Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym artykule opisano sposób używania Copy activity w potokach Azure Data Factory i Azure Synapse do kopiowania danych z i do usługi Snowflake oraz używania Data Flow do przekształcania danych w usłudze Snowflake. Aby uzyskać więcej informacji, zobacz artykuł wprowadzający Data Factory lub Azure Synapse Analytics.
Important
Łącznik Snowflake V1 jest na etapie usuwania. Zaleca się uaktualnienie łącznika Snowflake z wersji 1 do wersji 2.
Obsługiwane możliwości
Ten łącznik Snowflake jest obsługiwany dla następujących funkcjonalności:
| Obsługiwane możliwości | środowisko IR |
|---|---|
| Copy activity (źródło/ujście) | (1) (2) |
| Przepływ danych mapowania (źródło/ujście) | ① |
| Działanie wyszukiwania | (1) (2) |
| Działanie skryptu (zastosuj wersję 1.1, gdy używasz parametru skryptu) | (1) (2) |
(1) Środowisko uruchomieniowe Azure (2) Środowisko uruchomieniowe lokalnie hostowane
W przypadku Copy activity ten łącznik Snowflake obsługuje następujące funkcje:
- Skopiuj dane z usługi Snowflake przy użyciu polecenia COPY do lokalizacji [location], aby osiągnąć najlepszą wydajność.
- Skopiuj dane do Snowflake, korzystając z polecenia COPY INTO [table] usługi Snowflake, aby uzyskać najlepszą wydajność. Obsługuje platformę Snowflake na Azure.
- Jeśli serwer proxy jest wymagany do nawiązania połączenia z usługą Snowflake z własnego Integration Runtime, należy skonfigurować zmienne środowiskowe dla HTTP_PROXY i HTTPS_PROXY na hoście Integration Runtime.
Prerequisites
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować self-hosted Integration Runtime aby nawiązać z nim połączenie. Pamiętaj, aby dodać adresy IP używane przez własne środowisko Integration Runtime do listy dozwolonych.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać do listy dozwolonych adresy IP Azure Integration Runtime.
Konto Snowflake używane dla źródła lub ujścia powinno mieć niezbędny USAGE właściwy dostęp do bazy danych i dostęp do odczytu i zapisu w schemacie oraz tabel/widoków w nim. Ponadto powinien on również być umieszczony w schemacie CREATE STAGE, aby móc utworzyć zewnętrzny etap przy użyciu URI sygnatury dostępu współdzielonego (SAS URI).
Należy ustawić następujące wartości właściwości konta
| Property | Description | Required | Default |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Określa, czy należy wymagać obiektu integracji magazynowania jako poświadczeń chmury podczas tworzenia zewnętrznego etapu o nazwie (przy użyciu funkcji CREATE STAGE) w celu uzyskania dostępu do prywatnej lokalizacji magazynowania w chmurze. | FALSE | FALSE |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Określa, czy należy użyć nazwanego etapu zewnętrznego, który odwołuje się do obiektu integracji magazynu jako poświadczeń chmury podczas ładowania danych z lub zwalniania danych do lokalizacji magazynu w chmurze prywatnej. | FALSE | FALSE |
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Wprowadzenie
Aby wykonać działanie kopiowania za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Portal Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- API REST
- Szablon menedżera zasobów Azure
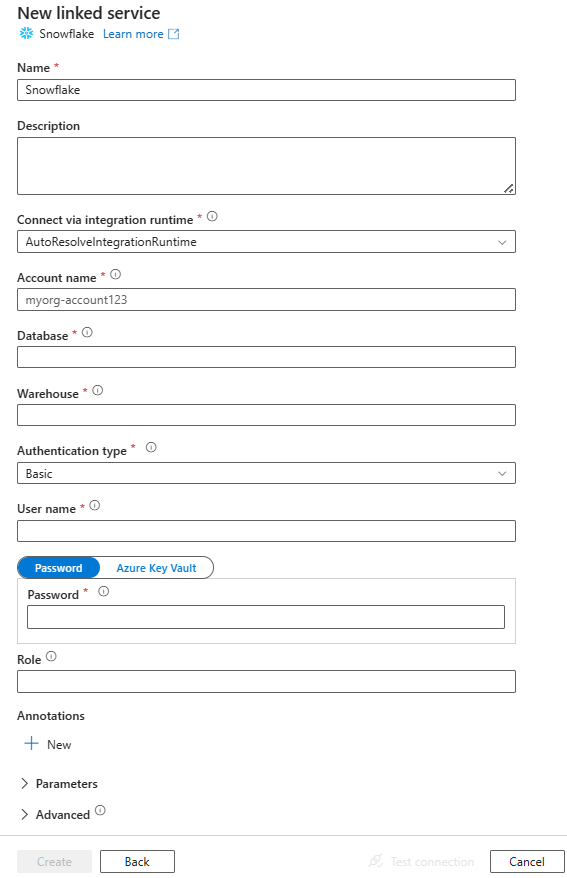
Tworzenie połączonej usługi z usługą Snowflake przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę Snowflake w interfejsie użytkownika w portalu Azure.
Przejdź do karty Zarządzanie w obszarze roboczym Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj Snowflake i wybierz łącznik Snowflake.

