Training
Module
Configure SQL Server resources for optimal performance - Training
Configure SQL Server resources for optimal performance
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Applies to: ![]() Azure SQL Database
Azure SQL Database
This article describes different types of storage space for databases in Azure SQL Database. Though uncommon, this article includes steps that can be taken when the file space allocated needs to be explicitly managed.
With Azure SQL Database, there are workload patterns where the allocation of underlying data files for databases can become larger than the number of used data pages. This condition can occur when space used increases and data is later deleted. The reason is because file space allocated is not automatically reclaimed when data is deleted.
Monitoring file space usage and shrinking data files might be necessary in the following scenarios:
Note
Shrink operations should not be considered a regular maintenance operation. Data and log files that grow due to regular, recurring business operations do not require shrink operations.
Most storage space metrics displayed in the following APIs only measure the size of used data pages:
However, the following APIs also measure the size of space allocated for databases and elastic pools:
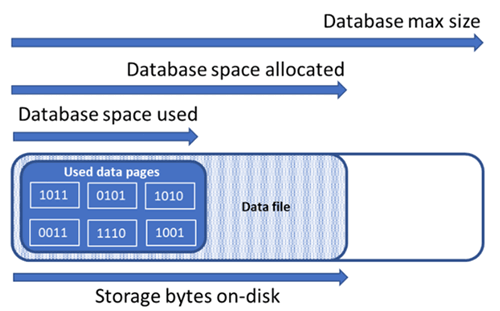
Understanding the following storage space quantities are important for managing the file space of a database.
| Database quantity | Definition | Comments |
|---|---|---|
| Data space used | The amount of space used to store database data. | Generally, space used increases (decreases) on inserts (deletes). In some cases, the space used does not change on inserts or deletes depending on the amount and pattern of data involved in the operation and any fragmentation. For example, deleting one row from every data page does not necessarily decrease the space used. |
| Data space allocated | The amount of formatted file space made available for storing database data. | The amount of space allocated grows automatically, but never decreases after deletes. This behavior ensures that future inserts are faster since space does not need to be reformatted. |
| Data space allocated but unused | The difference between the amount of data space allocated and data space used. | This quantity represents the maximum amount of free space that can be reclaimed by shrinking database data files. |
| Data max size | The maximum amount of space that can be used for storing database data. | The amount of data space allocated cannot grow beyond the data max size. |
The following diagram illustrates the relationship between the different types of storage space for a database.
Use the following query on sys.database_files to return the amount of database file space allocated and the amount of unused space allocated. Units of the query result are in MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Understanding the following storage space quantities are important for managing the file space of an elastic pool.
| Elastic pool quantity | Definition | Comments |
|---|---|---|
| Data space used | The summation of data space used by all databases in the elastic pool. | |
| Data space allocated | The summation of data space allocated by all databases in the elastic pool. | |
| Data space allocated but unused | The difference between the amount of data space allocated and data space used by all databases in the elastic pool. | This quantity represents the maximum amount of space allocated for the elastic pool that can be reclaimed by shrinking database data files. |
| Data max size | The maximum amount of data space that can be used by the elastic pool for all of its databases. | The space allocated for the elastic pool should not exceed the elastic pool max size. If this condition occurs, then space allocated that is unused can be reclaimed by shrinking database data files. |
Note
The error message "The elastic pool has reached its storage limit" indicates that the database objects have been allocated enough space to meet the elastic pool storage limit, but there might be unused space in the data space allocation. Consider increasing the elastic pool's storage limit, or as a short-term solution, freeing up data space using the samples in Reclaim unused allocated space. You should also be aware of the potential negative performance impact of shrinking database files. See Index maintenance after shrink.
The following queries can be used to determine storage space quantities for an elastic pool.
Modify the following query to return the amount of elastic pool data space used. Units of the query result are in MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Modify the following examples to return a table listing the space allocated and unused allocated space for each database in an elastic pool. The table orders databases from those databases with the greatest amount of unused allocated space to the least amount of unused allocated space. Units of the query result are in MB.
