Pipelines et activités dans Azure Data Factory et Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Important
La prise en charge d’Azure Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
Depuis le 1er décembre 2021, vous ne pouvez plus créer de nouvelles ressources Machine Learning Studio (classique) (plan d’espace de travail et de service web). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les expériences et services web Machine Learning Studio (classique) existants. Pour plus d’informations, consultez l’article suivant :
- Effectuer une migration vers Azure Machine Learning à partir de Machine Learning Studio (classique)
- Qu'est-ce que Microsoft Azure Machine Learning ?
La documentation de Machine Learning Studio (classique) est en cours de retrait et peut ne pas être mise à jour à l’avenir.
Cet article vous aide à comprendre les pipelines et les activités dans Azure Data Factory et Azure Synapse Analytics, et à les utiliser dans l’optique de créer des workflows pilotés par les données de bout en bout pour vos scénarios de déplacement des données et de traitement des données.
Vue d’ensemble
Une instance Data Factory ou un espace de travail Synapse peut avoir un ou plusieurs pipelines. Un pipeline constitue un regroupement logique d’activités qui exécutent ensemble une tâche. Par exemple, un pipeline peut contenir un ensemble d’activités qui ingèrent et nettoient des données de journal, puis lancent un flux de données de mappage pour analyser les données de journal. Le pipeline vous permet de gérer les activités en tant que groupe et non pas individuellement. Vous pouvez déployer et planifier le pipeline, plutôt que chaque activité séparément.
Les activités d’un pipeline définissent les actions à effectuer sur les données. Par exemple, vous pouvez utiliser une activité de copie pour copier des données d’un serveur SQL Server local vers le Stockage Blob Azure. Ensuite, utilisez une activité de flux de données ou une activité de Databricks Notebook pour traiter et transformer les données du stockage Blob en pool Azure Synapse Analytics sur lesquelles les solutions de création de rapports décisionnelles sont créées.
Azure Data Factory et Azure Synapse Analytics ont trois groupes d’activités : les activités de déplacement des données, les activités de transformation des données et les activités de contrôle. Une activité peut inclure zéro ou plusieurs jeux de données d’entrée et produire un ou plusieurs jeux de données de sortie. Le diagramme suivant montre la relation entre le pipeline, l’activité et le jeu de données :

Un jeu de données d’entrée représente l’entrée d’une activité dans le pipeline, tandis qu’un jeu de données de sortie représente la sortie de l’activité. Les jeux de données identifient les données dans différents magasins de données, par exemple des tables, des fichiers, des dossiers et des documents. Après avoir créé un jeu de données, vous pouvez l’utiliser avec des activités d’un pipeline. Un jeu de données peut, par exemple, constituer un jeu de données d’entrée/sortie d’une activité de copie ou d’une activité HDInsightHive. Pour plus d’informations sur les jeux de données, consultez l’article Jeux de données dans Azure Data Factory.
Remarque
La limite souple par défaut est de 80 activités maximum par pipeline, ce qui inclut les activités internes pour les conteneurs.
Activités de déplacement des données
L’activité de copie dans Data Factory permet de copier les données d’un magasin de données source vers un magasin de données récepteur. Data Factory prend en charge les magasins de données répertoriés dans le tableau de cette section. Les données de n’importe quelle source peuvent être écrites dans n’importe quel récepteur.
Pour plus d’informations, consultez l’article Activité de copie - vue d’ensemble.
Cliquez sur une banque de données pour découvrir comment copier des données depuis/vers cette banque.
Notes
Si un connecteur est marqué en préversion, vous pouvez l’essayer et nous faire part de vos commentaires. Si vous souhaitez établir une dépendance sur les connecteurs en préversion dans votre solution, contactez le support Azure.
Activités de transformation des données
Azure Data Factory et Azure Synapse Analytics prennent en charge les activités de transformation suivantes, qui peuvent être ajoutées soit individuellement soit de façon chaînée avec une autre activité.
