Datalandningszoner
Datalandningszoner är anslutna till din datahanteringslandningszon efter VNet-peering (virtuellt nätverk). Varje datalandningszon anses vara en landningszon som är relaterad till Azures landningszonsarkitektur.
Viktigt
Innan du etablerar en datalandningszon kontrollerar du att din DevOps- och CI/CD-driftsmodell är på plats och att en landningszon för datahantering distribueras.
Varje datalandningszon har flera lager som möjliggör flexibilitet för tjänstdataintegreringar och dataprodukter som den innehåller. Du kan distribuera en ny datalandningszon med en standarduppsättning tjänster som gör att datalandningszonen kan börja mata in och analysera data.
Din Azure-prenumeration som är associerad med din datalandningszon har följande struktur:
| Skikt | Obligatoriskt | Resursgrupper |
|---|---|---|
| Kärntjänster | Ja | |
| Dataprogram | Valfritt |
|
| Visualisering | Valfritt |
Anteckning
Ett dataprogram producerar en eller flera dataprodukter.
Arkitekturen för datalandningszoner illustrerar lagren, deras resursgrupper och tjänster som varje resursgrupp innehåller. Arkitekturen ger också en översikt över alla grupper och roller som är associerade med din datalandningszon, plus omfattningen av deras åtkomst till dina kontroll- och dataplan.

Tips
Innan du distribuerar en datalandningszon bör du överväga antalet inledande datalandningszoner som du vill distribuera.
Använd den här arkitekturen som utgångspunkt. Ladda ned Visio-filen och ändra den så att den passar dina specifika affärs- och tekniska krav när du planerar implementeringen av din datalandningszon.
Kärntjänstlagret innehåller alla tjänster som krävs för att aktivera din datalandningszon inom ramen för analys i molnskala. I följande tabell visas de resursgrupper som tillhandahåller standardpaketet med tillgängliga tjänster i varje datalandningszon som du distribuerar.
| Resursgrupp | Obligatoriskt | Beskrivning |
|---|---|---|
network-rg |
Ja | Nätverk |
databricks-monitoring-rg |
Valfritt | Övervakning för Azure Databricks-arbetsytor |
hive-rg |
Valfritt | Hive-metaarkiv för Azure Databricks |
storage-rg |
Ja | Datasjötjänster |
external-data-rg |
Ja | Ladda upp inmatningslagring |
runtimes-rg |
Ja | Delade integreringskörningar |
mgmt-rg |
Ja | CI/CD-agenter |
metadata-ingestion-rg |
Valfritt | Dataagnostisk inmatning |
databricks-monitoring-rg |
Valfritt | Log Analytics-arbetsyta för databricks-arbetsytor i landningszonen |
shared-synapse-rg |
Valfritt | Delad Azure Synapse |
shared-databricks-rg |
Valfritt | Delad Azure Databricks-arbetsyta |
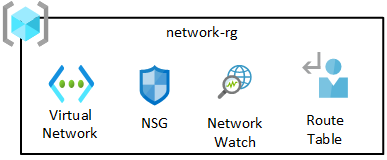
Nätverksresursgruppen innehåller kärnkomponenter, inklusive Azure Network Watcher, nätverkssäkerhetsgrupper (NSG) och ett virtuellt nätverk. Alla dessa tjänster distribueras till en enda resursgrupp.
Det virtuella nätverket i din datalandningszon peerkopplas automatiskt med datahanteringslandningszonens virtuella nätverk och anslutningsprenumerationens virtuella nätverk.
Den här resursgruppen är valfri och distribueras endast med Azure Databricks.
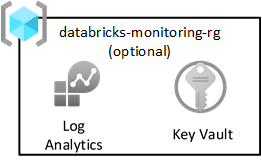
Mönstret i Azure-landningszonen rekommenderar att du skickar alla loggar till en central Log Analytics-arbetsyta. Varje datalandningszon innehåller dock även en övervakningsresursgrupp för att samla in Spark-loggar från Databricks. Varje resursgrupp innehåller en delad Log Analytics-arbetsyta och Azure Key Vault för att lagra Log Analytics-nycklar.