The query results for determining the space allocated for each database in the pool can be added together to determine the total space allocated for the elastic pool. The elastic pool space allocated should not exceed the elastic pool max size.
Important
The PowerShell Azure Resource Manager (AzureRM) module was deprecated on February 29, 2024. All future development should use the Az.Sql module. Users are advised to migrate from AzureRM to the Az PowerShell module to ensure continued support and updates. The AzureRM module is no longer maintained or supported. The arguments for the commands in the Az PowerShell module and in the AzureRM modules are substantially identical. For more about their compatibility, see Introducing the new Az PowerShell module.
The PowerShell script requires SQL Server PowerShell module. For more information, see SQL Server PowerShell module.
The following PowerShell script completes these steps:
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of unused allocated space
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
The following screenshot is an example of the output of the script:

Modify the following T-SQL query to return the last recorded elastic pool data max size. Units of the query result are in MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Important
Shrink commands impact database performance while running, and if possible should be run during periods of low usage.
Because of a potential impact to database performance, Azure SQL Database does not automatically shrink data files. However, customers might shrink data files via self-service at a time of their choosing. This should not be a regularly scheduled operation, but rather, a one-time event in response to a major reduction in data file used space consumption.
Tip
Don't waste time shrinking data files if the regular application workload will cause the files to grow to the same allocated size again. File growth events can negatively impact application performance.
In Azure SQL Database, to shrink files you can use either DBCC SHRINKDATABASE or DBCC SHRINKFILE commands:
DBCC SHRINKDATABASE shrinks all data and log files in a database using a single command. The command shrinks one data file at a time, which can take a long time for larger databases. It also shrinks the log file, which is usually unnecessary because Azure SQL Database shrinks log files automatically as needed.DBCC SHRINKFILE command supports more advanced scenarios:
DBCC SHRINKFILE command can run in parallel with other DBCC SHRINKFILE commands to shrink multiple files at the same time and reduce the total time of shrink, at the expense of higher resource usage and a higher chance of blocking user queries, if they are executing during shrink.
TRUNCATEONLY argument. This does not require data movement within the file.The following examples must be executed while connected to the target user database, not the master database.
To use DBCC SHRINKDATABASE to shrink all data and log files in a given database:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
In Azure SQL Database, a database might have one or more data files, created automatically as data grows. To determine file layout of your database, including the used and allocated size of each file, query the sys.database_files catalog view using the following sample script:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
You can execute a shrink against one file only via the DBCC SHRINKFILE command, for example:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Be aware of the potential negative performance impact of shrinking database files. For more information, see Index maintenance after shrink.
Unlike data files, Azure SQL Database automatically shrinks transaction log file to avoid excessive space usage that can lead to out-of-space errors. It is usually not necessary for customers to shrink the transaction log file.
In Premium and Business Critical service tiers, if the transaction log becomes large, it might significantly contribute to local storage consumption toward the maximum local storage limit. If local storage consumption is close to the limit, customers might choose to shrink transaction log using the DBCC SHRINKFILE command as shown in the following example. This releases local storage as soon as the command completes, without waiting for the periodic automatic shrink operation.
The following example should be executed while connected to the target user database, not the master database.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
As an alternative to shrinking data files manually, auto-shrink can be enabled for a database. However, auto shrink can be less effective in reclaiming file space than DBCC SHRINKDATABASE and DBCC SHRINKFILE.
By default, auto-shrink is disabled, which is recommended for most databases. If it becomes necessary to enable auto-shrink, it is recommended to disable it once space management goals are achieved, instead of keeping it enabled permanently. For more information, see Considerations for AUTO_SHRINK.
For example, auto-shrink can be helpful in the specific scenario where an elastic pool contains many databases that experience significant growth and reduction in data file space used, causing the pool to approach its maximum size limit. This is not a common scenario.
To enable auto-shrink, execute the following command while connected to your database (not the master database).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
For more information about this command, see DATABASE SET options.