Pour plus d’informations, consultez l’article Activités de transformation des données.
| Activités de transformation des données | Environnement de calcul |
|---|---|
| Flux de données | Clusters Apache Spark managés par Azure Data Factory |
| Fonction Azure | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Diffusion en continu Hadoop | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Activités ML Studio (classique) : Batch Execution et Update Resource | Azure VM |
| Procédure stockée | Azure SQL, Azure Synapse Analytics ou SQL Server |
| U-SQL | Service Analytique Azure Data Lake |
| Activité personnalisée | Azure Batch |
| Databricks Notebook | Azure Databricks |
| Activité Databricks Jar | Azure Databricks |
| Activité Databricks Python | Azure Databricks |
Activités de flux de contrôle
Les activités de flux de contrôle suivantes sont prises en charge :
| Activité de contrôle | Description |
|---|---|
| Ajouter une variable | Ajoutez une valeur à une variable de tableau existante. |
| Exécuter le pipeline | L’activité Execute Pipeline permet à un pipeline Data Factory ou Synapse d’appeler un autre pipeline. |
| Filter | Appliquer une expression de filtre à un tableau d’entrée |
| For Each | L’activité ForEach définit un flux de contrôle répétitif dans votre pipeline. Elle permet d’effectuer une itération sur une collection, et exécute des activités spécifiées dans une boucle. L’implémentation en boucle de cette activité est semblable à la structure d’exécution en boucle de Foreach dans les langages de programmation. |