Viktigt
Använd endast Log Analytics-arbetsytan i databricks-övervakningsresursgruppen för att samla in Azure Databricks Spark-loggar.
Mer information finns i Övervaka Azure Databricks.
Den här resursgruppen är valfri och bör endast distribueras med Azure Databricks.
Hive-metaarkivet för Azure Databricks etablerar en Azure Database for MySQL-databas och ett nyckelvalv. Alla Azure Databricks-arbetsytor i din datalandningszon använder det här metaarkivet som sitt externa Apache Hive-metaarkiv.
Mer information finns i Externt Apache Hive-metaarkiv.
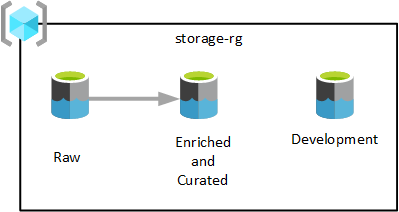
Som du ser i föregående diagram etableras tre Azure Data Lake Storage Gen2-konton i en resursgrupp för data lake-tjänster. Data som transformeras i olika steg sparas i en av datalandningszonens datasjöar. Data är tillgängliga för användning av dina analys-, datavetenskaps- och visualiseringsteam.
Datasjölager använder olika terminologi beroende på teknik och leverantör. Den här tabellen innehåller vägledning om hur du tillämpar villkor för analys i molnskala:
| Analys i molnskala | Data Lake | Andra termer | beskrivning |
|---|---|---|---|
| Raw | Brons | Landning och överensstämmelse | Inmatningstabeller |
| Berikad | Silver | Standardiseringszon | Förfinade tabeller. Lagrade fullständiga entiteter, förbrukningsklara postuppsättningar från arkivhandlingssystem. |
| Modererad | Guld | Produktzon | Funktions- eller aggregerade tabeller. Primär zon för program, team och användare att använda dataprodukter. |
| Utveckling | -- | Utvecklingszon | Plats för datatekniker och forskare, som består av både en sandbox-analys och en produktutvecklingszon. |
Anteckning
I föregående diagram har varje datalandningszon tre datasjöar. Beroende på dina krav kanske du vill konsolidera dina råa, berikade och kuraterade lager till ett lagringskonto och underhålla ett annat lagringskonto som kallas "utveckling" för datakonsumenter för att ta in andra användbara dataprodukter.
Mer information finns i:
- Översikt över Azure Data Lake Storage för analys i molnskala
- Datastandardisering
- Etablera Azure Data Lake Storage Gen2-konton för varje datalandningszon
- Viktiga överväganden för Azure Data Lake Storage
- Åtkomstkontroll och datasjökonfigurationer i Azure Data Lake Storage
Datautgivare från tredje part måste landa data på din plattform så att dina dataprogramteam kan hämta dem till sina datasjöar. Som du ser i följande diagram kan du etablera bloblager för tredje part i resursgruppen för inmatning av inmatning.
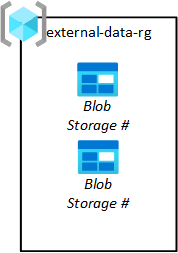
Dina dataprogramteam begär dessa lagringsblobar. Deras begäranden godkänns sedan av ditt team för datalandningszoner. Data bör tas bort från dess källlagringsblob när de har hämtats från lagringsbloben till rå.
Viktigt
Eftersom Azure Storage-blobar etableras efter behov bör du först distribuera en tom resursgrupp för lagringstjänster i varje datalandningszon.
Distribuera en virtuell dator med lokalt installerade integrationskörningar till din datalandningszon. Värd för den i resursgruppen för delad integrering. Med den här distributionen kan du snabbt registrera dataprodukter till din datalandningszon.
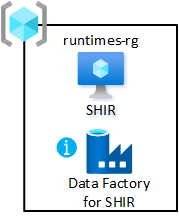
Så här aktiverar du resursgruppen:
- Skapa minst en Azure Data Factory i datalandningszonens resursgrupp för delad integrering. Använd den bara för att länka den delade lokala integrationskörningen, inte för datapipelines.
