Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Nilai kluster secara otomatis membuat grup dengan nilai serupa menggunakan algoritma pencocokan fuzzy, lalu memetakan nilai setiap kolom ke grup yang paling cocok. Transformasi ini berguna saat Anda bekerja dengan data yang memiliki banyak variasi berbeda dari nilai yang sama dan Anda perlu menggabungkan nilai ke dalam grup yang konsisten.
Pertimbangkan tabel sampel dengan kolom id yang berisi sekumpulan ID dan kolom Orang yang berisi sekumpulan versi nama Miguel, Mike, William, dan Bill yang dieja dan dikapitalisasi.
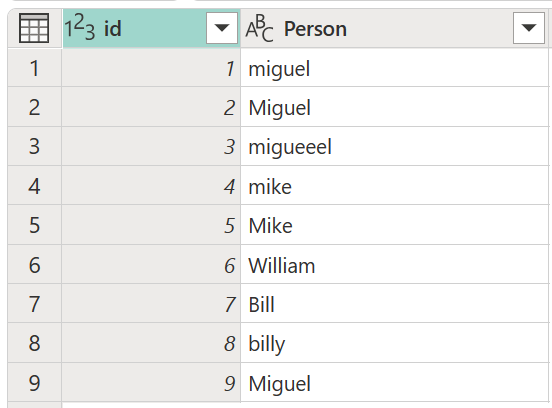
Dalam contoh ini, hasil yang Anda cari adalah tabel dengan kolom baru yang memperlihatkan grup nilai yang tepat dari kolom Orang dan bukan semua variasi berbeda dari kata yang sama.
Nota
Fitur Nilai kluster hanya tersedia untuk Power Query Online.
Membuat kolom Kluster
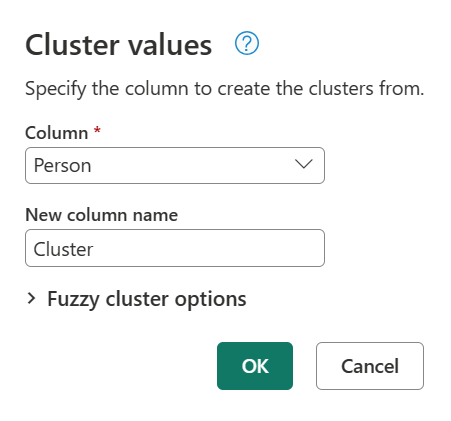
Untuk nilai kluster, pertama-tama pilih kolom Orang , masuk ke tab Tambahkan kolom di pita, lalu pilih opsi Nilai kluster .
![]()
Dalam kotak dialog Nilai kluster , konfirmasikan kolom yang ingin Anda gunakan untuk membuat kluster, dan masukkan nama baru kolom. Untuk kasus ini, beri nama kluster kolom baru ini.
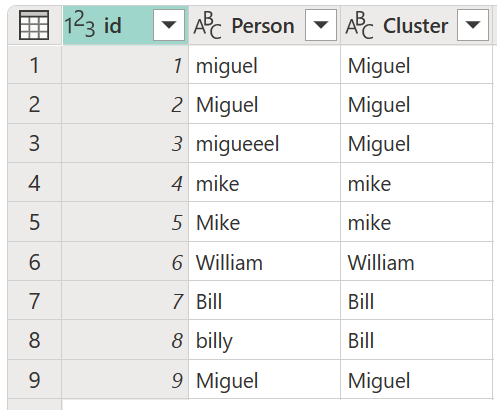
Hasil operasi tersebut ditampilkan dalam gambar berikut.
Nota
Untuk setiap kluster nilai, Power Query memilih instans yang paling sering dari kolom yang dipilih sebagai instans "kanonis". Jika beberapa instans terjadi dengan frekuensi yang sama, Power Query akan memilih instans pertama.
Menggunakan opsi kluster fuzzy
Opsi berikut ini tersedia untuk nilai pengklusteran di kolom baru:
- Ambang kesamaan (opsional): Opsi ini menunjukkan bagaimana dua nilai serupa harus dikelompokkan bersama. Pengaturan minimum nol (0) menyebabkan semua nilai dikelompokkan bersama-sama. Pengaturan maksimum 1 hanya memungkinkan nilai yang cocok persis untuk dikelompokkan bersama-sama. Defaultnya adalah 0,8.
- Abaikan huruf besar/kecil: Saat string teks dibandingkan, huruf besar/kecil diabaikan. Opsi ini diaktifkan secara default.
- Kelompokkan dengan menggabungkan bagian teks: Algoritma mencoba untuk mengkombinasikan bagian-bagian teks (seperti menggabungkan Micro dan soft menjadi Microsoft) untuk memudahkan pengelompokan nilai.
- Tampilkan skor kesamaan: Menampilkan skor kesamaan antara nilai input dan nilai perwakilan yang dihitung setelah pengklusteran fuzzy.
- Tabel transformasi (opsional): Anda dapat memilih tabel transformasi yang memetakan nilai (seperti memetakan MSFT ke Microsoft) untuk mengelompokkannya bersama-sama.