| Obtenir les métadonnées | L’activité GetMetadata peut être utilisée pour récupérer les métadonnées de n’importe quelle donnée dans un pipeline Data Factory ou Synapse. |
| Activité IfCondition | L’activité IfCondition peut être utilisée pour créer une branche en fonction de l’évaluation d’une condition par la valeur true ou false. L’activité IfCondition fournit les mêmes fonctionnalités qu’une instruction «if » dans les langages de programmation. La condition évalue un ensemble d'activités si l'expression renvoie true et un autre ensemble d'activités si elle renvoie false. |
| Activité de recherche | L’activité de recherche peut être utilisée pour lire ou rechercher un enregistrement, un nom de table ou une valeur à partir de n’importe quelle source externe. Cette sortie peut être référencée par des activités complémentaires. |
| Définir une variable | Récupérez la valeur d'une variable existante. |
| Activité jusqu’à | Implémente une boucle Exécuter jusqu’à semblable à la structure Do-Until des langages de programmation. Elle exécute un ensemble d’activités dans une boucle jusqu’à ce que la condition associée à l’activité retourne la valeur true. Vous pouvez spécifier une valeur de délai d’attente pour l’activité Until. |
| Activité de validation | Assurez-vous qu’un pipeline continue l’exécution uniquement si un jeu de données de référence existe, répond à un critère spécifié ou si un délai d’expiration a été atteint. |
| Activité d’attente | Lorsque vous utilisez une activité Wait dans un pipeline, celui-ci attend pendant la période spécifiée avant de poursuivre l'exécution des activités suivantes. |
| Activité Web | L’activité Web peut être utilisée pour appeler un point de terminaison REST personnalisé à partir d’un pipeline. Vous pouvez transmettre des jeux de données et des services liés que l’activité peut utiliser et auxquels elle peut accéder. |
| Activité de Webhook | À l'aide de l'activité de Webhook, appelez un point de terminaison et transmettez une URL de rappel. L’exécution du pipeline attend que le rappel soit appelé avant de passer à l’activité suivante. |
Création d’un pipeline avec l’interface utilisateur
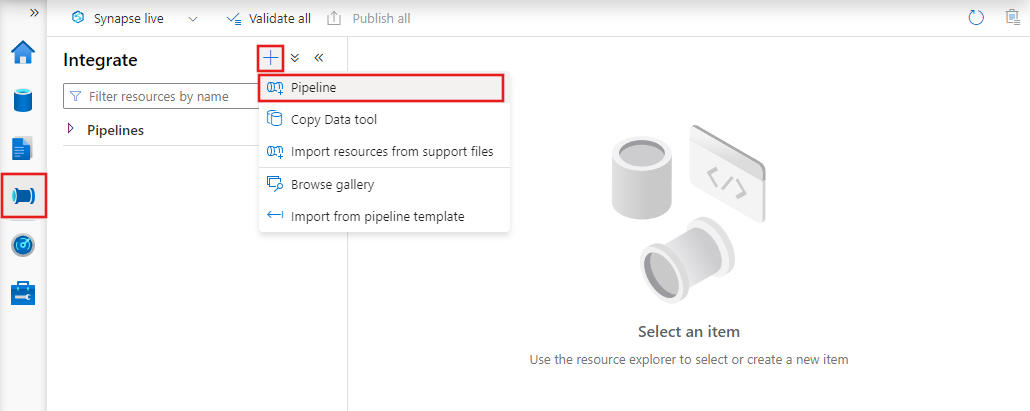
Pour créer un pipeline, accédez à l’onglet Auteur dans Data Factory Studio (représenté par l’icône en forme de crayon), puis cliquez sur le signe plus et choisissez Pipeline dans le menu, et encore Pipeline dans le sous-menu.
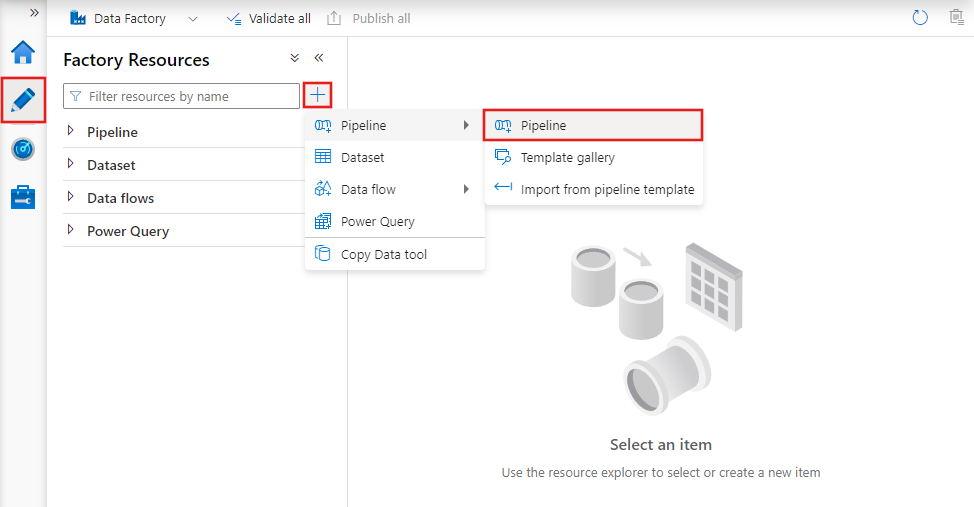
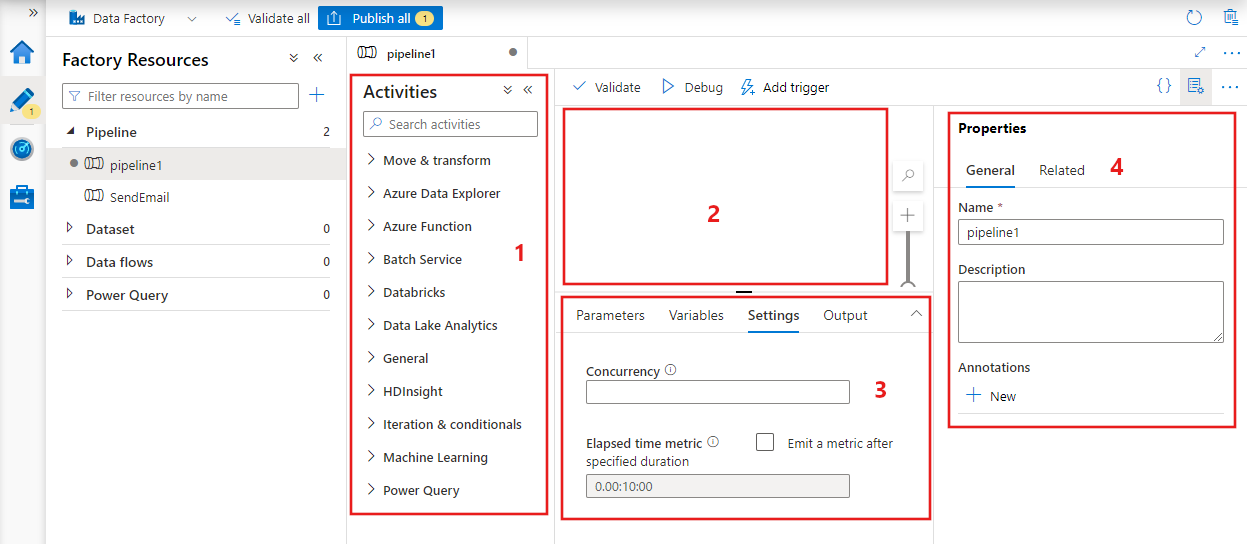
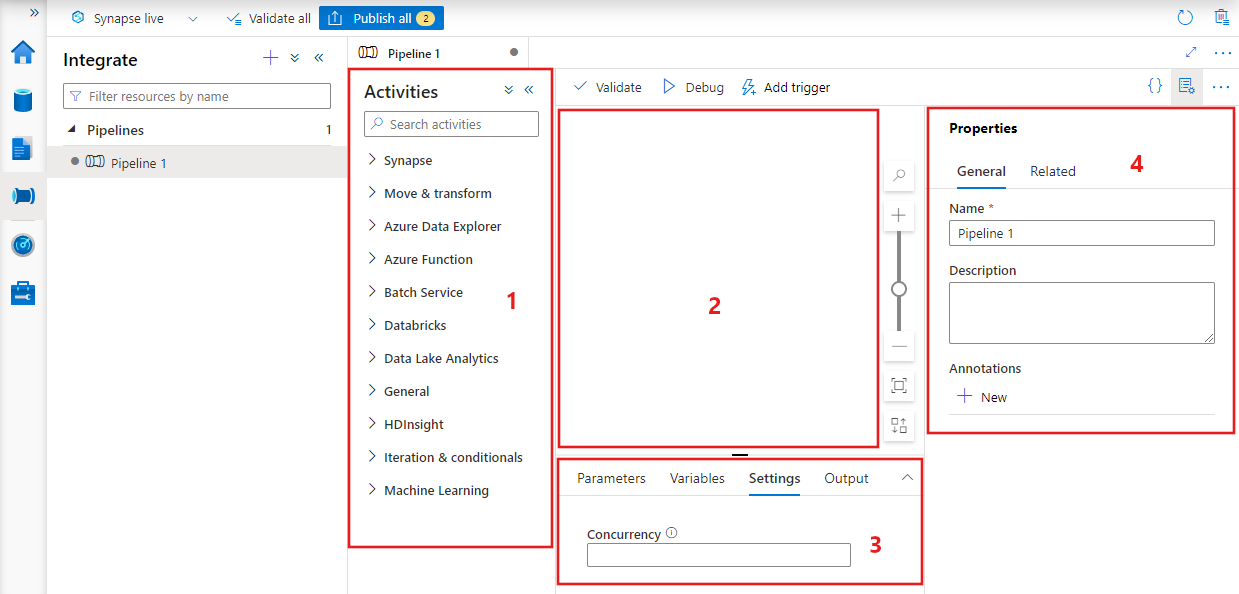
Data Factory affiche l’éditeur de pipeline dans lequel vous pouvez trouver :
- Toutes les activités qui peuvent être utilisées dans le pipeline.