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach definiujących elementy specyficzne dla łącznika Snowflake.
Właściwości połączonej usługi
Te właściwości ogólne są obsługiwane w przypadku połączonej usługi Snowflake:
| Property | Description | Required |
|---|---|---|
| typ | Właściwość type musi być ustawiona na SnowflakeV2. | Yes |
| wersja | Wersja, którą określisz. Zalecamy uaktualnienie do najnowszej wersji, aby skorzystać z najnowszych ulepszeń. | Tak dla wersji 1.1 |
| accountIdentifier | Nazwa konta wraz z jego organizacją. Na przykład myorg-account123. | Yes |
| baza danych | Domyślna baza danych używana na potrzeby sesji po nawiązaniu połączenia. | Yes |
| warehouse | Domyślny magazyn wirtualny używany na potrzeby sesji po nawiązaniu połączenia. | Yes |
| authenticationType | Typ uwierzytelniania używanego do nawiązywania połączenia z usługą Snowflake. Dozwolone wartości to: Basic (Default) i KeyPair. Zapoznaj się z odpowiednimi sekcjami poniżej, aby uzyskać więcej właściwości i przykładów. | No |
| rola | Domyślna rola zabezpieczeń używana dla sesji po nawiązaniu połączenia. | No |
| gospodarz | Nazwa hosta konta Snowflake. Na przykład: contoso.snowflakecomputing.com.
.cn jest również obsługiwany. |
No |
| connectVia | Środowisko uruchomieniowe integracji używane do nawiązywania połączenia z magazynem danych. Możesz użyć środowiska Integration Runtime Azure lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli nie jest określony, zostanie użyty domyślny Azure Integration Runtime. | No |
W zależności od przypadku możesz ustawić następujące dodatkowe właściwości połączenia w połączonej usłudze.
| Property | Description | Required | Wartość domyślna |
|---|---|---|---|
| UżyjZnacznikówCzasowychUTC | Określ ją na false, aby zwrócić typ TIMESTAMP_LTZ i TIMESTAMP_TZ w właściwej strefie czasowej, a typ TIMESTAMP_NTZ bez informacji o strefie czasowej. Określ wartość true dla zwrócenia wszystkich typów sygnatur czasowych Snowflake w formacie UTC. |
No | false |
| schemat | Określa schemat sesji zapytania po nawiązaniu połączenia. | No | / |
Ten łącznik snowflake obsługuje następujące typy uwierzytelniania. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje.
uwierzytelnianie podstawowe
Aby użyć uwierzytelniania podstawowego , oprócz właściwości ogólnych opisanych w poprzedniej sekcji, określ następujące właściwości:
| Property | Description | Required |
|---|---|---|
| użytkownik | Nazwa logowania użytkownika snowflake. | Yes |
| hasło | Hasło użytkownika snowflake. Oznacz to pole jako typ SecureString, aby przechowywać je bezpiecznie. Możesz również odwołać się do sekretu przechowywanego w Azure Key Vault. | Yes |
Example:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Hasło w Azure Key Vault:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwierzytelnianie pary kluczy
Aby użyć uwierzytelniania pary kluczy, należy skonfigurować i utworzyć użytkownika uwierzytelniania pary kluczy w usłudze Snowflake, zapoznając się z uwierzytelnianiem pary kluczy i rotacją pary kluczy. Następnie zanotuj klucz prywatny i hasło (opcjonalnie), które służy do definiowania połączonej usługi.
Oprócz właściwości ogólnych opisanych w poprzedniej sekcji określ następujące właściwości:
| Property | Description | Required |
|---|---|---|
| użytkownik | Nazwa logowania użytkownika snowflake. | Yes |
| privateKey | Klucz prywatny używany do uwierzytelniania pary kluczy. Aby upewnić się, że klucz prywatny jest prawidłowy podczas wysyłania do Azure Data Factory, z uwzględnieniem faktu, że plik privateKey zawiera znaki nowej linii (\n), ważne jest, aby poprawnie sformatować zawartość privateKey w formie literału stringowego. Ten proces obejmuje jawne dodanie \n do każdego nowego wiersza. |
Yes |
| privateKeyPassphrase | Hasło używane do odszyfrowywania klucza prywatnego, jeśli jest zaszyfrowane. | No |
Example:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Note
Dla odwzorowania przepływów danych zalecamy wygenerowanie nowego klucza prywatnego RSA używając standardu PKCS#8 w formacie PEM (plik .p8).
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych .
Następujące właściwości są obsługiwane dla zestawu danych Snowflake.
| Property | Description | Required |
|---|---|---|
| typ | Właściwość type zestawu danych musi być ustawiona na SnowflakeV2Table. | Yes |
| schemat | Nazwa schematu. Zwróć uwagę, że w nazwie schematu jest uwzględniana wielkość liter. | Nie dla źródła, tak dla zlewu |
| tabela | Nazwa tabeli/widoku. Zwróć uwagę, że w nazwie tabeli jest rozróżniana wielkość liter. | Nie dla źródła, tak dla zlewu |
Example:
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Właściwości aktywności kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines. Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i odbiornik Snowflake.
Płatk śniegu jako źródło
Łącznik Snowflake wykorzystuje polecenie Snowflake COPY into [location] w celu uzyskania najlepszej wydajności.
