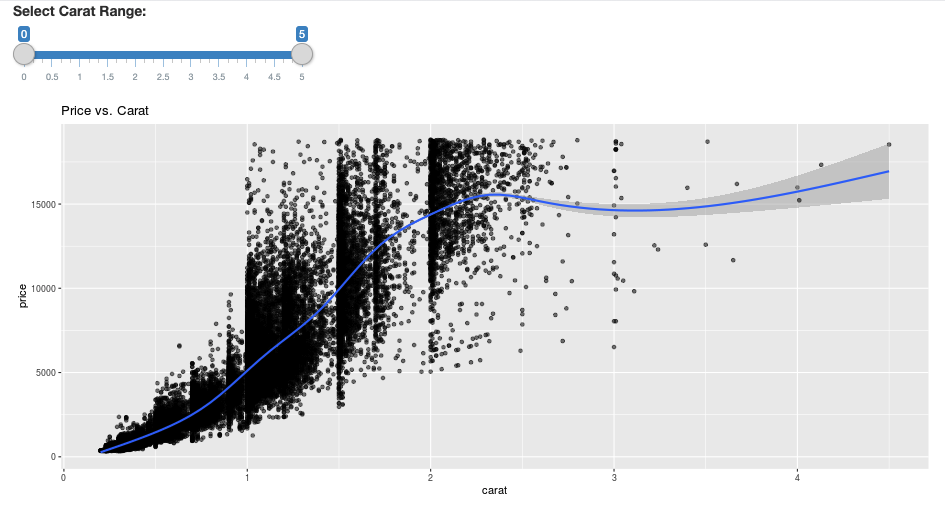
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
- Proč je moje aplikace Shiny zašedlá po nějaké době?
- Proč mi po chvíli zmizí okno prohlížeče Shiny?
- Proč se dlouhé úlohy Sparku nikdy nevracely?
- Jak se můžu vyhnout vypršení časového limitu?
- Aplikace se okamžitě po spuštění chybově ukončí, ale zdá se, že kód je správný. Co se děje?
- Kolik připojení lze během vývoje přijmout pro jeden odkaz aplikace Shiny?
- Můžu použít jinou verzi balíčku Shiny, než je verze nainstalovaná v Databricks Runtime?
- Jak můžu vyvíjet aplikaci Shiny, která se dá publikovat na serveru Shiny a přistupovat k datům v Azure Databricks?
- Můžu v poznámkovém bloku Azure Databricks vyvíjet aplikaci Shiny?
- Jak můžu uložit aplikace Shiny, které jsem vyvinul na hostovaný RStudio Server?
Pokud není žádná interakce s aplikací Shiny, připojení k aplikaci se zavře přibližně po 4 minutách.
Pokud se chcete znovu připojit, aktualizujte stránku aplikace Shiny. Stav řídicího panelu se resetuje.
Pokud okno Shiny Viewer zmizí po několika minutách nečinnosti, je to kvůli stejnému vypršení časového limitu jako při scénáři zašednutí.
Důvodem je také časový limit nečinnosti. Jakákoli úloha Sparku spuštěná po delší dobu než dříve uvedené časové limity nemůže vykreslit její výsledek, protože připojení se zavře před vrácením úlohy.
Existuje alternativní řešení navrhované v žádosti o funkci: Požádejte klienta, aby odesílal aktivní zprávu, aby u některých nástrojů pro vyrovnávání zatížení na GitHubu nedocházelo k vypršení časového limitu protokolu TCP. Alternativní řešení odesílá prezenčních signálů, aby připojení WebSocket zůstal aktivní, když je aplikace nečinná. Pokud je ale aplikace blokovaná dlouhotrvajícím výpočtem, toto alternativní řešení nefunguje.
Shiny nepodporuje dlouhotrvající úkoly. Blogový příspěvek Shiny doporučuje používat přísliby a budoucnost ke spouštění dlouhých úloh asynchronně a udržovat aplikaci odblokovanou. Tady je příklad, který pomocí prezenčních signálů udržuje aplikaci Shiny naživu a spouští dlouho běžící úlohu Sparku v konstruktoru
future.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)Od počátečního načtení stránky platí pevný limit 12 hodin, po kterém se ukončí jakékoli připojení, i když je aktivní. Aplikaci Shiny musíte aktualizovat, aby se v těchto případech znovu připojila. Základní připojení WebSocket se však může kdykoli zavřít různými faktory, včetně nestability sítě nebo režimu spánku počítače. Databricks doporučuje přepisovat aplikace Shiny tak, aby nepožadovala dlouhodobé připojení a nespoléhá na stav relace.
Celková velikost dat, která se dají zobrazit v aplikaci Shiny v Azure Databricks, je limit 50 MB. Pokud celková velikost dat aplikace překročí tento limit, dojde k chybovému ukončení hned po spuštění. Aby se tomu zabránilo, Databricks doporučuje zmenšit velikost dat, například zmenšením převzorkování zobrazených dat nebo snížením rozlišení obrázků.
Databricks doporučuje až 20.
Ano. Viz Oprava verze balíčků R.
Jak můžu vyvíjet aplikaci Shiny, která se dá publikovat na serveru Shiny a přistupovat k datům v Azure Databricks?
Zatímco při vývoji a testování v Azure Databricks můžete k datům přistupovat přirozeně pomocí SparkR nebo sparklyru, po publikování aplikace Shiny do samostatné hostitelské služby nemůže přímo přistupovat k datům a tabulkám v Azure Databricks.
Pokud chcete, aby vaše aplikace fungovala mimo Azure Databricks, musíte přepsat, jak přistupujete k datům. Existuje několik možností:
- Pomocí JDBC/ODBC odešlete dotazy do clusteru Azure Databricks.
- Použijte Databricks Connect.
- Přímý přístup k datům v úložišti objektů
Databricks doporučuje, abyste ve spolupráci s týmem řešení Azure Databricks našli nejlepší přístup pro vaši stávající architekturu dat a analýz.
Ano, aplikaci Shiny můžete vyvíjet v poznámkovém bloku Azure Databricks.
Kód aplikace můžete uložit do DBFS nebo zkontrolovat kód do správy verzí.