- Skapa och konfigurera en lokalt installerad integrationskörning på den virtuella datorn.
- Associera den lokala integrationskörningen med Azure-datafabriker i dina datalandningszoner.
- Konfigurera Azure Automation för att regelbundet uppdatera den lokalt installerade integrationskörningen.
Anteckning
Distributionen ovan ger en distribution av en virtuell dator med lokalt installerade integrationskörningar. Du kan associera en lokalt installerad integrationskörning med flera lokala datorer eller virtuella datorer i Azure. Dessa datorer kallas noder. Du kan ha upp till fyra noder associerade med en lokalt installerad integrationskörning. Fördelarna med att ha flera noder på lokala datorer som har en gateway installerad för en logisk gateway är:
- Högre tillgänglighet för den lokalt installerade integrationskörningen så att den inte längre är den enda felpunkten i din stordatalösning eller molndataintegrering. Den här tillgängligheten säkerställer kontinuitet när du använder upp till fyra noder.
- Bättre prestanda och dataflöde under dataflytt mellan lokala datalager och molndatalager. Få mer information om prestandajämförelser.
Du kan associera flera noder genom att installera den lokalt installerade integrationskörningsprogramvaran från Download Center. Registrera den sedan med någon av de autentiseringsnycklar som hämtades från cmdleten New-AzDataFactoryV2IntegrationRuntimeKey enligt beskrivningen i självstudien.
Ytterligare information beskrivs i Azure Datafactory Hög tillgänglighet och skalbarhet.
Viktigt
Distribuera delade integrationskörningar så nära datakällan som möjligt. Distributionen begränsar inte distributionen av integreringskörningar i en datalandningszon eller i moln från tredje part. I stället ger den en reserv för molnbaserade datakällor i regionen.
CI/CD-agenter hjälper dig att distribuera dataprogram och ändringar i datalandningszonen.
Mer information finns i Azure Pipeline-agenter.
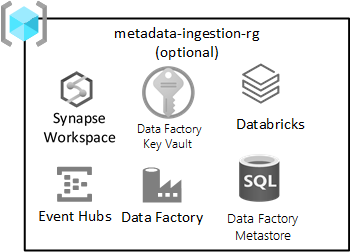
Den här resursgruppen är valfri och förbjuder inte att du distribuerar din landningszon.
Den här resursgruppen gäller om du har (eller utvecklar) en dataagnostisk inmatningsmotor för automatisk inmatning av data baserat på registrering av metadata (inklusive niska veze, sökväg för att kopiera data från och till och inmatningsschema. Inmatnings- och bearbetningsresursgruppen har viktiga tjänster för den här typen av ramverk.
Distribuera en Azure SQL Database-instans för att lagra metadata som används av Azure Data Factory. Etablera ett Azure Key Vault för att lagra hemligheter som rör automatiserade inmatningstjänster. Dessa hemligheter kan vara:
- Autentiseringsuppgifter för Azure Data Factory-metaarkiv
- Autentiseringsuppgifter för tjänstens huvudnamn för den automatiserade inmatningsprocessen
Mer information finns i Så här stöder automatiserade inmatningsramverk analys i molnskala i Azure.
Tjänster som ingår i den här resursgruppen omfattar:
| Tjänst | Obligatoriskt | Riktlinjer |
|---|---|---|
| Azure Data Factory | Ja | Azure Data Factory är din orkestreringsmotor för dataagnostisk inmatning. |
| Azure SQL-databas | Ja | Azure SQL DB är metaarkivet för Azure Data Factory. |
| Event Hubs eller IoT Hub | Valfritt | Event Hubs eller IoT Hub kan tillhandahålla direktuppspelning i realtid till Event Hubs, samt batch- och strömningsbearbetning via en databricks-arbetsyta. |
| Azure Databricks | Valfritt | Du kan distribuera Azure Databricks eller Azure Synapse Spark för användning med din dataagnostiska inmatningsmotor. |
| Azure Synapse | Valfritt | Du kan distribuera Azure Databricks eller Azure Synapse Spark att använda med den dataagnostiska inmatningsmotorn. |
Den här resursgruppen är valfri och distribueras endast med Azure Databricks. Alla i din datalandningszon kan använda en Databricks-arbetsyta.