Jeśli docelowy magazyn danych i format są natywnie obsługiwane przez polecenie Snowflake COPY, możesz użyć aktywności kopiowania, aby bezpośrednio skopiować ze Snowflake do docelowego magazynu danych. Aby uzyskać szczegółowe informacje, zobacz Bezpośrednia kopia ze Snowflake. W przeciwnym razie użyj wbudowanej etapowej kopii zapasowej z usługi Snowflake.
Aby skopiować dane z usługi Snowflake, następujące właściwości są obsługiwane w sekcji Copy activity source.
| Property | Description | Required |
|---|---|---|
| typ | Właściwość type źródła Copy activity musi być ustawiona na wartość SnowflakeV2Source. | Yes |
| kwerenda | Określa zapytanie SQL do odczytu danych z usługi Snowflake. Jeśli nazwy schematu, tabeli i kolumn zawierają małe litery, podaj identyfikator obiektu w zapytaniu, np. select * from "schema"."myTable".Wykonywanie procedury składowanej nie jest obsługiwane. |
No |
| exportSettings | Ustawienia zaawansowane używane do pobierania danych z usługi Snowflake. Można skonfigurować opcje obsługiwane przez polecenie COPY INTO, które usługa będzie stosować po wywołaniu tej instrukcji. | Yes |
| treatDecimalAsString | Określ, aby traktować typ dziesiętny jako typ ciągu w wyszukiwaniu i działaniu skryptu. Domyślna wartość to false.Ta właściwość jest obsługiwana tylko w wersji 1.1. |
No |
W obszarze exportSettings: |
||
| typ | Typ polecenia eksportu, ustawiony na SnowflakeExportCopyCommand. | Yes |
| storageIntegration | Określ nazwę integracji magazynu utworzonej w aplikacji Snowflake. Aby zapoznać się z krokami wstępnymi dotyczącymi korzystania z integracji przechowywania danych, zobacz w Konfigurowanie integracji przechowywania danych Snowflake. | No |
| additionalCopyOptions | Dodatkowe opcje kopiowania udostępniane w formie słownika par klucz-wartość. Przykłady: MAX_FILE_SIZE, NADPISAĆ. Aby uzyskać więcej informacji, zobacz Snowflake Copy Options. | No |
| additionalFormatOptions | Dodatkowe opcje formatowania pliku przekazywane poleceniu COPY jako słownik par klucz-wartość. Przykłady: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT, NULL_IF. Aby uzyskać więcej informacji, zobacz Snowflake Format Type Options (Opcje typu formatu snowflake). W przypadku używania NULL_IF wartość NULL w usłudze Snowflake jest konwertowana na określoną wartość (która musi być ujęta w pojedynczy cudzysłów) podczas zapisywania w pliku tekstowym z ogranicznikami w magazynie tymczasowym. Określoną wartość traktuje się jako NULL podczas odczytywania z pliku przejściowego do pamięci docelowej. Domyślna wartość to 'NULL'. |
No |
Note
Upewnij się, że masz uprawnienia do wykonywania następującego polecenia i uzyskiwania dostępu do INFORMATION_SCHEMA schematu i tabeli COLUMNS.
COPY INTO <location>
Bezpośrednia kopia z usługi Snowflake
Jeśli magazyn danych docelowy i format spełniają kryteria opisane w tej sekcji, możesz użyć aktywności kopiowania, aby przenieść bezpośrednio z Snowflake do magazynu docelowego. Usługa sprawdza ustawienia i kończy działanie procesu kopiowania, jeśli nie zostanie spełnione następujące kryterium:
Kiedy określisz
storageIntegrationw źródle:Magazyn danych docelowych to Azure Blob Storage, do którego odwołujesz się w zewnętrznym etapie Snowflake. Przed skopiowaniem danych należy wykonać następujące czynności:
Utwórz połączoną usługę Azure Blob Storage dla docelowego Azure Blob Storage, używając dowolnych obsługiwanych typów uwierzytelniania.
Udziel co najmniej roli Storage Blob Data Contributor głównej usłudze Snowflake w docelowej lokalizacji Azure Blob Storage Access Control (IAM).
Jeśli nie określisz
storageIntegrationw źródle:Połączoną usługą docelową jest Azure Blob Storage z uwierzytelnianiem za pomocą sygnatury dostępu współdzielonego. Jeśli chcesz bezpośrednio skopiować dane do Azure Data Lake Storage Gen2 w obsługiwanym formacie, możesz utworzyć połączoną usługę Azure Blob Storage z uwierzytelnianiem SAS, względem konta Azure Data Lake Storage Gen2, aby uniknąć używania staged copy from Snowflake.
Format danych ujścia to Parquet, tekst rozdzielany lub JSON z następującymi konfiguracjami:
- W przypadku formatu Parquet koder kompresji to None, Snappy lub Lzo.
- W przypadku formatu tekstu rozdzielanego :
-
rowDelimiterjest \r\n, lub dowolny pojedynczy znak. -
compressionmoże być bez kompresji, gzip, bzip2 lub deflate. -
encodingNamejest pozostawiona domyślna lub ustawiona na utf-8. -
quoteCharjest cudzysłowem podwójnym, pojedynczym cudzysłowem lub pustym ciągiem (bez znaku cudzysłowu).
