Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
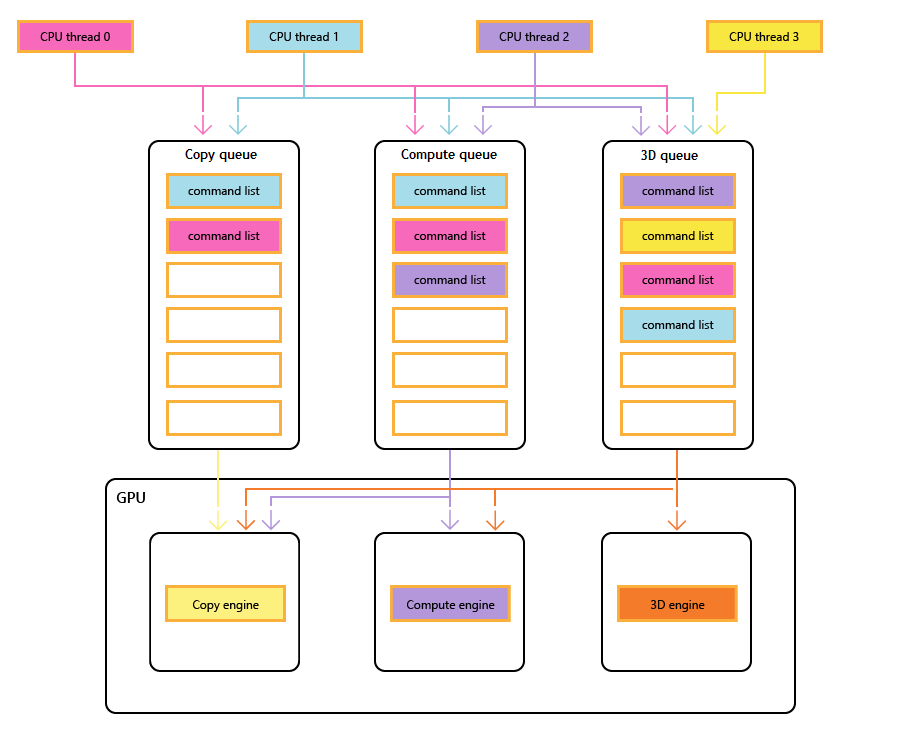
La plupart des GPU modernes contiennent plusieurs moteurs indépendants qui fournissent des fonctionnalités spécialisées. Plusieurs ont un ou plusieurs moteurs de copie dédiés et un moteur de calcul, généralement distinct du moteur 3D. Chacun de ces moteurs peut exécuter des commandes en parallèle entre eux. Direct3D 12 fournit un accès précis aux moteurs 3D, de calcul et de copie, à l’aide de files d’attente et de listes de commandes.
Moteurs GPU
Le diagramme suivant montre les threads d’UC d’un titre, chacun remplit une ou plusieurs files d’attente de copie, de calcul et de 3D. La file d’attente 3D peut piloter les trois moteurs GPU ; la file d’attente de calcul peut conduire les moteurs de calcul et de copie ; et la file d’attente de copie simplement le moteur de copie.
Comme les différents threads remplissent les files d’attente, il ne peut y avoir de garantie simple de l’ordre d’exécution, donc la nécessité de mécanismes de synchronisation , lorsque le titre les requiert.
L’image suivante montre comment un titre peut planifier un travail sur plusieurs moteurs GPU, y compris la synchronisation entre moteurs si nécessaire : il affiche les charges de travail par moteur avec des dépendances entre moteurs. Dans cet exemple, le moteur de copie copie d’abord certaines géométries nécessaires au rendu. Le moteur 3D attend que ces copies se terminent et restitue un pré-passage sur la géométrie. Cela est ensuite consommé par le moteur de calcul. Les résultats du moteur de calcul Dispatch, ainsi que plusieurs opérations de copie de texture sur le moteur de copie, sont consommés par le moteur 3D pour l’appel final Dessiner.