- Le canevas de l’éditeur de pipeline, où les activités apparaîtront lorsqu’elles seront ajoutées au pipeline.
- Le volet de configuration du pipeline, comprenant les paramètres, les variables, les réglages généraux et la sortie.
- Le volet des propriétés du pipeline, dans lequel le nom du pipeline, la description facultative et les annotations peuvent être configurés. Ce volet affiche également tous les éléments associés au pipeline dans la fabrique de données.
Pipeline JSON
Voici comment un pipeline est défini au format JSON :
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Tag | Description | Type | Nécessaire |
|---|---|---|---|
| name | Nom du pipeline. Spécifiez un nom qui représente l’action effectuée par le pipeline.
|
Chaîne | Oui |
| description | Spécifiez le texte décrivant la raison motivant l’utilisation du pipeline. | String | Non |
| activities | La section Activités peut contenir une ou plusieurs activités définies. Consultez la section JSON d’activité pour plus d’informations sur l’élément JSON des activités. | Array | Oui |
| parameters | La section Paramètres peut comporter un ou plusieurs des paramètres définis dans le pipeline, afin de rendre votre pipeline plus flexible en vue de sa réutilisation. | List | Non |
| accès concurrentiel | Nombre maximal d’exécutions simultanées que le pipeline peut avoir. Par défaut, il n’y a pas de valeur maximale. Si la limite de simultanéité est atteinte, les nouvelles exécutions du pipeline sont mises en file d'attente jusqu'à ce que les exécutions précédentes soient terminées | Number | Non |
| annotations | Liste des balises associées au pipeline | Array | Non |
Activité JSON
La section Activités peut contenir une ou plusieurs activités définies. Il existe deux principaux types d’activités : les activités d’exécution et de contrôle.
Activités d’exécution
Les activités d’exécution incluent le déplacement des données et la transformation des données. Elles possèdent la structure de niveau supérieur suivante :
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
Le tableau suivant décrit des propriétés de la définition JSON de l’activité :
| Tag | Description | Obligatoire |
|---|---|---|
| name | Nom de l’activité. Spécifiez un nom qui représente l’action effectuée par l’activité.
|
Oui |
| description | Texte décrivant la raison motivant l’activité ou son utilisation | Oui |
| type | Type de l’activité. Consultez les sections Activités de déplacement des données, Activités de transformation des données et Activités de contrôle pour en savoir plus sur les différents types d’activités. | Oui |
| linkedServiceName | Nom du service lié utilisé par l’activité. Une activité peut nécessiter que vous spécifiiez le service lié à l’environnement de calcul requis. |
Oui pour l’activité HDInsight, l’activité Batch Scoring ML Studio (classique) et l’activité Stored Procedure. Non pour toutes les autres |
| typeProperties | Les propriétés de la section typeProperties dépendent de chaque type d’activité. Pour afficher les propriétés de type d’une activité, cliquez sur les liens vers l’activité dans la section précédente. | Non |
| policy | Stratégies affectant le comportement d’exécution de l’activité. Cette propriété inclut un comportement de délai d'expiration et de nouvelle tentative. Si aucune valeur n'est spécifiée, les valeurs par défaut sont utilisées. Pour plus d’informations, consultez la section Stratégie d’activité. | Non |
| dependsOn | Cette propriété est utilisée pour définir des dépendances des activités, et la manière dont les activités suivantes dépendent des activités précédentes. Pour plus d’informations, consultez l’article Dépendance des activités | Non |
Stratégie d’activité
Les stratégies ont un impact sur le comportement d’exécution d’une activité, en offrant des options de configuration. Les stratégies d’activité sont uniquement disponibles pour les activités d’exécution.