-
- W przypadku formatu JSON kopiowanie bezpośrednie obsługuje tylko przypadek, w przypadku którego źródłowa tabela Snowflake lub wynik zapytania zawiera tylko jedną kolumnę, a typ danych tej kolumny to VARIANT, OBJECT lub ARRAY.
-
compressionmoże być bez kompresji, gzip, bzip2 lub deflate. -
encodingNamejest pozostawiona domyślna lub ustawiona na utf-8. -
filePatternw obszarze docelowym działania kopiowania jest pozostawiona jako domyślna lub ustawiona na setOfObjects.
-
W źródle operacji kopiowania
additionalColumnsnie jest określony.Nie określono mapowania kolumn.
Example:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Kopia etapowa z usługi Snowflake
Jeśli magazyn danych ujścia lub format nie jest natywnie zgodny z poleceniem Snowflake COPY, jak wspomniano w ostatniej sekcji, włącz wbudowaną kopię etapową przy użyciu tymczasowego wystąpienia usługi Blob Storage Azure. Funkcja kopiowania etapowego zapewnia również lepszą przepływność. Usługa eksportuje dane z usługi Snowflake do magazynu przejściowego, następnie kopiuje je do docelowego magazynu, a na koniec czyści tymczasowe dane z magazynu przejściowego. Zobacz Kopiowanie etapowe , aby uzyskać szczegółowe informacje na temat kopiowania danych przy użyciu przemieszczania.
Aby użyć tej funkcji, utwórz połączoną usługę Azure Blob storage, która odwołuje się do konta magazynu Azure jako tymczasowe miejsce przechowywania. Następnie określ właściwości enableStaging i stagingSettings w Copy activity.
Jeśli określisz
storageIntegrationw źródle, tymczasowy Azure Blob Storage powinien być tym, który określono na etapie zewnętrznym w Snowflake. Upewnij się, że utworzysz usługę połączoną Azure Blob Storage z dowolnym obsługiwanym uwierzytelnianiem w przypadku korzystania z środowiska Azure Integration Runtime lub z anonimowym kluczem konta, sygnaturą dostępu współdzielonego lub uwierzytelnianiem jednostki usługi podczas korzystania z własnego środowiska Integration Runtime. Ponadto przyznaj co najmniej rolę Storage Blob Data Contributor jednostce usługi Snowflake w usłudze Azure Blob Storage Access Control (IAM).Jeśli nie określisz
storageIntegrationw źródle, połączona usługa Azure Blob Storage na etapie tymczasowym musi używać uwierzytelniania za pomocą sygnatury dostępu współdzielonego, zgodnie z wymaganiami polecenia COPY dla Snowflake. Upewnij się, że udzielono odpowiednich uprawnień dostępu do aplikacji Snowflake w Azure Blob Storage przejściowym. Aby dowiedzieć się więcej na ten temat, zobacz ten artykuł.
Example:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Podczas wykonywania etapowej kopii z usługi Snowflake kluczowe jest ustawienie opcji kopiowania w lokalizacji docelowej na Scalanie plików. To ustawienie gwarantuje, że wszystkie partycjonowane pliki są poprawnie obsługiwane i scalane, uniemożliwiając problem polegający na tym, że skopiowany jest tylko ostatni plik partycjonowany.
Przykładowa konfiguracja
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Note
Niezastosowanie ustawienia zachowania kopiowania dla ujścia na scalanie plików może spowodować skopiowanie tylko ostatniego pliku partycjonowanego.
Płatki śniegu jako pochłaniacz
Łącznik Snowflake wykorzystuje polecenie Snowflake COPY INTO [table] w celu uzyskania najlepszej wydajności. Obsługuje zapisywanie danych w aplikacji Snowflake na Azure.
Jeśli źródłowy magazyn danych i format są natywnie obsługiwane przez polecenie Snowflake COPY, możesz użyć aktywności Kopiuj, aby bezpośrednio skopiować ze źródła do usługi Snowflake. Aby uzyskać szczegółowe informacje, zobacz Bezpośrednia kopia do Snowflake. W przeciwnym razie użyj wbudowanej funkcji Staged copy to Snowflake.
Aby skopiować dane do usługi Snowflake, następujące właściwości są obsługiwane w sekcji Copy activity sink.
