Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Python SDK azure-ai-ml v2 (current)
Python SDK azure-ai-ml v2 (current)
This article answers common questions about forecasting in automatic machine learning (AutoML). For general information about forecasting methodology in AutoML, see the Overview of forecasting methods in AutoML article.
How do I start building forecasting models in AutoML?
You can start by reading the Set up AutoML to train a time-series forecasting model article. You can also find hands-on examples in several Jupyter notebooks:
- Bike share example
- Forecasting using deep learning
- Many Models solution
- Forecasting recipes
- Advanced forecasting scenarios
Why is AutoML slow on my data?
We're always working to make AutoML faster and more scalable. To work as a general forecasting platform, AutoML does extensive data validations and complex feature engineering, and it searches over a large model space. This complexity can require a lot of time, depending on the data and the configuration.
One common source of slow runtime is training AutoML with default settings on data that contains numerous time series. The cost of many forecasting methods scales with the number of series. For example, methods like Exponential Smoothing and Prophet train a model for each time series in the training data.
The Many Models feature of AutoML scales to these scenarios by distributing training jobs across a compute cluster. It has been successfully applied to data with millions of time series. For more information, see the many models article section. You can also read about the success of Many Models on a high-profile competition dataset.
How can I make AutoML faster?
See the Why is AutoML slow on my data? answer to understand why AutoML might be slow in your case.
Consider the following configuration changes that might speed up your job:
- Block time series models like ARIMA and Prophet.
- Turn off look-back features like lags and rolling windows.
- Reduce:
- The number of trials/iterations.
- Trial/iteration timeout.
- Experiment timeout.
- The number of cross-validation folds.
- Ensure that early termination is enabled.
What modeling configuration should I use?
AutoML forecasting supports four basic configurations:
| Configuration | Scenario | Pros | Cons |
|---|---|---|---|
| Default AutoML | Recommended if the dataset has a small number of time series that have roughly similar historical behavior. | - Simple to configure from code/SDK or Azure Machine Learning studio. - AutoML can learn across different time series because the regression models pool all series together in training. For more information, see Model grouping. |
- Regression models might be less accurate if the time series in the training data have divergent behavior. - Time series models might take a long time to train if the training data has a large number of series. For more information, see the Why is AutoML slow on my data? answer. |
| AutoML with deep learning | Recommended for datasets with more than 1,000 observations and, potentially, numerous time series that exhibit complex patterns. When it's enabled, AutoML will sweep over temporal convolutional neural network (TCN) models during training. For more information, see Enable deep learning. | - Simple to configure from code/SDK or Azure Machine Learning studio. - Cross-learning opportunities, because the TCN pools data over all series. - Potentially higher accuracy because of the large capacity of deep neural network (DNN) models. For more information, see Forecasting models in AutoML. |
- Training can take much longer because of the complexity of DNN models. - Series with small amounts of history are unlikely to benefit from these models. |
| Many Models | Recommended if you need to train and manage a large number of forecasting models in a scalable way. For more information, see the many models article section. | - Scalable. - Potentially higher accuracy when time series have divergent behavior from one another. |
- No learning across time series. - You can't configure or run Many Models jobs from Azure Machine Learning studio. Only the code/SDK experience is currently available. |
| Hierarchical time series (HTS) | Recommended if the series in your data have a nested, hierarchical structure, and you need to train or make forecasts at aggregated levels of the hierarchy. For more information, see the hierarchical time series forecasting article section. | - Training at aggregated levels can reduce noise in the leaf-node time series and potentially lead to higher-accuracy models. - You can retrieve forecasts for any level of the hierarchy by aggregating or disaggregating forecasts from the training level. |
- You need to provide the aggregation level for training. AutoML doesn't currently have an algorithm to find an optimal level. |
Note
We recommend using compute nodes with GPUs when deep learning is enabled to best take advantage of high DNN capacity. Training time can be much faster in comparison to nodes with only CPUs. For more information, see the GPU-optimized virtual machine sizes article.