Définition de la JSON Stratégie d’activité
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| Nom JSON | Description | Valeurs autorisées | Obligatoire |
|---|---|---|---|
| délai d'expiration | Spécifie le délai d’expiration d’exécution de l’activité. | Timespan | Nombre Le délai d'expiration par défaut est de 12 heures, minimum 10 minutes. |
| retry | Nombre maximal de nouvelles tentatives | Integer | Non. La valeur par défaut est 0 |
| retryIntervalInSeconds | Délai en secondes entre chaque nouvelle tentative | Integer | Non. La valeur par défaut est de 30 secondes |
| secureOutput | Lorsqu'elle est définie sur true, la sortie de l'activité est considérée comme sécurisée et n'est pas consignée pour la surveillance. | Boolean | Non. La valeur par défaut est false. |
Activité de contrôle
Les activités de contrôle ont la structure de niveau supérieur suivante :
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Tag | Description | Obligatoire |
|---|---|---|
| name | Nom de l’activité. Spécifiez un nom qui représente l’action effectuée par l’activité.
|
Oui |
| description | Texte décrivant la raison motivant l’activité ou son utilisation | Oui |
| type | Type de l’activité. Consultez les sections Activités de déplacement des données, Activités de transformation des données et Activités de contrôle pour en savoir plus sur les différents types d’activités. | Oui |
| typeProperties | Les propriétés de la section typeProperties dépendent de chaque type d’activité. Pour afficher les propriétés de type d’une activité, cliquez sur les liens vers l’activité dans la section précédente. | Non |
| dependsOn | Cette propriété est utilisée pour définir la dépendance des activités, et la manière dont les activités suivantes dépendent des activités précédentes. Pour plus d’informations, consultez l’article Dépendance des activités. | Non |
Dépendance des activités
La dépendance des activités définit la manière dont les activités ultérieures dépendent des activités antérieures, et détermine ainsi s'il faut poursuivre l'exécution de la tâche suivante. Une activité peut dépendre d’une ou de plusieurs activités précédentes avec différentes conditions de dépendance.
Les différentes conditions de dépendance sont : Réussite, Échec, Ignoré, Terminé.
Par exemple, si un pipeline contient Activité A -> Activité B, les différents scénarios qui peuvent se produire sont les suivants :
- L’Activité B a une condition de dépendance envers l’Activité A avec Réussite : L’Activité B s’exécute uniquement si l’Activité A présente l’état final Réussite.
- L’Activité B a une condition de dépendance envers l’Activité A avec Échec : L’Activité B s’exécute uniquement si l’Activité A présente l’état final Échec.
- L’Activité B a une condition de dépendance envers l’Activité A avec Terminé : L’Activité B s’exécute si l’Activité A présente l’état final Réussite ou Échec.
- L'Activité B a une condition de dépendance envers l'Activité A avec Ignoré : L’Activité B s’exécute si l’Activité A présente l’état final Ignoré. Ignoré se produit dans le scénario Activité X -> Activité Y -> Activité Z, où chaque activité s’exécute uniquement si l’activité précédente réussit. Si l'Activité X échoue, l'Activité Y prend l'état « Ignoré » car elle ne s'exécute jamais. De même, l'Activité Z présente également l'état « Ignoré ».
Exemple : L’Activité 2 dépend de la réussite de l’Activité 1
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Exemple de pipeline de copie
Dans l’exemple de pipeline suivant, il existe une activité de type Copy in the d’activités . Dans cet exemple, l’activité de copie copie des données d’un stockage Blob Azure vers une base de données dans Azure SQL Database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Notez les points suivants :
- Dans la section des activités, il existe une seule activité dont le type a la valeur Copy.
- L’entrée de l’activité est définie sur InputDataset et sa sortie, sur OutputDataset. Consultez l’article Jeux de données pour en savoir plus sur la définition de jeux de données dans JSON.