| Property | Description | Required |
|---|---|---|
| typ | Właściwość type ujścia Copy activity ustawiona na SnowflakeV2Sink. | Yes |
| preCopyScript | Określ zapytanie SQL dla czynności kopiowania, które ma zostać uruchomione przed zapisaniem danych do Snowflake w każdym przebiegu. Użyj tej właściwości, aby wyczyścić wstępnie załadowane dane. | No |
| importSettings | Ustawienia zaawansowane używane do zapisywania danych w usłudze Snowflake. Można skonfigurować opcje obsługiwane przez polecenie COPY INTO, które usługa będzie stosować po wywołaniu tej instrukcji. | Yes |
W obszarze importSettings: |
||
| typ | Typ polecenia importu, ustawiony na SnowflakeImportCopyCommand. | Yes |
| storageIntegration | Określ nazwę integracji magazynu utworzonej w aplikacji Snowflake. Aby zapoznać się z krokami wstępnymi dotyczącymi korzystania z integracji przechowywania danych, zobacz w Konfigurowanie integracji przechowywania danych Snowflake. | No |
| additionalCopyOptions | Dodatkowe opcje kopiowania udostępniane w formie słownika par klucz-wartość. Przykłady: ON_ERROR, FORCE, ŁADUJ_NIEPEWNE_PLIKI. Aby uzyskać więcej informacji, zobacz Snowflake Copy Options. | No |
| additionalFormatOptions | Dodatkowe opcje formatów plików dostępne dla polecenia COPY, podane jako słownik par klucz-wartość. Przykłady: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Aby uzyskać więcej informacji, zobacz Snowflake Format Type Options (Opcje typu formatu snowflake). | No |
Note
Upewnij się, że masz uprawnienia do wykonywania następującego polecenia i uzyskiwania dostępu do INFORMATION_SCHEMA schematu i tabeli COLUMNS.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Bezpośrednia kopia do Snowflake
Jeśli źródłowy magazyn danych i format spełniają kryteria opisane w tej sekcji, możesz użyć aktywności kopiowania, aby bezpośrednio przenieść dane ze źródła do Snowflake. Usługa sprawdza ustawienia i kończy działanie procesu kopiowania, jeśli nie zostanie spełnione następujące kryterium:
Po określeniu
storageIntegrationw ujściu:Źródłowy magazyn danych to Azure Blob Storage, o którym mowa na etapie zewnętrznym w usłudze Snowflake. Przed skopiowaniem danych należy wykonać następujące czynności:
Utwórz Azure Blob Storage połączoną usługę dla Azure Blob Storage źródłowej z obsługiwanymi typami uwierzytelniania.
Przyznaj jednostce usługi Snowflake co najmniej rolę Czytnika danych obiektów blob w źródłowym Azure Blob Storage w Access Control (IAM).
Jeśli nie określisz
storageIntegrationujścia:Połączona usługa źródłowa jest Azure Blob Storage z uwierzytelnianiem za pomocą podpisu współdzielonego dostępu. Jeśli chcesz bezpośrednio skopiować dane z Azure Data Lake Storage Gen2 w następującym obsługiwanym formacie, możesz utworzyć powiązaną usługę Azure Blob Storage z uwierzytelnianiem SAS dla konta Azure Data Lake Storage Gen2, aby uniknąć używania etapu kopiowania do Snowflake.
Format danych źródłowych to Parquet, Rozdzielany tekst lub JSON z następującymi konfiguracjami:
W przypadku formatu Parquet koder kompresji to None lub Snappy.
W przypadku formatu tekstu rozdzielanego :
-
rowDelimiterjest \r\n, lub dowolny pojedynczy znak. Jeśli ogranicznik wierszy nie jest "\r\n",firstRowAsHeadermusi być fałszywy iskipLineCountnie jest określony. -
compressionmoże być bez kompresji, gzip, bzip2 lub deflate. -
encodingNamejest pozostawiona jako domyślna lub ustawiona na "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255". -
quoteCharjest cudzysłowem podwójnym, pojedynczym cudzysłowem lub pustym ciągiem (bez znaku cudzysłowu).
-
W przypadku formatu JSON kopiowanie bezpośrednie obsługuje jedynie sytuację, gdy docelowa tabela Snowflake ma jedną kolumnę, a typ danych tej kolumny to VARIANT, OBJECT lub ARRAY.
-
compressionmoże być bez kompresji, gzip, bzip2 lub deflate. -
encodingNamejest pozostawiona domyślna lub ustawiona na utf-8. - Nie określono mapowania kolumn.
-
W źródle Copy activity:
-
additionalColumnsnie jest określony. - Jeśli źródło jest folderem,
recursivema wartość true. -
prefix, ,modifiedDateTimeStartmodifiedDateTimeEndienablePartitionDiscoverynie są określone.
-
Example:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Kopiowanie etapowe do Snowflake
Jeśli źródłowy magazyn danych lub format nie jest natywnie zgodny z poleceniem Snowflake COPY, jak wspomniano w ostatniej sekcji, włącz wbudowaną kopię etapową przy użyciu tymczasowego wystąpienia usługi Blob Storage Azure. Funkcja kopiowania etapowego zapewnia również lepszą przepływność. Usługa automatycznie konwertuje dane w celu spełnienia wymagań dotyczących formatu danych snowflake. Następnie wywołuje polecenie COPY w celu załadowania danych do usługi Snowflake. Na koniec czyści dane tymczasowe z magazynu obiektów BLOB. Zobacz Kopiowanie z etapowaniem, aby uzyskać szczegółowe informacje na temat kopiowania danych przy użyciu etapowania.
Aby użyć tej funkcji, utwórz połączoną usługę Azure Blob storage, która odwołuje się do konta magazynu Azure jako tymczasowe miejsce przechowywania. Następnie określ właściwości enableStaging i stagingSettings w Copy activity.