Azure Databricks är en viktig konsument av Azure Data Lake Storage-tjänsten. Atomiska filåtgärder är optimerade för Spark-analysmotorer. Den här optimeringen påskyndar slutförandet av Spark-jobb som Azure Databricks-tjänsten har problem med.
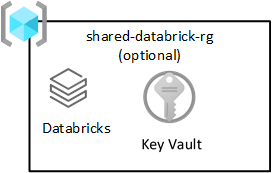
Viktigt
En Azure Databricks-arbetsyta med namnet Azure Databricks-arbetsytan (analys) etableras för alla dataforskare och DataOps, som visas i resursgruppen delade produkter.
Du kan konfigurera den här arbetsytan så att den ansluter till Azure Data Lake med hjälp av antingen Microsoft Entra-genomströmning eller tabellåtkomstkontroll. Beroende på ditt användningsfall kan du konfigurera villkorlig åtkomst som ett annat säkerhetsmått.
Följ metodtipsen för analys i molnskala för att integrera Azure Databricks:
Mönstret i Azure-landningszonen rekommenderar att du skickar alla loggar till en central Log Analytics-arbetsyta. Varje datalandningszon innehåller dock också en övervakningsresursgrupp för att samla in Spark-loggar från Databricks.
Den här resursgruppen är valfri.
Under den första installationen av en datalandningszon distribueras en enda Azure Synapse Analytics-arbetsyta för användning av alla dataanalytiker och forskare i resursgruppen för delade produkter.
Du kan konfigurera fler synapse-arbetsytor för dataprodukter om kostnadshantering och omdebitering krävs. Dina dataprogramteam kan använda dedikerade Azure Synapse Analytics-arbetsytor för att skapa dedikerade Azure SQL Database-pooler som ett läsdatalager som används av visualiseringslagret.
Viktigt
Förhindra användning av din delade Azure Synapse-arbetsyta för att skapa dataprodukter genom att låsa arbetsytan så att endast SQL-frågor på begäran tillåts. Det finns bara för exploaterande ändamål.
Varje datalandningszon kan ha flera dataprodukter. Du kan skapa dessa dataprodukter genom att mata in data från källan. Du kan också skapa dataprodukter från andra dataprodukter inom samma datalandningszon eller från andra datalandningszoner. Dataproduktens skapande av dataprodukter är föremål för godkännande av dataförvaltare.
Din resursgruppsprodukt för dataprodukter innehåller alla tjänster som krävs för att göra dataprodukten. Till exempel krävs en Azure Database för MySQL, som används av ett visualiseringsverktyg. Data måste matas in och transformeras innan de hamnar i mySQL-databasen. I det här fallet kan du distribuera Azure Database for MySQL och en Azure Data Factory till dataproduktresursgruppen.
Tips
Om du väljer att inte implementera en dataagnostikmotor för att mata in en gång från driftkällor, eller om komplexa anslutningar inte underlättas i din dataagnostikmotor, skapar du ett källjusterat dataprogram. Mer information finns i Dataprogram (källjusterade)
Mer information om hur du registrerar dataprodukter finns i Dataprodukter i molnskala i Azure.
En tom visualiseringsresursgrupp skapas för varje datalandningszon. Fyll i den här resursgruppen med tjänster som du behöver för att implementera visualiseringslösningen. Med ditt befintliga virtuella nätverk kan din lösning ansluta till dataprodukter.
Den här resursgruppen kan vara värd för virtuella datorer för visualiseringstjänster från tredje part.
Tips
På grund av licenskostnader kan det vara mer ekonomiskt att distribuera visualiseringsprodukter från tredje part till landningszonen för datahantering och att dessa produkter ansluter mellan datalandningszoner för att hämta data tillbaka.