- Dans la section typeProperties, BlobSource est spécifié en tant que type de source et SqlSink, en tant que type de récepteur. Dans la section Activités de déplacement des données, cliquez sur le magasin de données que vous souhaitez utiliser comme source ou récepteur pour en savoir plus sur le déplacement des données vers/depuis ce magasin de données.
Pour obtenir une description complète de la création de ce pipeline, consultez Démarrage rapide : Créer une fabrique de données.
Exemple de pipeline de transformation
Dans l’exemple de pipeline suivant, il existe une activité de type HDInsightHive in the d’activités . Dans cet exemple, l’activité Hive HDInsight transforme les données d’un stockage blob Azure en exécutant un fichier de script Hive sur un cluster Hadoop Azure HDInsight.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Notez les points suivants :
- Dans la section des activités, il existe une seule activité dont le type a la valeur HDInsightHive.
- Le fichier de script Hive, partitionweblogs.hql, est stocké sur le compte de stockage Azure (spécifié par le service scriptLinkedService, appelé AzureStorageLinkedService) et dans le dossier de scripts du conteneur
adfgetstarted. - La section
definesest utilisée pour spécifier les paramètres d’exécution transmis au script Hive comme valeurs de configuration Hive (p. ex. ${hiveconf:inputtable},${hiveconf:partitionedtable}).
La section typeProperties est différente pour chaque activité de transformation. Pour en savoir plus sur les propriétés de type prises en charge pour une activité de transformation, cliquez sur l’activité de transformation dans la table Activités de transformation des données.
Pour obtenir une description complète de la création de ce pipeline, consultez l’article Didacticiel : transformation des données à l’aide de Spark.
Plusieurs activités à l’intérieur d’un pipeline
Les deux exemples de pipelines précédents ne contiennent qu’une seule activité. Un pipeline peut toutefois contenir plusieurs activités. Si un pipeline contient plusieurs activités et que les activités suivantes ne sont pas dépendantes d’activités précédentes, les activités peuvent s’exécuter en parallèle.
Vous pouvez enchaîner deux activités à l’aide de la dépendance des activités, qui définit la manière dont les activités suivantes dépendent des activités précédentes, et détermine ainsi s’il faut poursuivre l’exécution de la tâche suivante. Une activité peut dépendre d’une ou de plusieurs activités précédentes avec différentes conditions de dépendance.
Planification des pipelines
Les pipelines sont planifiés par des déclencheurs. Il existe différents types de déclencheurs (le déclencheur Scheduler, qui permet de déclencher les pipelines selon un planning horaire, ainsi que le déclencheur manuel, qui déclenche les pipelines à la demande). Pour plus d’informations sur les déclencheurs, consultez l’article Exécution de pipelines et déclencheurs.
Pour que votre déclencheur lance l’exécution d’un pipeline, vous devez inclure une référence à ce pipeline spécifique dans la définition du déclencheur. Les pipelines et les déclencheurs ont une relation n-m. Plusieurs déclencheurs peuvent lancer un même pipeline, et un même déclencheur peut lancer plusieurs pipelines. Une fois que le déclencheur est défini, vous devez le démarrer pour qu’il commence à déclencher le pipeline. Pour plus d’informations sur les déclencheurs, consultez l’article Exécution de pipelines et déclencheurs.
Par exemple, vous avez un déclencheur de planificateur, « Trigger A », qui doit lancer votre pipeline, « MyCopyPipeline ». Vous définissez le déclencheur, comme indiqué dans l’exemple suivant :
Définition du déclencheur A
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}
Contenu connexe
Consultez les didacticiels suivants pour obtenir des instructions pas à pas de création de pipelines avec des activités :
- Créer un pipeline avec une activité de copie
- Créer un pipeline avec une activité de transformation des données
Comment parvenir à l’intégration continue et la livraison continue (CI/CD) à l’aide d’Azure Data Factory