Po określeniu
storageIntegrationw ujściu, tymczasowy Azure Blob Storage przejściowy powinien być taki, który został określony w zewnętrznym etapie w Snowflake. Upewnij się, że utworzysz usługę połączoną Azure Blob Storage z dowolnym obsługiwanym uwierzytelnianiem w przypadku korzystania z środowiska Azure Integration Runtime lub z anonimowym kluczem konta, sygnaturą dostępu współdzielonego lub uwierzytelnianiem jednostki usługi podczas korzystania z własnego środowiska Integration Runtime. Ponadto przyznaj roli głównej usługi Snowflake co najmniej Czytnik danych obiektów blob w przejściowej Azure Blob Storage Access Control (IAM).Jeśli nie określisz
storageIntegrationw miejscu docelowym, tymczasowa połączona z Azure Blob Storage usługa musi używać uwierzytelniania za pomocą sygnatury dostępu współdzielonego zgodnie z wymaganiami polecenia Snowflake COPY.
Example:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Mapowanie właściwości przepływu danych
Podczas przekształcania danych w przepływie danych mapowania można odczytywać dane z tabel i zapisywać je w usłudze Snowflake. Aby uzyskać więcej informacji, zobacz transformację źródła i transformację ujścia w przepływach danych mapowania. Możesz użyć zestawu danych Snowflake lub wbudowanego zestawu danych jako typu źródła i ujścia.
Przekształcanie źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło Snowflake. Można edytować te właściwości na karcie Opcje źródła. Łącznik korzysta z wewnętrznego transferu danych Snowflake.
| Name | Description | Required | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Table | W przypadku wybrania Tabela jako danych wejściowych przepływ danych pobierze wszystkie dane z tabeli określonej w zestawie danych Snowflake lub w opcjach źródła przy korzystaniu z wbudowanego zestawu danych. | No | String |
(tylko w przypadku wbudowanego zestawu danych) tableName schemaName |
| Query | Jeśli wybierzesz pozycję Zapytanie jako dane wejściowe, wprowadź zapytanie, aby pobrać dane z usługi Snowflake. To ustawienie zastępuje dowolną tabelę wybraną w zestawie danych. Jeśli nazwy schematu, tabeli i kolumn zawierają małe litery, podaj identyfikator obiektu w zapytaniu, np. select * from "schema"."myTable". |
No | String | kwerenda |
| Włącz wyodrębnianie przyrostowe (wersja zapoznawcza) | Użyj tej opcji, aby poinformować ADF o przetwarzaniu tylko tych wierszy, które uległy zmianie od czasu ostatniego uruchomienia potoku. | No | logiczny | enableCdc |
| Kolumna przyrostowa | W przypadku korzystania z funkcji wyodrębniania przyrostowego należy wybrać kolumnę typu daty, godziny lub liczbowego, której chcesz użyć jako znacznika w tabeli źródłowej. | No | String | waterMarkColumn |
| Włącz Funkcję Śledzenia Zmian Snowflake (wersja zapoznawcza) | Ta opcja umożliwia usłudze ADF wykorzystanie technologii wychwytywania zmian danych usługi Snowflake w celu przetwarzania wyłącznie danych delta od czasu poprzedniego uruchomienia potoku. Ta opcja automatycznie ładuje dane różnicowe poprzez operacje wstawiania, aktualizowania i usuwania wierszy bez konieczności używania żadnych dodatkowych kolumn. | No | logiczny | enableNativeCdc |
| Zmiany netto | W przypadku korzystania ze śledzenia zmian płatka śniegu można użyć tej opcji, aby uzyskać deduplikowane zmienione wiersze lub wyczerpujące zmiany. Odfiltrowane zmienione wiersze będą wyświetlać tylko najnowsze wersje wierszy, które uległy zmianie od określonego momentu czasu, natomiast wyczerpujące zmiany pokażą wszystkie wersje każdego wiersza, które uległy zmianie, w tym te, które zostały usunięte lub zaktualizowane. Jeśli na przykład zaktualizujesz wiersz, zobaczysz wersję usunięcia i wersję wstawienia w szczegółowych zmianach, ale tylko wersję wstawienia w zduplikowanych zmienionych wierszach. W zależności od przypadku użycia możesz wybrać opcję, która odpowiada Twoim potrzebom. Domyślna opcja to false, co oznacza wyczerpujące zmiany. | No | logiczny | netChanges |
| Uwzględnij kolumny systemowe | W przypadku korzystania ze śledzenia zmian płatka śniegu można użyć opcji systemColumns, aby kontrolować, czy kolumny strumienia metadanych dostarczone przez usługę Snowflake są uwzględniane lub wykluczone w danych wyjściowych śledzenia zmian. Domyślnie właściwość systemColumns jest ustawiona na wartość true, co oznacza, że kolumny strumienia metadanych są uwzględniane. Możesz ustawić wartość systemColumns na wartość false, jeśli chcesz je wykluczyć. | No | logiczny | systemColumns |
| Rozpocznij czytanie od początku | Ustawienie tej opcji z wyodrębnianiem przyrostowym i śledzeniem zmian spowoduje, że usługa ADF odczyta wszystkie wiersze przy pierwszym wykonywaniu potoku z włączonym wyodrębnianiem przyrostowym. | No | logiczny | skipInitialLoad |
Przykłady skryptów źródłowych Snowflake
Jeśli używasz zestawu danych Snowflake jako typu źródła, skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Jeśli używasz wbudowanego zestawu danych, skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Natywne śledzenie zmian
Azure Data Factory obsługuje teraz funkcję natywną w usłudze Snowflake znaną jako śledzenie zmian, która obejmuje śledzenie zmian w postaci dzienników. Ta funkcja płatka śniegu pozwala nam śledzić zmiany w danych w czasie, co ułatwia przyrostowe ładowanie i inspekcję danych. Aby użyć tej funkcji, po włączeniu przechwytywania zmian i wybraniu Śledzenia Zmian Snowflake, tworzymy obiekt Stream dla tabeli źródłowej, która umożliwia śledzenie zmian w źródłowej tabeli Snowflake. Następnie użyjemy klauzuli CHANGES w zapytaniu, aby pobrać tylko nowe lub zaktualizowane dane z tabeli źródłowej. Ponadto zaleca się zaplanowanie potoku tak, aby zmiany były przetwarzane w przedziale czasu przechowywania danych ustawionym dla tabeli źródłowej Snowflake, aby inaczej użytkownik nie zobaczył niespójnego zachowania w rejestrowanych zmianach.