Note
HTS is designed for tasks where training or prediction is required at aggregated levels in the hierarchy. For hierarchical data that requires only leaf-node training and prediction, use many models instead.
How can I prevent overfitting and data leakage?
AutoML uses machine learning best practices, such as cross-validated model selection, that mitigate many overfitting issues. However, there are other potential sources of overfitting:
The input data contains feature columns that are derived from the target with a simple formula. For example, a feature that's an exact multiple of the target can result in a nearly perfect training score. The model, however, will likely not generalize to out-of-sample data. We advise you to explore the data prior to model training and to drop columns that "leak" the target information.
The training data uses features that are not known into the future, up to the forecast horizon. AutoML's regression models currently assume that all features are known to the forecast horizon. We advise you to explore your data prior to training and remove any feature columns that are known only historically.
There are significant structural differences (regime changes) between the training, validation, or test portions of the data. For example, consider the effect of the COVID-19 pandemic on demand for almost any good during 2020 and 2021. This is a classic example of a regime change. Overfitting due to regime change is the most challenging problem to address because it's highly scenario dependent and can require deep knowledge to identify.
As a first line of defense, try to reserve 10 to 20 percent of the total history for validation data or cross-validation data. It isn't always possible to reserve this amount of validation data if the training history is short, but it's a best practice. For more information, see Training and validation data.
What does it mean if my training job achieves perfect validation scores?
It's possible to see perfect scores when you're viewing validation metrics from a training job. A perfect score means that the forecast and the actuals on the validation set are the same or nearly the same. For example, you have a root mean squared error equal to 0.0 or an R2 score of 1.0.
A perfect validation score usually indicates that the model is severely overfit, likely because of data leakage. The best course of action is to inspect the data for leaks and drop the columns that are causing the leak.
What if my time series data doesn't have regularly spaced observations?
AutoML's forecasting models all require that training data has regularly spaced observations with respect to the calendar. This requirement includes cases like monthly or yearly observations where the number of days between observations can vary. Time-dependent data might not meet this requirement in two cases:
The data has a well-defined frequency, but missing observations are creating gaps in the series. In this case, AutoML will try to detect the frequency, fill in new observations for the gaps, and impute missing target and feature values. Optionally, the user can configure the imputation methods via SDK settings or through the Web UI. For more information, see Custom featurization.
The data doesn't have a well-defined frequency. That is, the duration between observations doesn't have a discernible pattern. Transactional data, like that from a point-of-sales system, is one example. In this case, you can set AutoML to aggregate your data to a chosen frequency. You can choose a regular frequency that best suits the data and the modeling objectives. For more information, see Data aggregation.
How do I choose the primary metric?
The primary metric is important because its value on validation data determines the best model during sweeping and selection. Normalized root mean squared error (NRMSE) and normalized mean absolute error (NMAE) are usually the best choices for the primary metric in forecasting tasks.
To choose between them, note that NRMSE penalizes outliers in the training data more than NMAE because it uses the square of the error. NMAE might be a better choice if you want the model to be less sensitive to outliers. For more information, see Regression and forecasting metrics.
Note
We don't recommend using the R2 score, or R2, as a primary metric for forecasting.
Note
AutoML doesn't support custom or user-provided functions for the primary metric. You must choose one of the predefined primary metrics that AutoML supports.
How can I improve the accuracy of my model?
- Ensure that you're configuring AutoML the best way for your data. For more information, see the What modeling configuration should I use? answer.
- Check out the forecasting recipes notebook for step-by-step guides on how to build and improve forecast models.
- Evaluate the model by using back tests over several forecasting cycles. This procedure gives a more robust estimate of forecasting error and gives you a baseline to measure improvements against. For an example, see the back-testing notebook.
- If the data is noisy, consider aggregating it to a coarser frequency to increase the signal-to-noise ratio. For more information, see Frequency and target data aggregation.
- Add new features that can help predict the target. Subject matter expertise can help greatly when you're selecting training data.
