Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym samouczku użyjesz portalu Azure do utworzenia potoku Azure Data Factory, który wykonuje notatnik Databricks w klastrze zadania Databricks. Przekazuje również parametry Azure Data Factory do notatnika Azure Databricks podczas wykonywania.
W tym samouczku wykonasz następujące kroki:
Tworzenie fabryki danych.
Utwórz potok, który używa aktywności notesu Databricks.
Uruchom potok.
Monitoruj przebieg potoku.
Jeśli nie masz subskrypcji Azure, przed rozpoczęciem utwórz konto free.
Uwaga
Aby uzyskać szczegółowe informacje na temat używania działania notesu usługi Databricks, w tym używania bibliotek i przekazywania parametrów wejściowych i wyjściowych, zapoznaj się z dokumentacją działania notesu usługi Databricks.
Wymagania wstępne
- Azure Databricks środowisko robocze. Utwórz obszar roboczy usługi Databricks lub użyj istniejącego. Tworzysz notatnik Python w swoim obszarze roboczym Azure Databricks. Następnie uruchamiasz notatnik i przekazujesz do niego parametry przy użyciu Azure Data Factory.
Tworzenie fabryki danych
Uruchom Microsoft Edge lub Google Chrome przeglądarki internetowej. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko w przeglądarkach internetowych Microsoft Edge i Google Chrome.
Wybierz Utwórz zasób w menu portalu Azure, a następnie wybierz pozycję Analytics>Data Factory:
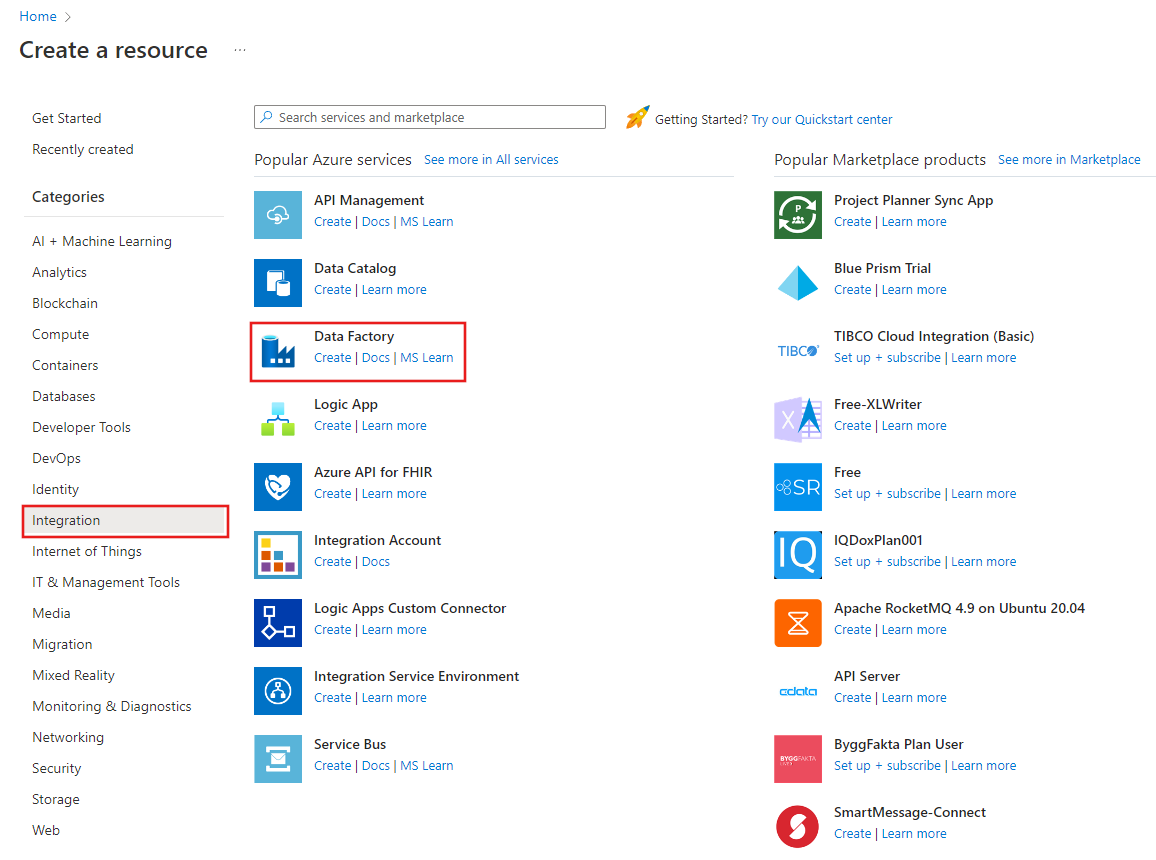
Na stronie Utwórz usługę Data Factory, na karcie Podstawy, wybierz Subskrypcję Azure, w której chcesz utworzyć Data Factory.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
Wybierz istniejącą grupę zasobów z listy rozwijanej.
