訓練
認證
Microsoft Certified: Power BI Data Analyst Associate - Certifications
示範符合使用 Microsoft Power BI 進行資料建模、視覺化和分析的業務和技術要求的方法和最佳做法。
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用 (部分機器翻譯)!
Azure Data Factory 和 Azure Synapse Pipelines 中均可使用資料流。 本文適用於對應資料流。 如果您不熟悉轉換作業,請參閱簡介文章使用對應資料流轉換資料。
使用樞紐轉換,從單一資料行的唯一資料列值建立多個資料行。 樞紐是匯總轉換,您可以在其中選取群組依據資料行,並使用彙總函式產生樞紐分析表。
樞紐轉換需要三個不同的輸入:群組依據資料行、樞紐索引鍵,以及如何產生已樞紐處理的資料行
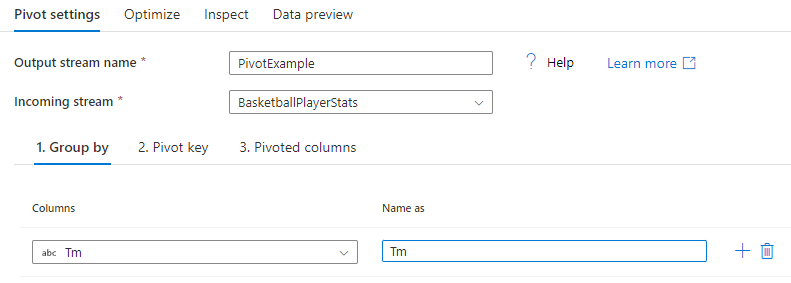