- Compare validation and test metric values, and determine if the selected model is underfitting or overfitting the data. This knowledge can guide you to a better training configuration. For example, you might determine that you need to use more cross-validation folds in response to overfitting.
Will AutoML always select the same best model from the same training data and configuration?
AutoML's model search process is not deterministic, so it doesn't always select the same model from the same data and configuration.
How do I fix an out-of-memory error?
There are two types of memory errors:
- RAM out-of-memory
- Disk out-of-memory
First, ensure that you're configuring AutoML in the best way for your data. For more information, see the What modeling configuration should I use? answer.
For default AutoML settings, you can fix RAM out-of-memory errors by using compute nodes with more RAM. A general rule is that the amount of free RAM should be at least 10 times larger than the raw data size to run AutoML with default settings.
You can resolve disk out-of-memory errors by deleting the compute cluster and creating a new one.
What advanced forecasting scenarios does AutoML support?
AutoML supports the following advanced prediction scenarios:
- Quantile forecasts
- Robust model evaluation via rolling forecasts
- Forecasting beyond the forecast horizon
- Forecasting when there's a gap in time between training and forecasting periods
For examples and details, see the notebook for advanced forecasting scenarios.
How do I view metrics from forecasting training jobs?
To find training and validation metric values, see View information about jobs or runs in the studio. You can view metrics for any forecasting model trained in AutoML by going to a model from the AutoML job UI in the studio and selecting the Metrics tab.

How do I debug failures with forecasting training jobs?
If your AutoML forecasting job fails, an error message on the studio UI can help you diagnose and fix the problem. The best source of information about the failure beyond the error message is the driver log for the job. For instructions on finding driver logs, see View jobs/runs information with MLflow.
Note
For a Many Models or HTS job, training is usually on multiple-node compute clusters. Logs for these jobs are present for each node IP address. In this case, you need to search for error logs in each node. The error logs, along with the driver logs, are in the user_logs folder for each node IP.
How do I deploy a model from forecasting training jobs?
You can deploy a model from forecasting training jobs in either of these ways:
- Online endpoint: Check the scoring file used in the deployment, or select the Test tab on the endpoint page in the studio, to understand the structure of input that the deployment expects. See this notebook for an example. For more information about online deployment, see Deploy an AutoML model to an online endpoint.
- Batch endpoint: This deployment method requires you to develop a custom scoring script. Refer to this notebook for an example. For more information about batch deployment, see Use batch endpoints for batch scoring.
For UI deployments, we encourage you to use either of these options:
- Real-time endpoint
- Batch endpoint
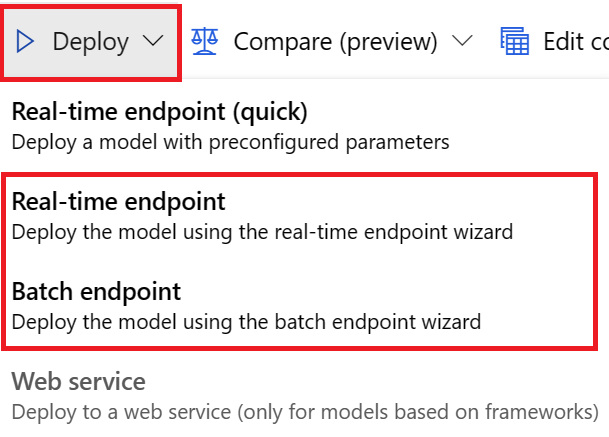
Don't use the first option, Real-time-endpoint (quick).
Note
As of now, we don't support deploying the MLflow model from forecasting training jobs via SDK, CLI, or UI. You'll get errors if you try it.
What is a workspace, environment, experiment, compute instance, or compute target?
If you aren't familiar with Azure Machine Learning concepts, start with the What is Azure Machine Learning? and What is an Azure Machine Learning workspace? articles.
Next steps
- Learn more about how to set up AutoML to train a time-series forecasting model.
- Learn about calendar features for time series forecasting in AutoML.
- Learn about how AutoML uses machine learning to build forecasting models.
- Learn about AutoML forecasting for lagged features.