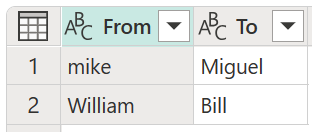
Untuk contoh ini, tabel transformasi baru dengan nama Tabel transformasi saya digunakan untuk menunjukkan bagaimana nilai dapat dipetakan. Tabel transformasi ini memiliki dua kolom:
- Dari: String teks yang akan dicari di tabel Anda.
- Ke: String teks yang akan digunakan untuk mengganti string teks di kolom Dari .
Penting
Penting bahwa tabel transformasi memiliki nama kolom dan kolom yang sama seperti yang ditunjukkan pada gambar sebelumnya (tabel tersebut harus diberi nama "Dari" dan "Ke"), jika tidak Power Query tidak akan mengenali tabel ini sebagai tabel transformasi, dan tidak ada transformasi yang akan terjadi.
Menggunakan kueri yang dibuat sebelumnya, klik dua kali langkah Nilai terkluster , lalu dalam kotak dialog Nilai kluster , perluas opsi kluster Fuzzy. Di bawah Opsi kluster Fuzzy, aktifkan opsi Tampilkan skor kesamaan . Untuk tabel Transformasi (opsional), pilih kueri yang memiliki tabel transformasi.
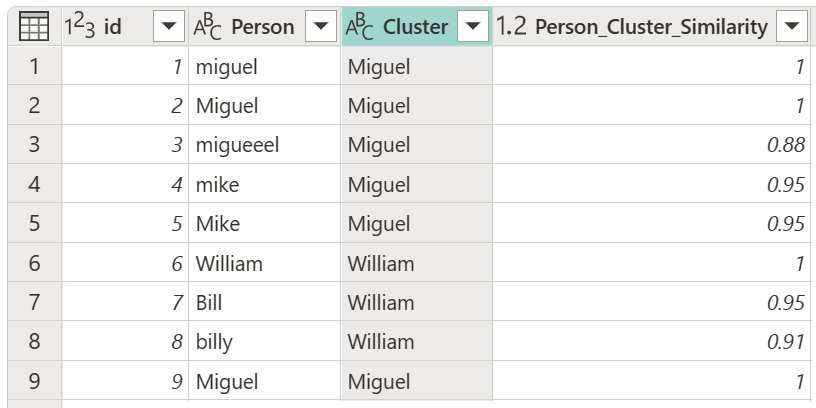
Setelah memilih tabel transformasi Anda dan mengaktifkan opsi Perlihatkan skor kesamaan , pilih OK. Hasil operasi tersebut memberi Anda tabel yang berisi id dan kolom Orang yang sama dengan tabel asli, tetapi juga menyertakan dua kolom baru yang disebut Kluster dan Person_Cluster_Similarity. Kolom Kluster berisi versi nama yang dieja dan dikapitalisasi dengan benar yaitu Miguel untuk versi nama Miguel dan Mike, serta William untuk versi nama Bill, Billy, dan William. Kolom Person_Cluster_Similarity berisi skor kesamaan untuk setiap nama.
Prinsip tabel transformasi
Anda mungkin melihat bahwa tabel transformasi di bagian sebelumnya tampaknya menunjukkan bahwa instans Mike diubah menjadi Miguel dan instans William diubah menjadi Bill. Namun, dalam tabel yang dihasilkan, instans Bill dan "billy" malah diubah menjadi William. Dalam tabel transformasi, alih-alih menjadi jalur langsung Dari ke Ke, tabel transformasi ini simetris selama pengklusteran, yang berarti bahwa "mike" setara dengan "Miguel" dan sebaliknya. Hasil yang setara yang diberikan dalam tabel transformasi tergantung pada aturan berikut:
- Jika ada sebagian besar nilai yang identik, nilai-nilai ini lebih diutamakan daripada nilai nonidentik.
- Jika tidak ada sebagian besar nilai, nilai yang muncul terlebih dahulu diutamakan.
Misalnya, dalam tabel asli yang digunakan dalam artikel ini, versi Miguel (baik "miguel" dan Miguel) di kolom Orang mencakup sebagian besar kemunculan nama Miguel dan Mike. Selain itu, penggunaan huruf kapital awal pada nama Miguel membentuk mayoritas dari nama tersebut. Jadi mengaitkan Miguel dan turunannya dan Mike dan turunannya dalam tabel transformasi menghasilkan nama Miguel yang digunakan di kolom Kluster .
Namun, untuk nama William, Bill, dan "billy", tidak ada mayoritas nilai karena ketiganya unik. Sejak William muncul pertama kali, William digunakan di kolom Kluster . Jika "billy" muncul terlebih dahulu dalam tabel, maka "billy" akan digunakan di kolom Kluster . Selain itu, karena tidak ada nilai mayoritas, kasus yang diterapkan oleh nama individu digunakan. Artinya, jika William adalah yang pertama dalam urutan, William dengan huruf besar "W" digunakan sebagai nilai hasil; jika "billy" adalah yang pertama, "billy" dengan huruf kecil "b" digunakan.