選取要將已樞紐處理的資料行匯總的資料行。 輸出資料會將具有相同群組依據值的所有資料列分組為一個資料列。 在經過樞紐處理的資料行中完成的匯總將出現在每個群組上。
本節為選擇性。 如果未選取群組依據資料行,則會匯總整個資料流,而且只會輸出一個資料列。
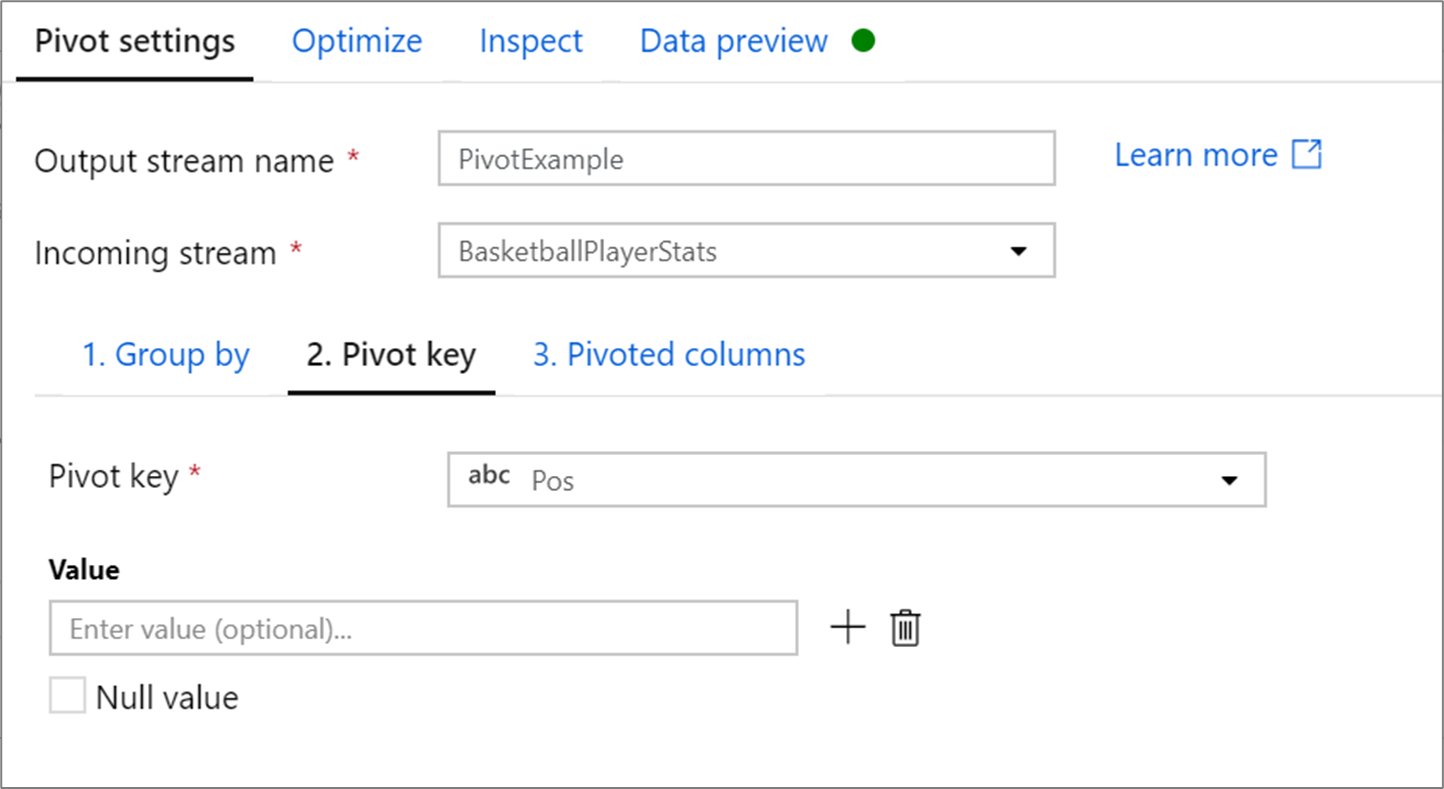
樞紐索引鍵是資料列值樞紐處理為新資料行的資料行。 根據預設,樞紐轉換會針對每個唯一的資料列值建立新的資料行。
在標示為 [值] 的區段中,您可以輸入要樞紐處理的特定資料列值。 只有在此區段中輸入的資料列值才會予以樞紐處理。 啟用 Null 值會針對資料行中的 null 值建立樞紐處理的資料行。
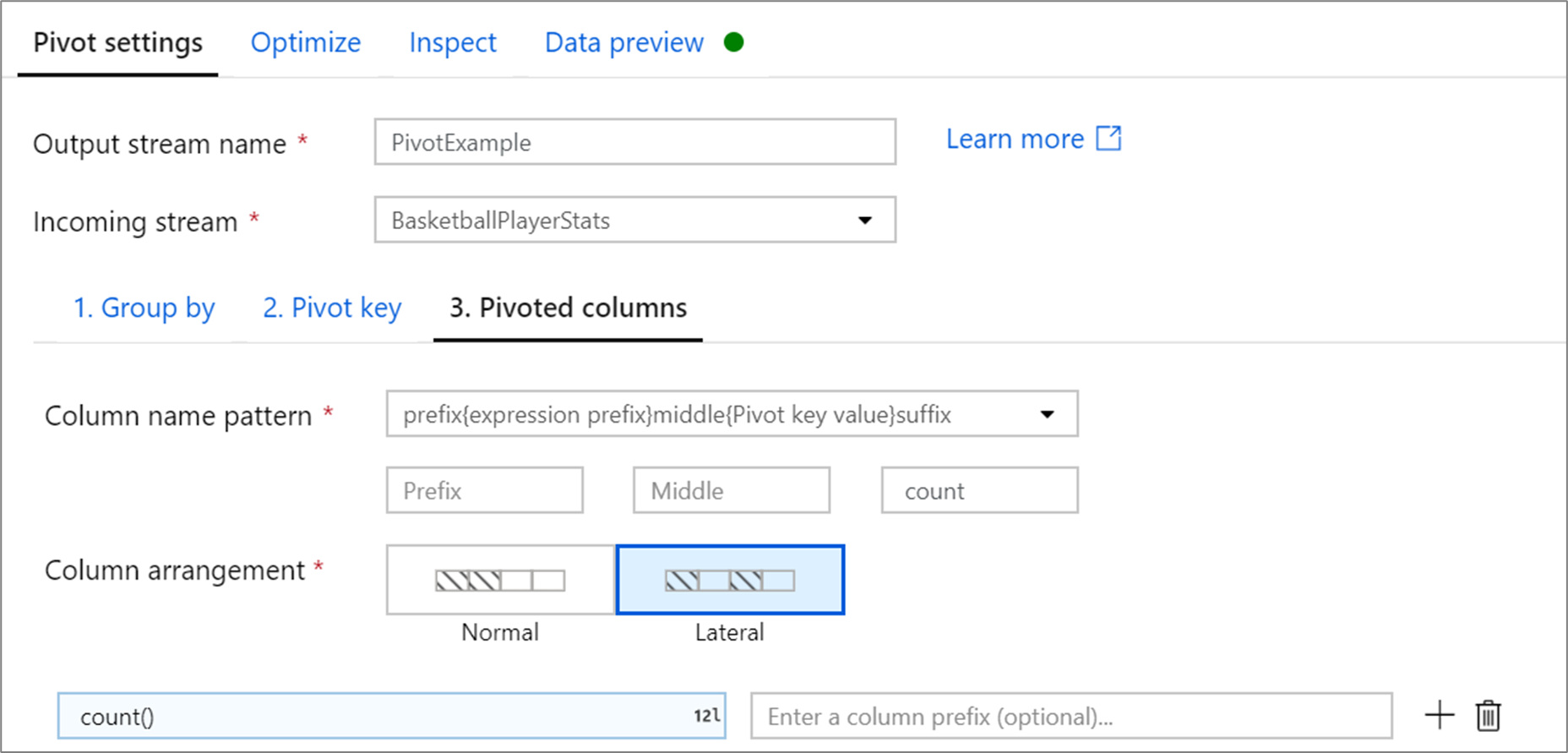
針對每個成為資料行的唯一樞紐索引鍵值,為每個群組產生匯總的資料列值。 您可以為每個樞紐索引鍵建立多個資料行。 每個樞紐資料行都必須包含至少一個彙總函式。