After a shrink operation is completed against data files, indexes might become fragmented. This reduces their performance optimization effectiveness for certain workloads, such as queries using large scans. If performance degradation occurs after the shrink operation is complete, consider index maintenance to rebuild indexes. Keep in mind that index rebuilds require free space in the database, and hence might cause the allocated space to increase, counteracting the effect of shrink.
For more information about index maintenance, see Optimize index maintenance to improve query performance and reduce resource consumption.
When database allocated space is in hundreds of gigabytes or higher, shrink might require a significant time to complete, often measured in hours, or days for multi-terabyte databases. There are process optimizations and best practices you can use to make this process more efficient and less impactful to application workloads.
Before starting shrink, capture the current used and allocated space in each database file by executing the following space usage query:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Once shrink has completed, you can execute this query again and compare the result to the initial baseline.
It is recommended to first execute shrink for each data file with the TRUNCATEONLY parameter. This way, if there is any allocated but unused space at the end of the file, it is removed quickly and without any data movement. The following sample command truncates data file with file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Once this command is executed for every data file, you can rerun the space usage query to see the reduction in allocated space, if any. You can also view allocated space for the database in Azure portal.
If truncating data files did not result in a sufficient reduction in allocated space, you will need to shrink data files. However, as an optional but recommended step, you should first determine average page density for indexes in the database. For the same amount of data, shrink operations complete faster if page density is high, because it has to move fewer pages. If page density is low for some indexes, consider performing maintenance on these indexes to increase page density before shrinking data files. This will also let shrink achieve a deeper reduction in allocated storage space.
To determine page density for all indexes in the database, use the following query. Page density is reported in the avg_page_space_used_in_percent column.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
If there are indexes with high page count that have page density lower than 60-70%, consider rebuilding or reorganizing these indexes before shrinking data files.
Note
For larger databases, the query to determine page density might take a long time (hours) to complete. Additionally, rebuilding or reorganizing large indexes also requires substantial time and resource usage. There is a tradeoff between spending extra time on increasing page density on one hand, and reducing shrink duration and achieving higher space savings on another.
If there are multiple indexes with low page density, you might be able to rebuild them in parallel on multiple database sessions to speed up the process. However, make sure that you are not approaching database resource limits by doing so, and leave sufficient resource headroom for application workloads that might be running. Monitor resource consumption (CPU, Data IO, Log IO) in Azure portal or using the sys.dm_db_resource_stats view. Start additional parallel rebuilds only if resource utilization on each of these dimensions remains substantially lower than 100%. If CPU, Data IO, or Log IO utilization is at 100%, you can scale up the database to have more CPU cores and increase IO throughput. This might enable additional parallel rebuilds to complete the process faster.
Following is a sample command to rebuild an index and increase its page density, using the ALTER INDEX statement:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
This command initiates an online and resumable index rebuild. This lets concurrent workloads continue using the table while the rebuild is in progress, and lets you resume the rebuild if it gets interrupted for any reason. However, this type of rebuild is slower than an offline rebuild, which blocks access to the table. If no other workloads need to access the table during rebuild, set the ONLINE and RESUMABLE options to OFF and remove the WAIT_AT_LOW_PRIORITY clause.
To learn more about index maintenance, see Optimize index maintenance to improve query performance and reduce resource consumption.
As noted earlier, shrink with data movement is a long-running process. If the database has multiple data files, you can speed up the process by shrinking multiple data files in parallel. You do this by opening multiple database sessions, and using DBCC SHRINKFILE on each session with a different file_id value. Similar to rebuilding indexes earlier, make sure you have sufficient resource headroom (CPU, Data IO, Log IO) before starting each new parallel shrink command.
The following sample command shrinks data file with file_id 4, attempting to reduce its allocated size to 52,000 MB by moving pages within the file:
DBCC SHRINKFILE (4, 52000);
If you want to reduce allocated space for the file to the minimum possible, execute the statement without specifying the target size:
DBCC SHRINKFILE (4);
If a workload is running concurrently with shrink, it might start using the storage space freed by shrink before shrink completes and truncates the file. In this case, shrink will not be able to reduce allocated space to the specified target.