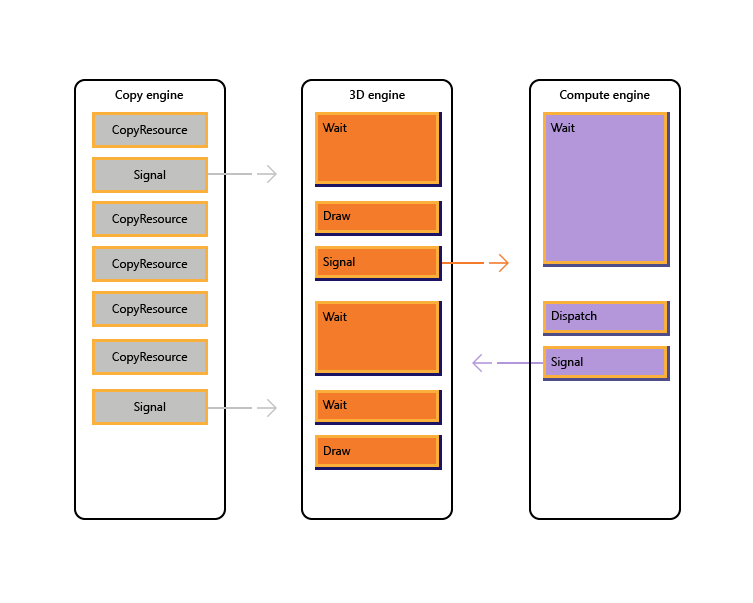
Le pseudo-code suivant illustre la façon dont un titre peut soumettre une telle charge de travail.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
Le pseudo-code suivant illustre la synchronisation entre les moteurs de copie et 3D pour accomplir l’allocation de mémoire de type tas via une mémoire tampon en anneau. Les titres ont la possibilité de choisir le bon équilibre entre l’optimisation du parallélisme (via une mémoire tampon volumineuse) et la réduction de la consommation de mémoire et de la latence (via une petite mémoire tampon).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Scénarios multi-moteurs
Direct3D 12 vous permet d’éviter de rencontrer accidentellement des inefficacités causées par des retards de synchronisation inattendus. Il vous permet également d’introduire la synchronisation à un niveau supérieur où la synchronisation requise peut être déterminée avec une plus grande certitude. Un deuxième problème que les adresses multi-moteurs consiste à rendre les opérations coûteuses plus explicites, ce qui inclut les transitions entre 3D et vidéo qui étaient traditionnellement coûteuses en raison de la synchronisation entre plusieurs contextes de noyau.
En particulier, les scénarios suivants peuvent être traités avec Direct3D 12.
- Le travail GPU asynchrone et de faible priorité fonctionne. Cela permet l’exécution simultanée de travaux GPU de faible priorité et d’opérations atomiques qui permettent à un thread GPU de consommer les résultats d’un autre thread non synchronisé sans bloquer.
- Travail de calcul à priorité élevée. Avec le calcul en arrière-plan, il est possible d’interrompre le rendu 3D pour effectuer une petite quantité de travail de calcul à priorité élevée. Les résultats de ce travail peuvent être obtenus tôt pour un traitement supplémentaire sur le processeur.
- Travail de calcul en arrière-plan. Une file d’attente de faible priorité distincte pour les charges de travail de calcul permet à une application d’utiliser des cycles GPU de rechange pour effectuer un calcul en arrière-plan sans impact négatif sur les tâches de rendu principale (ou d’autres). Les tâches en arrière-plan peuvent inclure la décompression des ressources ou la mise à jour de simulations ou de structures d’accélération. Les tâches en arrière-plan doivent être synchronisées rarement sur l’UC (environ une fois par image) pour éviter de bloquer ou de ralentir le travail au premier plan.
- Diffusion en continu et chargement de données. Une file d’attente de copie distincte remplace les concepts D3D11 des données initiales et la mise à jour des ressources. Bien que l’application soit responsable de plus de détails dans le modèle Direct3D 12, cette responsabilité est liée à la puissance. L’application peut contrôler la quantité de mémoire système consacrée à la mise en mémoire tampon des données de chargement. L’application peut choisir quand et comment (processeur ou GPU, blocage et non bloquant) à synchroniser, et peut suivre la progression et contrôler la quantité de travail en file d’attente.