資料行名稱模式:選取如何設定每個樞紐分析表資料行名稱的格式。 輸出的資料行名稱將會是樞紐索引鍵值、資料行前置詞和選擇性前置詞、尾碼、中間字元組合。
資料行擴增:如果您針對每個樞紐索引鍵產生一個以上的樞紐分析表,則請選擇您想要如何排序資料行。
資料行前置詞:如果您針對每個樞紐索引鍵產生一個以上的樞紐分析表,則請輸入每個資料行的資料行前置詞。 如果您只有一個已樞紐處理的資料行,這項設定是選擇性的。
下圖說明不同的樞紐元件彼此互動的方式
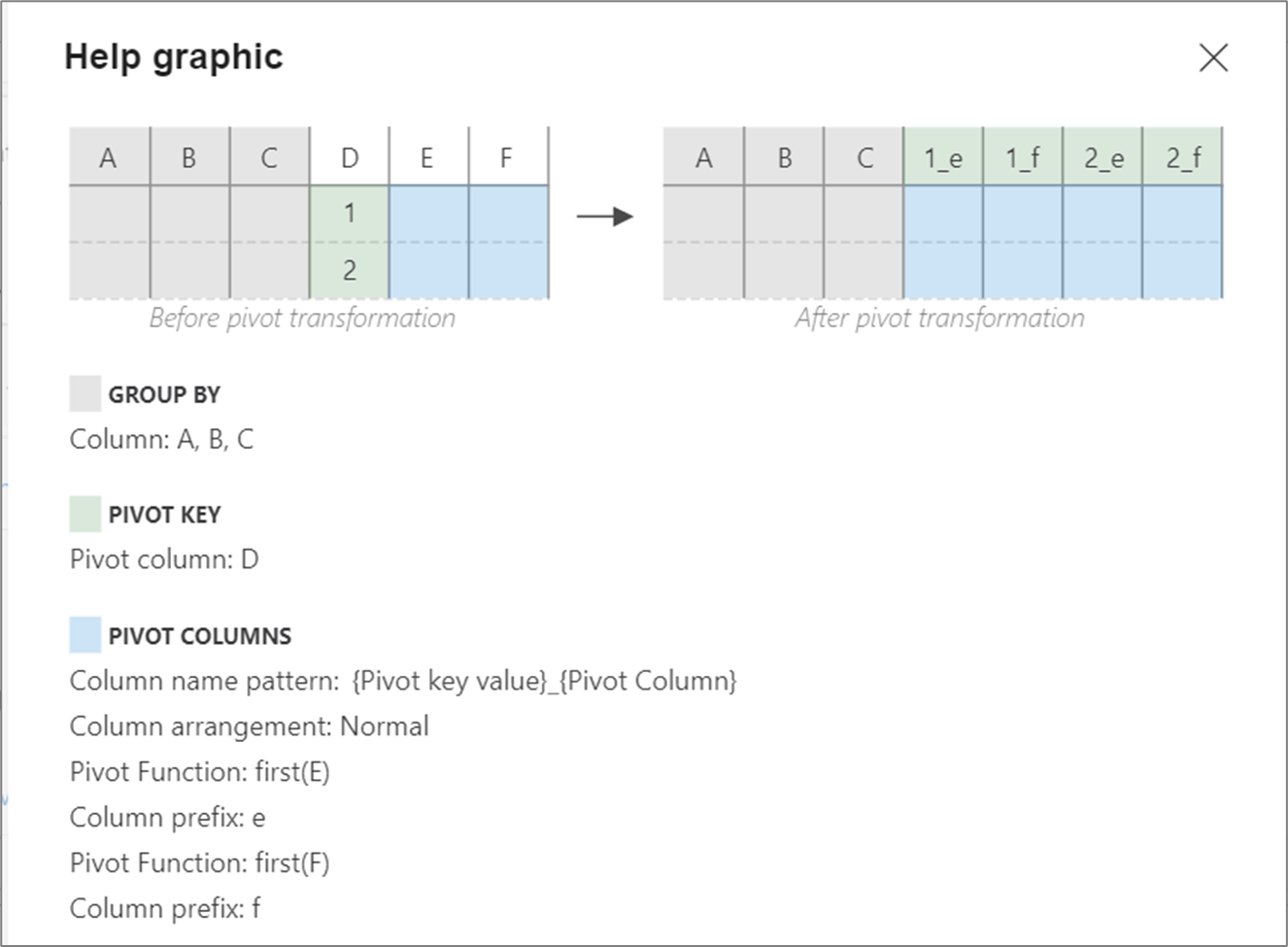
如果在樞紐索引鍵設定中未指定任何值,則會在執行階段動態產生經過樞紐處理的資料行。 已樞紐處理的資料行的數目會等於唯一的樞紐分析表索引鍵值數乘以樞紐資料行的數目。 由於這是可能變更的數位,UX 不會在 [檢查] 索引標籤中顯示資料行中繼資料,而且不會有任何資料行散佈。 若要轉換這些資料行,請使用對應資料流的資料行模式功能。
如果已設定特定的樞紐索引鍵值,則會在中繼資料中顯示已切換的資料行。 資料行名稱將可供您在「檢查」和「接收」對應中使用。