Wybierz pozycję Utwórz nową i wprowadź nazwę nowej grupy zasobów.
Aby dowiedzieć się więcej o grupach zasobów, zobacz Za pomocą grup zasobów do zarządzania zasobami Azure.
W obszarze Region wybierz lokalizację fabryki danych.
Lista zawiera tylko lokalizacje obsługiwane przez usługę Data Factory oraz lokalizacje, w których będą przechowywane dane meta Azure Data Factory. Skojarzone magazyny danych (takie jak Azure Storage i Azure SQL Database) i obliczenia (takie jak Azure HDInsight), których usługa Data Factory używa, może działać w innych regionach.
W polu Nazwa wprowadź wartość ADFTutorialDataFactory.
Nazwa fabryki danych Azure musi być unikatowa na całym świecie. Jeśli zostanie wyświetlony następujący błąd, zmień nazwę fabryki danych (na przykład użyj <nazwy>ADFTutorialDataFactory). Artykuł Usługa Data Factory — reguły nazewnictwa zawiera reguły nazewnictwa artefaktów usługi Data Factory.
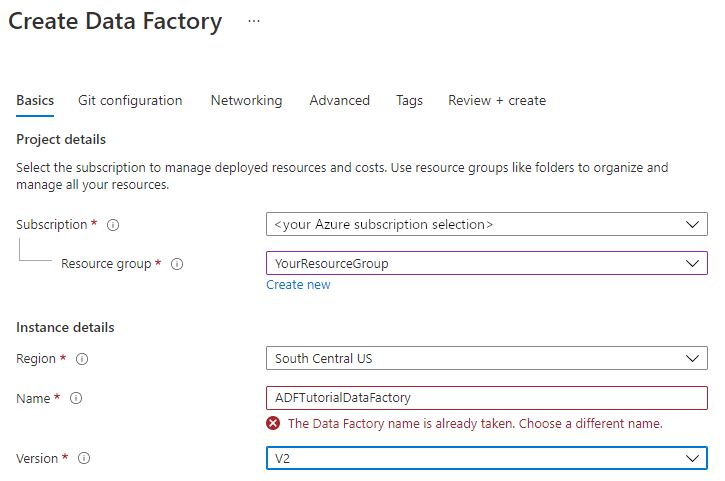
W obszarze Wersja wybierz pozycję V2.
Wybierz pozycję Dalej: Konfiguracja usługi Git, a następnie zaznacz pole wyboru Skonfiguruj usługę Git później .
Wybierz pozycję Przejrzyj i utwórz, a następnie wybierz pozycję Utwórz po zakończeniu walidacji.
Po zakończeniu tworzenia wybierz pozycję Przejdź do zasobu , aby przejść do strony Fabryka danych . Wybierz kafelek Otwórz Azure Data Factory Studio, aby uruchomić aplikację interfejsu użytkownika Azure Data Factory na osobnej karcie przeglądarki.

Tworzenie połączonych usług
W tej sekcji utworzysz połączoną usługę Databricks. Ta połączona usługa zawiera informacje o połączeniu z klastrem usługi Databricks:
Tworzenie połączonej usługi Azure Databricks
Na stronie głównej przejdź do karty Zarządzanie w panelu po lewej stronie.