- Augmentation du parallélisme. Les applications peuvent utiliser des files d’attente plus approfondies pour les charges de travail en arrière-plan (par exemple, le décodage vidéo) lorsqu’elles ont des files d’attente distinctes pour le travail au premier plan.
Dans Direct3D 12, le concept d’une file d’attente de commandes est la représentation API d’une séquence de travail à peu près série soumise par l’application. Les obstacles et d’autres techniques permettent l’exécution de ce travail dans un pipeline ou hors ordre, mais l’application ne voit qu’une seule chronologie d’achèvement. Cela correspond au contexte immédiat dans D3D11.
API de synchronisation
Appareils et files d’attente
L’appareil Direct3D 12 a des méthodes pour créer et récupérer des files d’attente de commandes de différents types et priorités. La plupart des applications doivent utiliser les files d’attente de commandes par défaut, car elles autorisent l’utilisation partagée par d’autres composants. Les applications avec des exigences de concurrence supplémentaires peuvent créer des files d’attente supplémentaires. Les files d’attente sont spécifiées par le type de liste de commandes qu’ils consomment.
Reportez-vous aux méthodes de création suivantes de ID3D12Device.
- CreateCommandQueue : crée une file d’attente de commandes basée sur des informations dans une structure Direct3D 12_COMMAND_QUEUE_DESC.
- CreateCommandList : crée une liste de commandes de type direct3D 12_COMMAND_LIST_TYPE.
- CreateFence : crée une clôture, notant les indicateurs dans 12_FENCE_FLAGSDirect3D . Les clôtures sont utilisées pour synchroniser les files d’attente.
Les files d’attente de tous les types (3D, calcul et copie) partagent la même interface et sont toutes basées sur la liste de commandes.
Reportez-vous aux méthodes suivantes de ID3D12CommandQueue.
- ExecuteCommandLists : envoie un tableau de listes de commandes pour l’exécution. Chaque liste de commandes définie par ID3D12CommandList.
- Signal : définit une valeur de clôture lorsque la file d’attente (en cours d’exécution sur le GPU) atteint un certain point.
- d’attente : la file d’attente attend que la clôture spécifiée atteigne la valeur spécifiée.
Notez que les offres groupées ne sont pas consommées par des files d’attente et, par conséquent, ce type ne peut pas être utilisé pour créer une file d’attente.
Clôtures
L’API multi-moteur fournit des API explicites pour créer et synchroniser à l’aide de clôtures. Une clôture est une construction de synchronisation contrôlée par une valeur UINT64. Les valeurs de clôture sont définies par l’application. Une opération de signal modifie la valeur de clôture et une opération d’attente bloque jusqu’à ce que la clôture ait atteint la valeur demandée ou supérieure. Un événement peut être déclenché lorsqu’une clôture atteint une certaine valeur.
Reportez-vous aux méthodes de l’interface ID3D12Fence.
- GetCompletedValue : retourne la valeur actuelle de la clôture.
- SetEventOnCompletion : déclenche un événement lorsque la clôture atteint une valeur donnée.
- Signal : définit la clôture sur la valeur donnée.
Les clôtures permettent l’accès au processeur à la valeur de clôture actuelle, et les attentes et les signaux du processeur.
La méthode Signal sur l’interface ID3D12Fence met à jour une clôture du côté processeur. Cette mise à jour se produit immédiatement. La méthode Signal sur ID3D12CommandQueue met à jour une clôture du côté GPU. Cette mise à jour se produit une fois toutes les autres opérations effectuées dans la file d’attente de commandes.
Tous les nœuds d’une configuration multi-moteur peuvent lire et réagir à n’importe quelle clôture atteignant la bonne valeur.
Les applications définissent leurs propres valeurs de clôture, un bon point de départ peut augmenter une clôture une fois par cadre.