You can mitigate this by shrinking each file in smaller steps. This means that in the DBCC SHRINKFILE command, you set the target that is slightly smaller than the current allocated space for the file, as seen in the results of baseline space usage query. For example, if allocated space for file with file_id 4 is 200,000 MB, and you want to shrink it to 100,000 MB, you can first set the target to 170,000 MB:
DBCC SHRINKFILE (4, 170000);
Once this command completes, it has truncated the file and reduced its allocated size to 170,000 MB. You can then repeat this command, setting target first to 140,000 MB, then to 110,000 MB, and so forth, until the file is shrunk to the desired size. If the command completes but the file is not truncated, use smaller steps, for example 15,000 MB rather than 30,000 MB.
To monitor shrink progress for all concurrently running shrink sessions, you can use the following query:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Note
Shrink progress can be nonlinear, and the value in the percent_complete column might remain unchanged for long periods of time, even though shrink is still in progress.
Once shrink completes for all data files, rerun the space usage query (or check in Azure portal) to determine the resulting reduction in allocated storage size. If there is still a large difference between used space and allocated space, rebuild indexes. This can temporarily increase allocated space further, however shrinking data files again after rebuilding indexes should result in a deeper reduction in allocated space.
Occasionally, a shrink command can fail with various errors such as time-outs and deadlocks. In general, these errors are transient, and do not occur again if the same command is repeated. If shrink fails with an error, the progress it has made so far in moving data pages is retained, and the same shrink command can be executed again to continue shrinking the file.
The following sample script shows how you can run shrink in a retry loop to automatically retry up to a configurable number of times when a time-out error or a deadlock error occurs. This retry approach is applicable to many other errors that might occur during shrink.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
In addition to time-outs and deadlocks, shrink can encounter errors due to certain known issues.
The errors returned and mitigation steps are as follows:
This error occurs when there are long running active transactions that have generated row versions in persistent version store (PVS). The pages containing these row versions cannot be moved by shrink, and fails with this error.
To mitigate, you have to wait until these long running transactions have completed. Alternatively, you can identify and terminate these long running transactions, but this can affect your application if it does not handle transaction failures gracefully. One way to find long running transactions is by running the following query in the database where you ran the shrink command:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
You can terminate a transaction by using the KILL command and specifying the associated session_id value from query result:
KILL 4242; -- replace 4242 with the session_id value from query results
Caution
Terminating a transaction can negatively impact workloads.
Once long running transactions are terminated or have completed, an internal background task will clean up no longer needed row versions after some time. You can monitor PVS size to gauge cleanup progress, using the following query. Run the query in the database where you ran the shrink command:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Once PVS size reported in the persistent_version_store_size_gb column is substantially reduced compared to its original size, rerunning shrink should succeed.
This error can occur if there are ongoing index maintenance operations such as ALTER INDEX. Retry the shrink command after these operations are complete.
If this error persists, the associated index might have to be rebuilt. To find the index to rebuild, execute the following query in the same database where you ran the shrink command:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Before executing this query, replace the <file_id> and <page_id> placeholders with the actual values from the error message you received. For example, if the message is Empty page 1:62669 could not be deallocated, then <file_id> is 1 and <page_id> is 62669.
Rebuild the index identified by the query, and retry the shrink command.
This error means that the data file cannot be shrunk further. You can move on to the next data file.
For information about database max sizes, see:
Training
Module
Configure SQL Server resources for optimal performance - Training
Configure SQL Server resources for optimal performance
Documentation
Database file space management - Azure SQL Managed Instance
This page describes how to manage file space with databases in Azure SQL Managed Instance.
Monitoring and performance tuning - Azure SQL Database & Azure SQL Managed Instance
An overview of monitoring and performance tuning capabilities and methodology in Azure SQL Database and Azure SQL Managed Instance.
Monitor performance using DMVs - Azure SQL Managed Instance
Learn how to detect and diagnose common performance problems by using dynamic management views to monitor Microsoft Azure SQL Managed Instance.