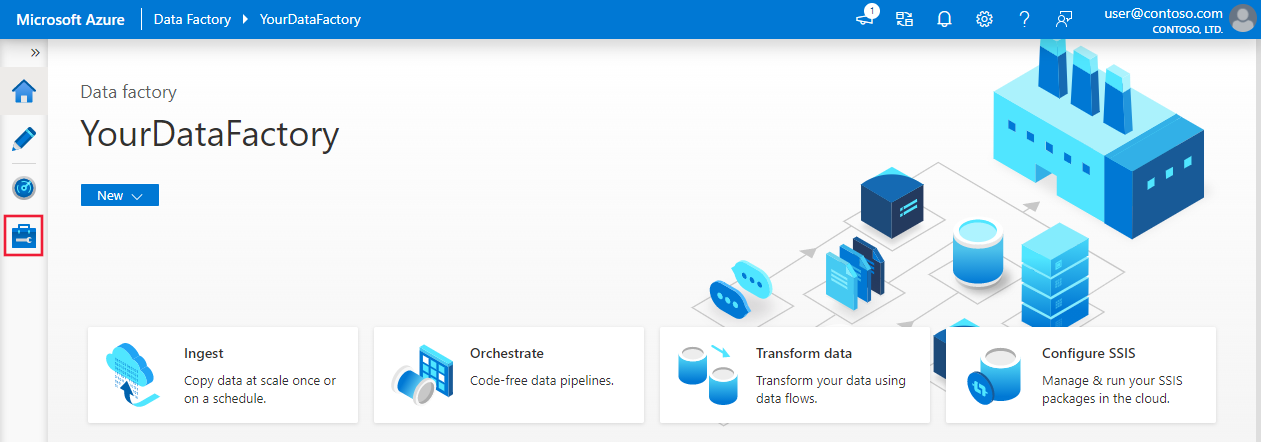
Wybierz pozycję Połączone usługi w obszarze Połączenia, a następnie wybierz pozycję + Nowy.
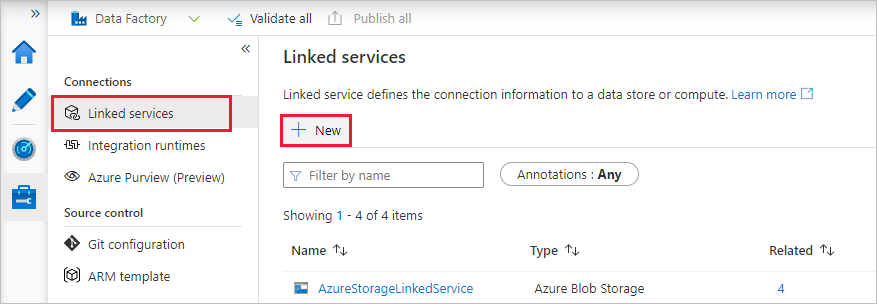
W oknie Nowa połączona usługa wybierz Compute>Azure Databricks a następnie wybierz Continue.

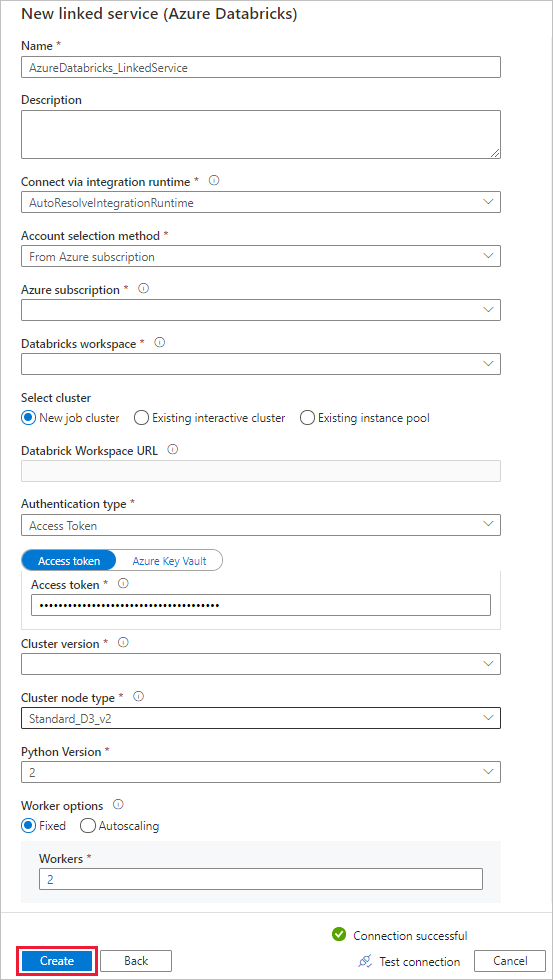
W oknie Nowa połączona usługa wykonaj następujące kroki:
W polu Nazwa wprowadź AzureDatabricks_LinkedService.