Une clôture peut être rewound. Cela signifie que la valeur de clôture n’a pas besoin d’incrémenter uniquement. Si une opération Signal est mise en file d’attente sur deux files d’attente de commandes différentes, ou si deux threads de processeur appellent tous deux Signal sur une clôture, il peut y avoir une course pour déterminer quelle Signal se termine en dernier, et par conséquent, quelle valeur de clôture est celle qui restera. Si une clôture est rewound, toute nouvelle attente (y compris SetEventOnCompletion demandes) est comparée à la nouvelle valeur de clôture inférieure, et peut donc ne pas être satisfaite, même si la valeur de clôture avait été suffisamment élevée pour les satisfaire. Si une course se produit, entre une valeur qui satisfait une attente en attente en attente et une valeur inférieure qui ne le sera pas, l’attente sera être satisfaite indépendamment de la valeur restante par la suite.
Les API de clôture fournissent de puissantes fonctionnalités de synchronisation, mais peuvent créer des problèmes potentiellement difficiles à déboguer. Il est recommandé que chaque clôture soit utilisée uniquement pour indiquer la progression d’une chronologie afin d’empêcher les courses entre les signaleurs.
Copier et calculer des listes de commandes
Les trois types de liste de commandes utilisent l’interface ID3D12GraphicsCommandList, mais seul un sous-ensemble des méthodes est pris en charge pour la copie et le calcul.
Les listes de commandes copier et calculer peuvent utiliser les méthodes suivantes.
- Fermer
- CopyBufferRegion
- CopyResource
- CopyTextureRegion
- copyTiles
- réinitialiser
- ResourceBarrier
Les listes de commandes de calcul peuvent également utiliser les méthodes suivantes.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- executeIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- setDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Les listes de commandes de calcul doivent définir une authentification unique de calcul lors de l’appel SetPipelineState.
Les offres groupées ne peuvent pas être utilisées avec des listes de commandes ou des files d’attente de calcul ou de copie.
Exemple de calcul et de graphiques pipelines
Cet exemple montre comment la synchronisation de clôture peut être utilisée pour créer un pipeline de travail de calcul sur une file d’attente (référencée par pComputeQueue) consommée par le travail graphique sur la file d’attente pGraphicsQueue. Le travail de calcul et de graphisme est pipeline avec la file d’attente graphique consommant le résultat du travail de calcul à partir de plusieurs images de retour, et un événement processeur est utilisé pour limiter le travail total mis en file d’attente dans l’ensemble.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Pour prendre en charge ce pipeline, il doit y avoir une mémoire tampon de ComputeGraphicsLatency+1 différentes copies des données passant de la file d’attente de calcul à la file d’attente graphique. Les listes de commandes doivent utiliser les UAV et l’indirection pour lire et écrire à partir de la « version » appropriée des données dans la mémoire tampon. La file d’attente de calcul doit attendre que la file d’attente graphique ait terminé la lecture à partir des données de l’image N avant de pouvoir écrire des images N+ComputeGraphicsLatency.
Notez que la quantité de file d’attente de calcul travaillée par rapport au processeur ne dépend pas directement de la quantité de mise en mémoire tampon requise. Toutefois, le travail de mise en file d’attente gpu au-delà de la quantité d’espace tampon disponible est moins utile.
Un autre mécanisme pour éviter l’indirection consisterait à créer plusieurs listes de commandes correspondant à chacune des versions « renommées » des données. L’exemple suivant utilise cette technique tout en étendant l’exemple précédent pour permettre aux files d’attente de calcul et graphiques de s’exécuter de manière plus asynchrone.