Przekształcenie ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez sink Snowflake. Te właściwości można edytować na karcie Ustawienia . W przypadku korzystania z wbudowanego zestawu danych zobaczysz dodatkowe ustawienia, które są takie same jak właściwości opisane w sekcji właściwości zestawu danych . Łącznik korzysta z wewnętrznego transferu danych Snowflake.
| Name | Description | Required | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Metoda aktualizacji | Określ, jakie operacje są dozwolone na Twoim miejscu docelowym Snowflake. Aby zaktualizować, wstawić lub usunąć wiersze, wymagane jest przekształcenie typu 'Alter row' do oznaczania wierszy dla tych akcji. |
Yes |
true lub false |
deletable insertable updateable upsertable |
| Kolumny kluczy | W przypadku aktualizacji, operacji upsert i usuwania należy ustawić kolumnę klucza lub kolumny w celu określenia, który wiersz ma zostać zmieniony. | No | Array | keys |
| Akcja tabeli | Określa, czy należy ponownie utworzyć lub usunąć wszystkie wiersze z tabeli docelowej przed zapisem. - Brak: żadna akcja nie zostanie wykonana w tabeli. - Stwórz ponownie: tabela zostanie usunięta i utworzona ponownie. Wymagane w przypadku dynamicznego tworzenia nowej tabeli. - Truncate: Wszystkie wiersze z tabeli docelowej zostaną usunięte. |
No |
true lub false |
recreate obcinać |
Przykłady skryptów odbiorników Snowflake
W przypadku użycia zestawu danych Snowflake jako typu ujścia skojarzony skrypt przepływu danych to:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Jeśli używasz wbudowanego zestawu danych, skojarzony skrypt przepływu danych to:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Optymalizacja przepychania zapytań
Ustawiając poziom rejestrowania potoku na Brak, wykluczamy przesyłanie metryk transformacji pośredniej, uniemożliwiając potencjalne przeszkody optymalizacjom platformy Spark i włączając optymalizację wypychania zapytań zapewnianą przez usługę Snowflake. Ta optymalizacja pushdown umożliwia znaczne ulepszenia wydajności dla dużych tabel Snowflake z dużymi zestawami danych.
Note
Nie obsługujemy tabel tymczasowych w usłudze Snowflake, ponieważ są one lokalne dla sesji lub użytkownika, który je tworzy, co czyni je niedostępnymi dla innych sesji i podatnymi na zastępowanie jako zwykłe tabele przez usługę Snowflake. Chociaż Snowflake oferuje tabele przejściowe jako alternatywę, które są dostępne globalnie, wymagają jednak ręcznego usuwania, co jest sprzeczne z naszym podstawowym celem korzystania z tabel tymczasowych, jakim jest unikanie wszelkich operacji usuwania w schemacie źródłowym.
Mapowanie typów danych dla usługi Snowflake V2
Podczas kopiowania danych z Snowflake, następujące mapowania są używane z typów danych Snowflake do tymczasowych typów danych wewnątrz usługi. Aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na docelowy, zobacz Mapowanie schematu i typu danych.
| Typ danych Snowflake | Typ danych tymczasowych usługi |
|---|---|
| LICZBA (p,0) | Decimal |
| LICZBA (p,s gdzie s>0) | Decimal |
| FLOAT | Double |
| VARCHAR | String |
| CHAR | String |
| BINARY | Byte[] |
| BOOLEAN | logiczny |
| DATE | DateTime |
| TIME | TimeSpan |
| TIMESTAMP_LTZ | DateTimeOffset |
| TIMESTAMP_NTZ | DateTimeOffset |
| TIMESTAMP_TZ | DateTimeOffset |
| VARIANT | String |
| OBJECT | String |
| ARRAY | String |
Właściwości działania wyszukiwania
Aby uzyskać więcej informacji na temat właściwości, zobacz Działanie wyszukiwania.