樞紐會根據資料列值動態產生新的資料行名稱。 您可以將這些新的資料行加入中繼資料中,以便往後可在資料流程中參考。 若要這麼做,請使用對應漂移資料預覽中的快速動作。
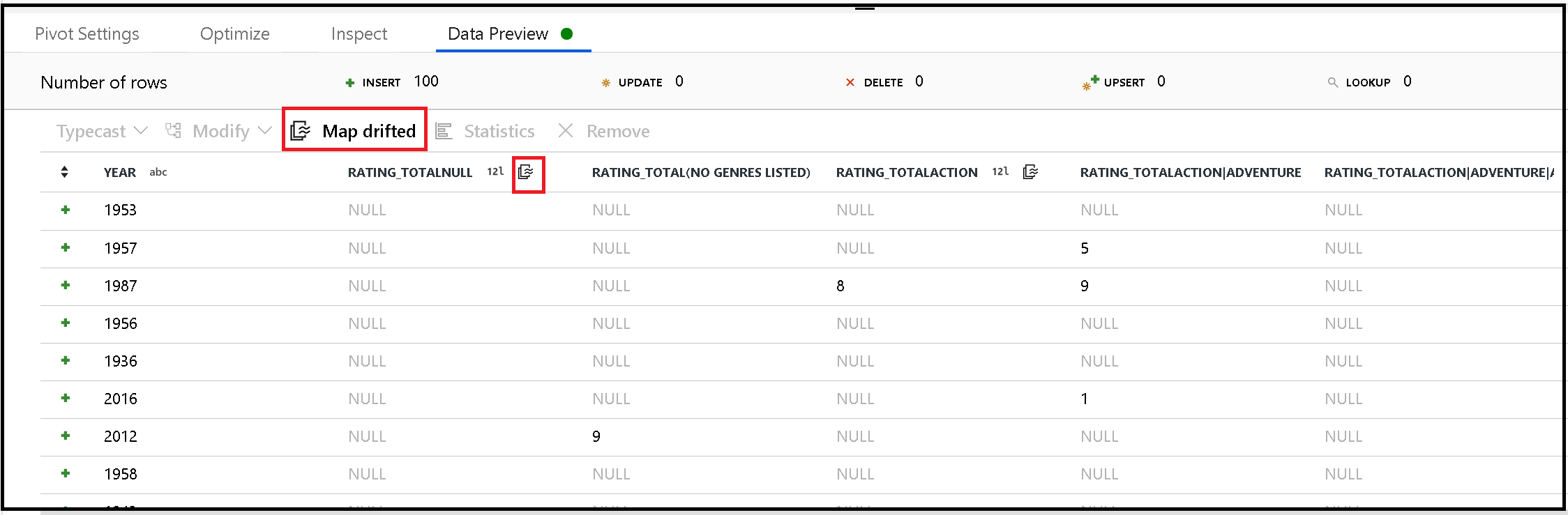
雖然已樞紐處理的資料行為動態,但仍可寫入目的地資料存放區。 在接收設定中啟用 [允許結構描述漂移]。 這可讓您撰寫未包含在中繼資料中的資料行。 您不會在資料行中繼資料中看到新的動態名稱,但是 [結構描述漂移] 選項可讓您放入資料。
樞紐轉換只會投影群組依據和已樞紐處理的資料行。 如果您想要讓輸出資料包含其他輸入資料行,請使用自我聯結模式。
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
[設定] 區段中所顯示的畫面具有下列資料流程指令碼:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
嘗試取消樞紐轉換,將資料行值轉換為資料列值。
訓練
認證
Microsoft Certified: Power BI Data Analyst Associate - Certifications
示範符合使用 Microsoft Power BI 進行資料建模、視覺化和分析的業務和技術要求的方法和最佳做法。
文件
對應資料流中的取消樞紐轉換 - Azure Data Factory & Azure Synapse
了解 Azure Data Factory 和 Synapse Analytics 中對應資料流的取消樞紐轉換。
對應資料流中的衍生資料行轉換 - Azure Data Factory & Azure Synapse
瞭解如何使用對應資料流的衍生資料行轉換,在 Azure Data Factory 和 Azure Synapse Analytics 中大規模地轉換資料。
對應資料流中的聯集轉換 - Azure Data Factory & Azure Synapse
了解 Azure Data Factory 和 Synapse Analytics 中的對應資料流「新增分支轉換」