Wybierz odpowiedni obszar roboczy usługi Databricks, w którym uruchomisz notes.
W obszarze Wybierz klaster wybierz Nowy klaster zadań.
W przypadku adresu URL obszaru roboczego usługi Databricks informacje powinny być wypełniane automatycznie.
W przypadku typu Uwierzytelnianie, jeśli wybierzesz Token dostępu, wygeneruj go z obszaru roboczego Azure Databricks. Procedurę można znaleźć tutaj. W przypadku tożsamości zarządzanej tożsamości usługi i przydzielonej tożsamości zarządzanej przez użytkownika, przyznaj rolę Contributor obu tożsamościom w menu Kontrola dostępu zasobu Azure Databricks.
W polu Wersja klastra wybierz wersję, której chcesz użyć.
W polu Typ węzła klastra wybierz pozycję Standard_D3_v2 w kategorii Ogólnego przeznaczenia (HDD) dla tego samouczka.
Dla Pracowników wpisz 2.
Wybierz pozycję Utwórz.
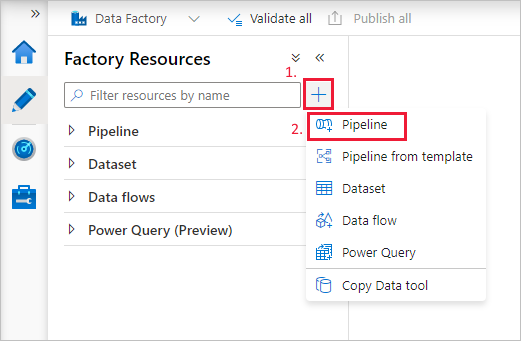
Stwórz pipeline
Wybierz przycisk + (znak plus), a następnie wybierz pozycję Potok w menu.
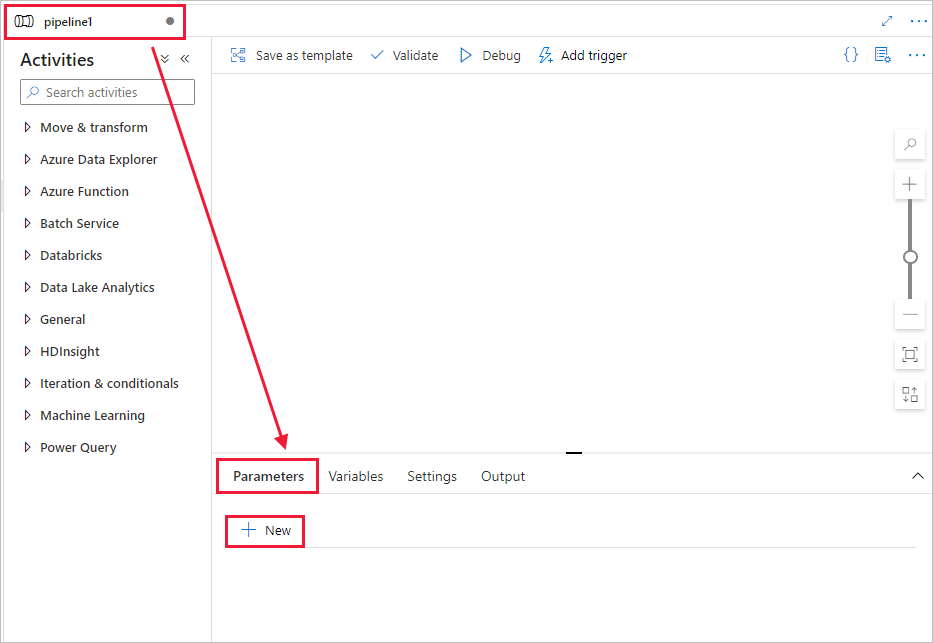
Utwórz parametr do użycia w potoku. Później przekażesz ten parametr do działania notesu usługi Databricks. W pustym pipeline wybierz kartę Parametry, następnie wybierz + Nowy i nadaj mu nazwę 'name'.