Cykl życia i aktualizacja łącznika Snowflake
W poniższej tabeli przedstawiono etap wydania i dzienniki zmian dla różnych wersji łącznika snowflake:
| Version | Etap wydania | Dziennik zmian |
|---|---|---|
| Snowflake V1 | Removed | Nie dotyczy. |
| Snowflake V2 (wersja 1.0) | Wersja GA dostępna | • Dodaj obsługę uwierzytelniania par kluczy. • Dodaj obsługę storageIntegration w Copy activity. • Właściwości accountIdentifier, warehouse, database, schema i role służą do ustanawiania połączenia zamiast właściwości connectionstring.• Dodano obsługę liczby dziesiętnej w działaniu wyszukiwania. Typ NUMBER, zgodnie z definicją w aplikacji Snowflake, będzie wyświetlany jako ciąg w działaniu Wyszukiwania. Jeśli chcesz przekształcić go na typ liczbowy w V2, możesz użyć parametru potoku z funkcją int lub funkcją float. Na przykład , int(activity('lookup').output.firstRow.VALUE)float(activity('lookup').output.firstRow.VALUE)• Typ danych sygnatury czasowej w elemencie Snowflake jest odczytywany jako typ danych DateTimeOffset w działaniu Wyszukiwania i Skryptu. Jeśli nadal musisz użyć wartości DateTime jako parametru w potoku po uaktualnieniu do V2, możesz przekonwertować typ DateTimeOffset na typ DateTime przy użyciu funkcji formatDateTime (zalecane) lub funkcji concat. Na przykład: formatDateTime(activity('lookup').output.firstRow.DATETIMETYPE), concat(substring(activity('lookup').output.firstRow.DATETIMETYPE, 0, 19), 'Z') • LICZBA (p,0) jest odczytywana jako typ danych dziesiętnych. • TIMESTAMP_LTZ, TIMESTAMP_NTZ i TIMESTAMP_TZ są odczytywane jako typ danych DateTimeOffset. • Parametry skryptu nie są obsługiwane w działaniu typu skrypt. Alternatywnie użyj wyrażeń dynamicznych dla parametrów skryptu. Aby uzyskać więcej informacji, zobacz Wyrażenia i funkcje w Azure Data Factory i Azure Synapse Analytics. • Wykonywanie wielu instrukcji SQL w działaniu skryptu nie jest obsługiwane. |
| Snowflake V2 (wersja 1.1) | Wersja GA dostępna | • Dodaj obsługę parametrów skryptu. • Dodano obsługę wykonywania wielu instrukcji w działaniu skryptu. • Dodaj właściwość treatDecimalAsString w aktywności Lookup i Script. • Dodaj dodatkową właściwość UseUtcTimestamps połączenia. |
Uaktualnianie łącznika Snowflake z wersji 1 do wersji 2
Aby uaktualnić łącznik Snowflake z wersji 1 do wersji 2, możesz przeprowadzić aktualizację równoległą lub aktualizację w miejscu.
Uaktualnianie równoległe
Aby przeprowadzić uaktualnienie równoległe, wykonaj następujące kroki:
- Utwórz nową połączoną usługę Snowflake i skonfiguruj ją, odwołując się do właściwości połączonej usługi w wersji 2.
- Utwórz zestaw danych na podstawie nowo utworzonej połączonej usługi Snowflake.
- Zastąp nowo utworzoną połączoną usługę i zestaw danych istniejącymi w potokach przeznaczonych dla obiektów V1.
Uaktualnienie na miejscu
Aby przeprowadzić aktualizację na miejscu, należy zmodyfikować istniejące definicje powiązanej usługi i zaktualizować zestaw danych, aby wykorzystać nową wersję powiązanej usługi.
Zaktualizuj typ z Snowflake na SnowflakeV2.
Zmodyfikuj ładunek połączonej usługi z formatu V1 do wersji 2. Możesz wypełnić każde pole z interfejsu użytkownika po zmianie typu wymienionego powyżej lub zaktualizować ładunek bezpośrednio za pośrednictwem edytora JSON. Zapoznaj się z sekcją Właściwości połączonej usługi w tym artykule, aby zapoznać się z obsługiwanymi właściwościami połączenia. Następujące przykłady pokazują różnice w ładunku dla połączonych usług Snowflake w wersjach V1 i V2.
Ładunek JSON połączonej usługi Snowflake v1:
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Ładunek JSON połączonej usługi Snowflake w wersji 2:
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Zaktualizuj zestaw danych, aby korzystał z nowej połączonej usługi. Możesz utworzyć nowy zestaw danych na podstawie nowo utworzonej połączonej usługi lub zaktualizować właściwość typu istniejącego zestawu danych z tabeli SnowflakeTable do tabeli SnowflakeV2Table.
Note
Podczas przenoszenia połączonych usług, sekcja parametrów szablonu zastąpienia może wyświetlać tylko właściwości bazy danych. Możesz rozwiązać ten problem, ręcznie edytując parametry. Po wykonaniu sekcji Zmiana parametrów szablonu zostaną wyświetlone ciągi połączenia.
Uaktualnij łącznik Snowflake V2 z wersji 1.0 do wersji 1.1
Na stronie Edytowanie połączonej usługi wybierz pozycję 1.1 dla wersji. Aby uzyskać więcej informacji, zobacz Właściwości połączonej usługi.
Treści powiązane
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i miejsca docelowe przez Copy activity, zobacz obsługiwane magazyny danych i formaty.