訓練
模組
使用 Azure Data Factory 大規模進行無程式碼的轉換 - Training
使用 Azure Data Factory 或 Azure Synapse 管線大規模執行無程式碼的轉換
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用 (部分機器翻譯)!
Azure Data Factory 和 Azure Synapse Pipelines 中均可使用資料流。 本文適用於對應資料流。 若您不熟悉轉換作業,請參閱簡介文章使用對應資料流轉換資料。
存在項目轉換是一種資料列篩選轉換,可檢查另一個來源或資料流中是否有您的資料。 輸出資料流包含左側資料流的所有資料列 (無論是否存在右側資料流中)。 存在項目轉換與 SQL WHERE EXISTS 和 SQL WHERE NOT EXISTS 類似。
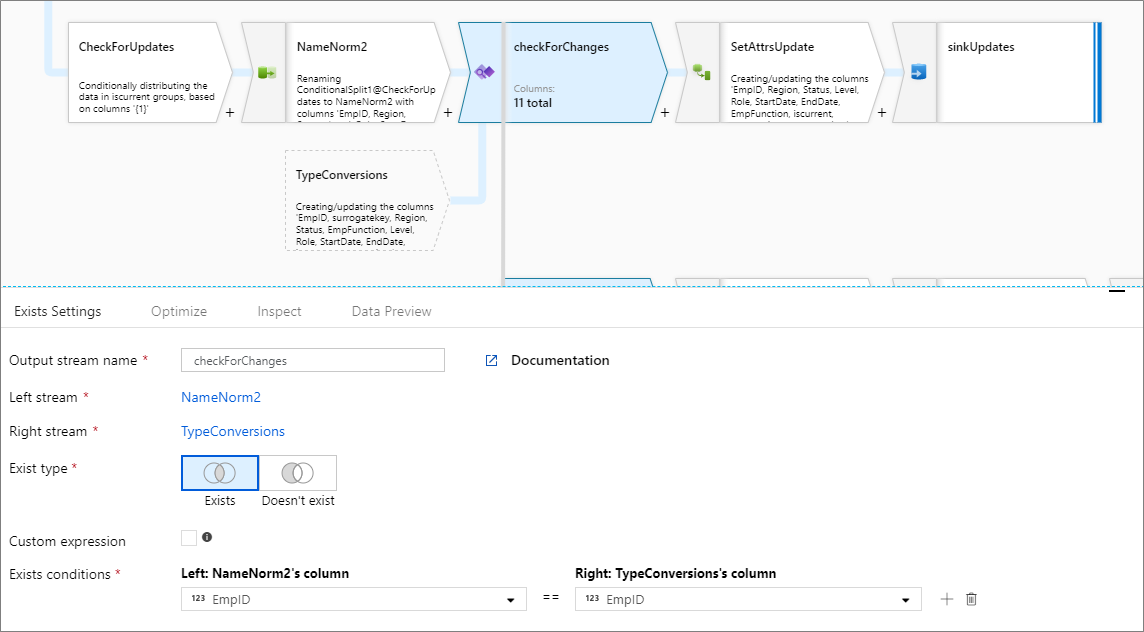
若要比較各資料流的多個資料行,請按一下現有資料列旁的加號圖示,以新增存在條件。 每項額外條件皆會聯結「and」陳述式。 兩個資料行的比較方式與下列運算式相同:
source1@column1 == source2@column1 && source1@column2 == source2@column2
若要以「and」和「equals to」以外的運算子建立自由格式的運算式,請選取 [自訂運算式] 欄位。 按一下藍色方塊,透過資料流程運算式建立器輸入自訂運算式。
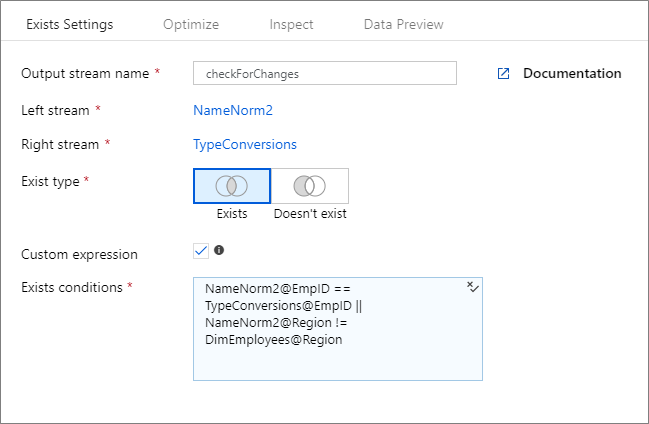
若要透過結構描述漂移使用資料行的「晚期繫結」,在資料流程中建置動態模式,您可使用 byName() 運算式函數來使用存在項目轉換,而無須將資料行名稱進行硬式編碼 (意即早期繫結)。 範例: toString(byName('ProductNumber','source1')) == toString(byName('ProductNumber','source2'))
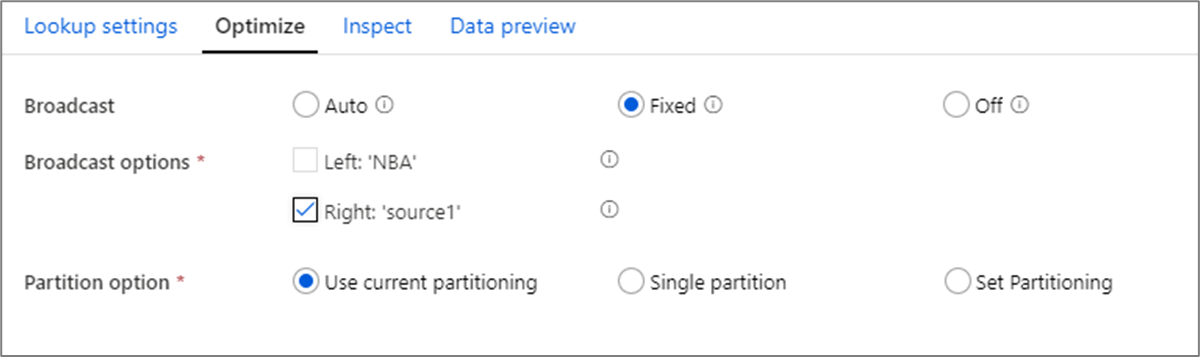
在聯結、查閱和存在轉換中,如果其中一個或兩個資料流納入背景工作角色節點記憶體中,您可以藉由啟用 [廣播] 來最佳化效能。 根據預設,Spark 引擎會自動決定是否要廣播一邊。 若要手動選擇廣播哪一邊,請選取 [固定]。