W przyborniku Działania rozwiń pozycję Databricks. Przeciągnij działanie Notes z przybornika Działania na powierzchnię projektanta potoku.
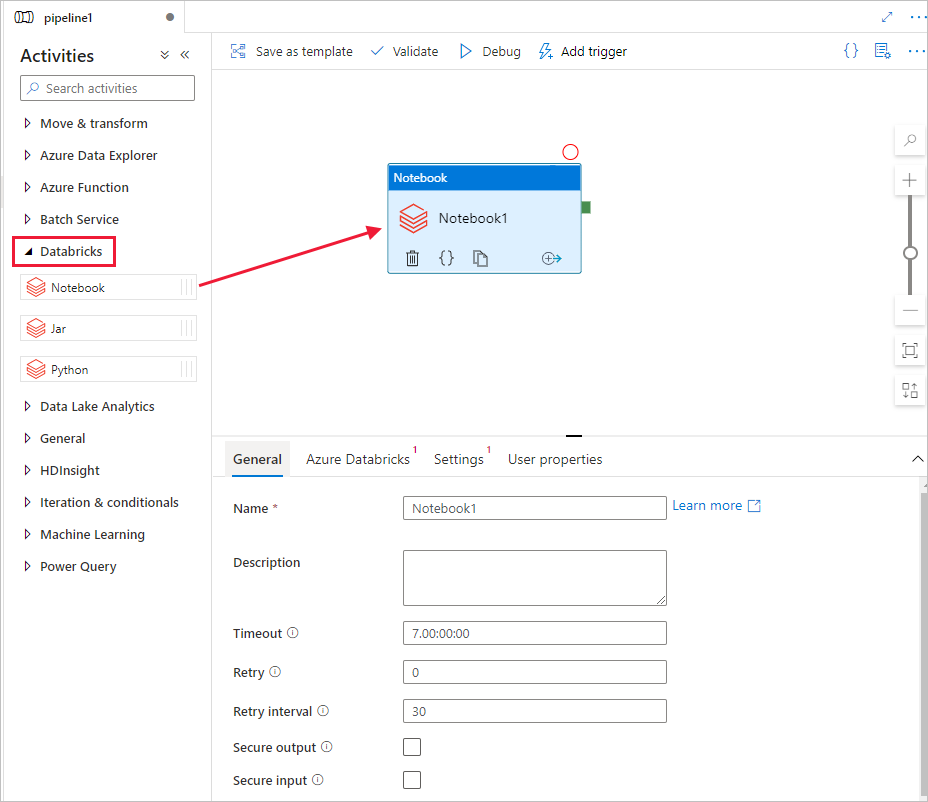
W oknie właściwości działania DatabricksNotebook na dole, wykonaj następujące kroki:
Przejdź do karty Azure Databricks.
Wybierz AzureDatabricks_LinkedService (utworzoną w poprzedniej procedurze).
Przejdź do karty Ustawienia.
Użyj opcji Przeglądaj, aby wybrać Ścieżkę notesu usługi Databricks. W tym miejscu utworzymy notes i określimy ścieżkę. Otrzymasz ścieżkę notatnika, wykonując kilka następnych kroków.
Uruchom obszar roboczy Azure Databricks.
Utwórz nowy folder w miejscu pracy i nadaj mu nazwę adftutorial.
Utwórz nowy notes. Nadajmy mu nazwę mynotebook. Kliknij prawym przyciskiem myszy folder adftutorial , a następnie wybierz polecenie Utwórz.