Exemple de calcul et de graphique asynchrone
Cet exemple suivant permet aux graphiques de s’afficher de manière asynchrone à partir de la file d’attente de calcul. Il existe toujours une quantité fixe de données mises en mémoire tampon entre les deux phases, mais maintenant le travail graphique se poursuit indépendamment et utilise le résultat le plus up-to-date de la phase de calcul comme connu sur l’UC lorsque le travail graphique est mis en file d’attente. Cela serait utile si le travail graphique était mis à jour par une autre source, par exemple une entrée utilisateur. Il doit y avoir plusieurs listes de commandes pour permettre au ComputeGraphicsLatency images de travail graphique d’être en vol à la fois, et la fonction UpdateGraphicsCommandList représente la mise à jour de la liste de commandes pour inclure les données d’entrée les plus récentes et lire à partir des données de calcul à partir de la mémoire tampon appropriée.
La file d’attente de calcul doit toujours attendre la fin de la file d’attente graphique avec les mémoires tampons de canal, mais une troisième clôture (pGraphicsComputeFence) est introduite afin que la progression du travail de calcul de lecture graphique par rapport à la progression graphique en général puisse être suivie. Cela reflète le fait que les images graphiques consécutives peuvent désormais lire à partir du même résultat de calcul ou ignorer un résultat de calcul. Une conception plus efficace mais légèrement plus complexe utiliserait uniquement la clôture graphique unique et stockerait un mappage aux images de calcul utilisées par chaque image graphique.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Accès aux ressources multi-files d’attente
Pour accéder à une ressource sur plusieurs files d’attente, une application doit respecter les règles suivantes.
L’accès aux ressources (reportez-vous à direct3D 12_RESOURCE_STATES) est déterminé par la classe de type file d’attente et non par objet file d’attente. Il existe deux classes de type de file d’attente : la file d’attente Compute/3D est une classe de type, Copy est une deuxième classe de type. Par conséquent, une ressource qui a un obstacle à l’état NON_PIXEL_SHADER_RESOURCE sur une file d’attente 3D peut être utilisée dans cet état sur n’importe quelle file d’attente 3D ou de calcul, en fonction des exigences de synchronisation qui nécessitent la sérialisation de la plupart des écritures. Les états de ressource partagés entre les deux classes de type (COPY_SOURCE et COPY_DEST) sont considérés comme des états différents pour chaque classe de type. Ainsi, si une ressource passe à COPY_DEST sur une file d’attente de copie, elle n’est pas accessible en tant que destination de copie à partir de files d’attente 3D ou de calcul et vice versa.
Pour résumer.
- Une file d’attente « objet » est une file d’attente unique.
- Une file d’attente « type » est l’une des trois suivantes : Calcul, 3D et Copie.
- Une file d’attente « classe de type » est l’une des deux suivantes : Compute/3D et Copy.
Les indicateurs COPY (COPY_DEST et COPY_SOURCE) utilisés comme états initiaux représentent des états dans la classe de type 3D/Compute. Pour utiliser une ressource initialement dans une file d’attente de copie, elle doit démarrer dans l’état COMMON. L’état COMMON peut être utilisé pour toutes les utilisations d’une file d’attente de copie à l’aide des transitions d’état implicites.
Bien que l’état des ressources soit partagé entre toutes les files d’attente de calcul et 3D, il n’est pas autorisé à écrire simultanément dans la ressource sur différentes files d’attente. « Simultanément » signifie ici une exécution non synchronisée, notant l’exécution non synchronisée n’est pas possible sur un matériel. Les règles suivantes s’appliquent.
- Une seule file d’attente peut écrire dans une ressource à la fois.
- Plusieurs files d’attente peuvent lire à partir de la ressource tant qu’elles ne lisent pas les octets modifiés par l’enregistreur (la lecture d’octets en cours d’écriture simultanée produit des résultats non définis).
- Une clôture doit être utilisée pour synchroniser après l’écriture avant qu’une autre file d’attente puisse lire les octets écrits ou rendre un accès en écriture.
Les mémoires tampons de retour présentées doivent être dans l’état de 12_RESOURCE_STATE_COMMON Direct3D.
Rubriques connexes
guide de programmation Direct3D 12
Utilisation des barrières de ressources pour synchroniser les états des ressources dans Direct3D 12
gestion de la mémoire dans Direct3D 12