除非您的聯結遇到逾時錯誤,否則不建議透過 [關閉] 選項停用廣播。
<leftStream>, <rightStream>
exists(
<conditionalExpression>,
negate: { true | false },
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <existsTransformationName>
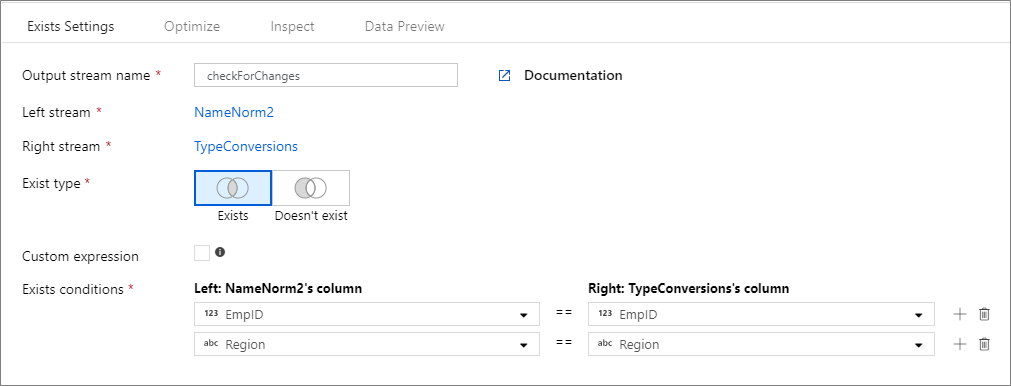
下列範例是名稱為 checkForChanges 的存在項目轉換,並採用左側資料流 NameNorm2 和右側資料流 TypeConversions。 存在條件為運算式 NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,若同時符合各資料流的 EMPID 和 Region 資料行,則傳回 True。 檢查存在項目時,negate 為 false。 我們不會在 [最佳化] 索引標籤中啟用廣播,因此 broadcast 的值為 'none'。
在使用者介面中,此轉換如下圖所示:
此轉換的資料流指令碼位於下列程式碼片段中:
NameNorm2, TypeConversions
exists(
NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,
negate:false,
broadcast: 'auto'
) ~> checkForChanges
訓練
模組
使用 Azure Data Factory 大規模進行無程式碼的轉換 - Training
使用 Azure Data Factory 或 Azure Synapse 管線大規模執行無程式碼的轉換
文件
對應資料流程中的判斷提示資料轉換 - Azure Data Factory
設定對應資料流程的判斷提示
對應資料流程中的強制型轉轉換 - Azure Data Factory & Azure Synapse
了解如何使用對應資料流程的強制型轉轉換,輕鬆在 Azure Data Factory 或 Synapse Analytics 管線中變更資料行的資料類型。
對應資料流中的聯集轉換 - Azure Data Factory & Azure Synapse
了解 Azure Data Factory 和 Synapse Analytics 中的對應資料流「新增分支轉換」