W nowo utworzonym notesie „mynotebook” dodaj następujący kod:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)Ścieżka notesu w tym przypadku to /adftutorial/mynotebook.
Przełącz się z powrotem do narzędzia tworzenia interfejsu użytkownika usługi Data Factory. Przejdź do karty Ustawienia w działaniu Notebook1 .
a. Dodaj parametr do działania Notes. Używasz tego samego parametru, który wcześniej dodałeś do potoku.
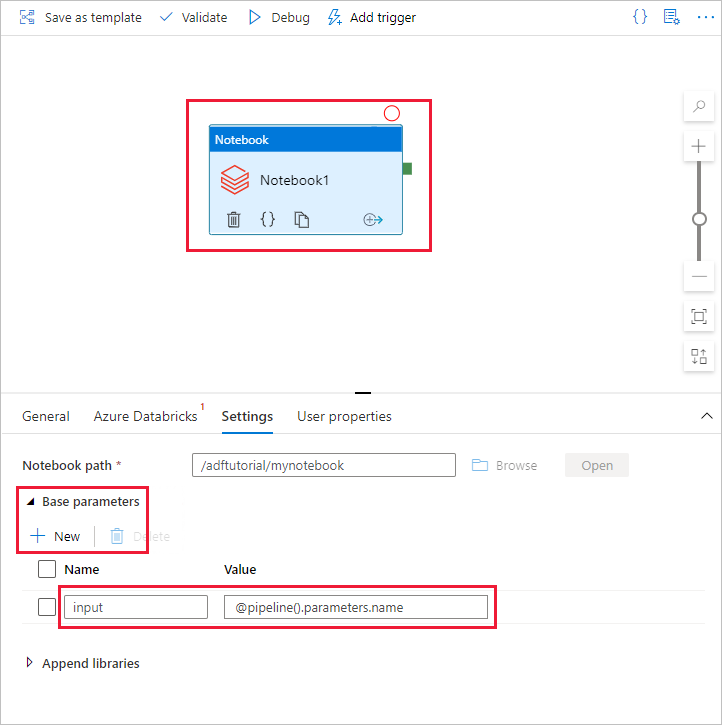
b. Nadaj parametrowi nazwę input i podaj wartość jako wyrażenie @pipeline().parameters.name.
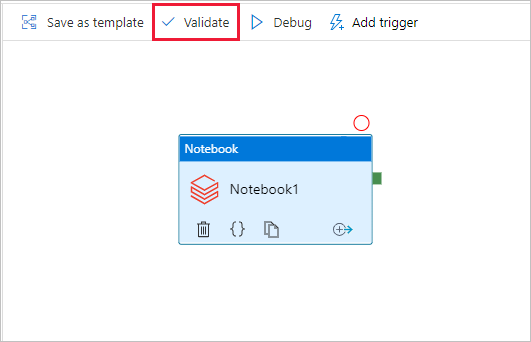
Aby zweryfikować pipeline, wybierz przycisk Weryfikuj na pasku narzędzi. Aby zamknąć okno weryfikacji, wybierz przycisk Zamknij .
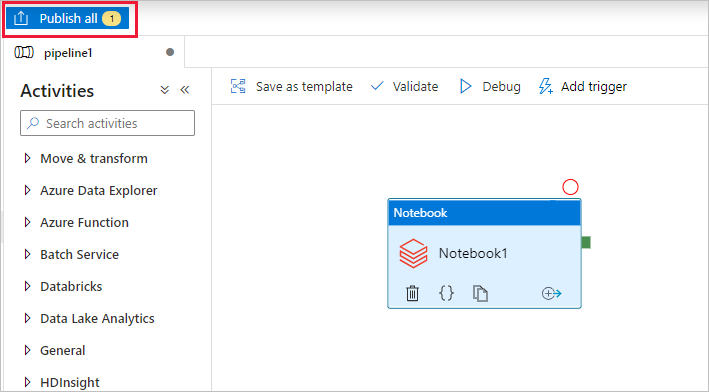
Wybierz opcję Publikuj wszystko. Interfejs użytkownika usługi Data Factory publikuje jednostki (połączone usługi i potok) w usłudze Azure Data Factory.
Wyzwól uruchomienie potoku
Wybierz pozycję Dodaj wyzwalacz na pasku narzędzi, a następnie wybierz pozycję Wyzwól teraz.
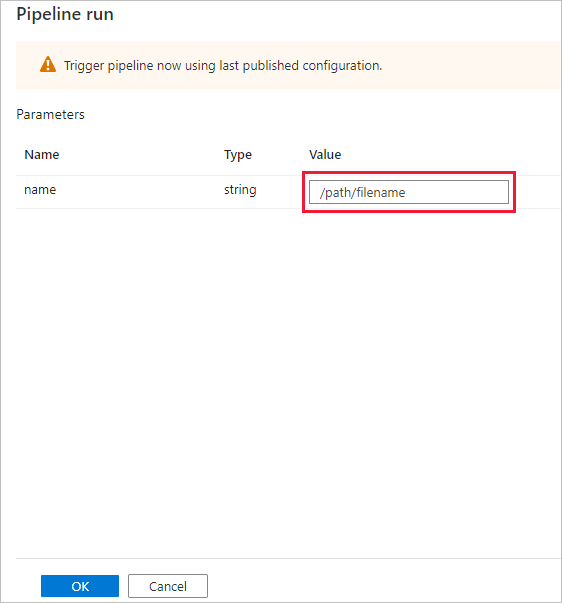
W oknie dialogowym Pipeline run pojawia się zapytanie o parametr name. Jako parametru użyj w tym miejscu wartości /path/filename. Wybierz przycisk OK.
Monitorowanie działania potoku
Przejdź do karty Monitor. Upewnij się, że zobaczysz przebieg potoku. Utworzenie klastra zadań usługi Databricks, w którym jest wykonywany notatnik, trwa około 5–8 minut.
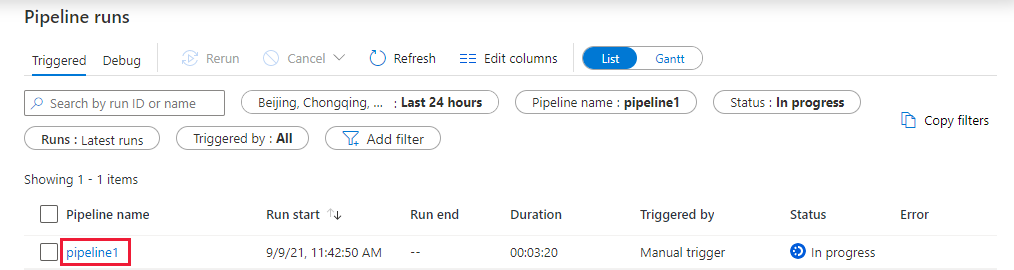
Okresowo wybieraj opcję Odśwież, aby sprawdzić status uruchomienia potoku.
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link pipeline1 w kolumnie Nazwa potoku.
Na stronie Uruchomienia działań wybierz Dane wyjściowe w kolumnie Nazwa działania, aby wyświetlić dane wyjściowe każdego działania, a link do dzienników usługi Databricks można znaleźć w okienku Dane wyjściowe dla bardziej szczegółowych dzienników Spark.
Możesz wrócić do widoku przebiegów potoku, wybierając Wszystkie przebiegi potoku w menu okruszków u góry strony.
Sprawdzanie danych wyjściowych
Możesz zalogować się do obszaru roboczego Azure Databricks, przejść do Job Runs i zobaczyć stan Job jako w oczekiwaniu na wykonanie, uruchomiony lub zakończony.
Możesz wybrać nazwę zadania i przejść, aby wyświetlić dalsze szczegóły. Po pomyślnym uruchomieniu można zweryfikować przekazane parametry i dane wyjściowe notesu Python.
Podsumowanie
Potok w tym przykładzie uruchamia aktywność Notatnika Databricks i przekazuje do niego parametr. Nauczyłeś się jak:
Tworzenie fabryki danych.
Utwórz potok, który używa działania notesu Databricks.
Uruchom potok.
Monitoruj przebieg potoku.