適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
この記事では、Azure Data Factory パイプラインと Synapse Analytics パイプラインでコピー アクティビティを使用して、Azure Database for PostgreSQLとの間でデータをコピーする方法について説明します。 また、Data Flowを使用してAzure Database for PostgreSQL内のデータを変換する方法も示します。 詳細については、Azure Data Factory および Synapse Analytics の入門記事を参照してください。
重要
Azure Database for PostgreSQL バージョン 2.0 では、ネイティブ Azure Database for PostgreSQLのサポートが強化されています。 ソリューションで Azure Database for PostgreSQL バージョン 1.0 を使用している場合は、できるだけ早くAzure Database for PostgreSQL コネクタをアップグレードすることをお勧めします。
このコネクタは、Azure Database for PostgreSQL サービス専用です。 オンプレミスまたはクラウドにある汎用 PostgreSQL データベースからデータをコピーするには、PostgreSQL コネクタを使用します。
サポートされる機能
このAzure Database for PostgreSQL コネクタは、次の機能でサポートされています。
| サポートされる機能 | IR | マネージド プライベート エンドポイント | コネクタでサポートされているバージョン |
|---|---|---|---|
| Copy アクティビティ (ソース/シンク) | (1) (2) | 1.0 & 2.0 | |
| マッピング データ フロー (ソース/シンク) | ① | 1.0 & 2.0 | |
| Lookup アクティビティ | (1) (2) | 1.0 & 2.0 | |
| スクリプト活動 | (1) (2) | 2.0 |
(1) Azure統合ランタイム (2) セルフホステッド統合ランタイム
3 つのアクティビティはAzure Database for PostgreSQL Single Server、Flexible Server、および PostgreSQL 用の Azure Cosmos DB で動作します。
重要
Azure Database for PostgreSQL Single Server は、2025 年 3 月 28 日に廃止されます。 その日までにフレキシブル サーバーに移行します。 移行ガイダンスについては、この 記事 と FAQ を参照してください。
作業の開始
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
- データのコピー ツール
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager テンプレート
Azure Database for PostgreSQLへのリンクされたサービスをUIを使用して作成する
次の手順を使用して、Azure ポータルの UI で PostgreSQL 向けの Azure データベースにリンクされたサービスを作成します。
Azure Data Factoryまたは Synapse ワークスペースの [管理] タブを参照し、[リンクされたサービス] を選択し、[新規] を選択します。
- Azureデータファクトリー
- Azure Synapse
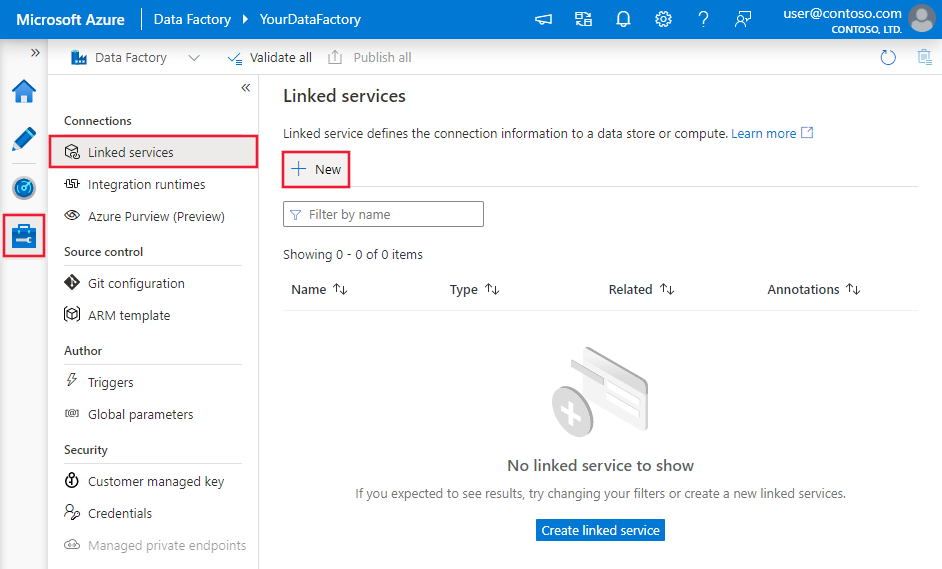
PostgreSQL を検索し、PostgreSQL コネクタ用のAzure データベースを選択します。
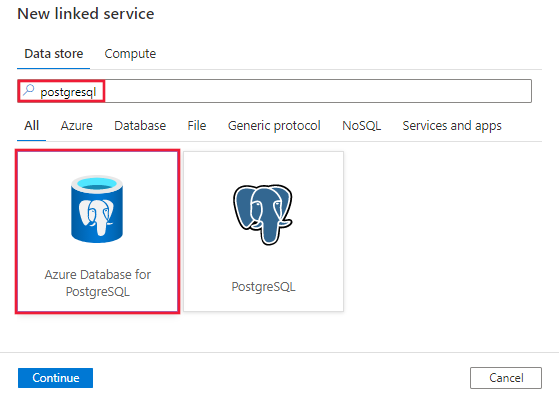
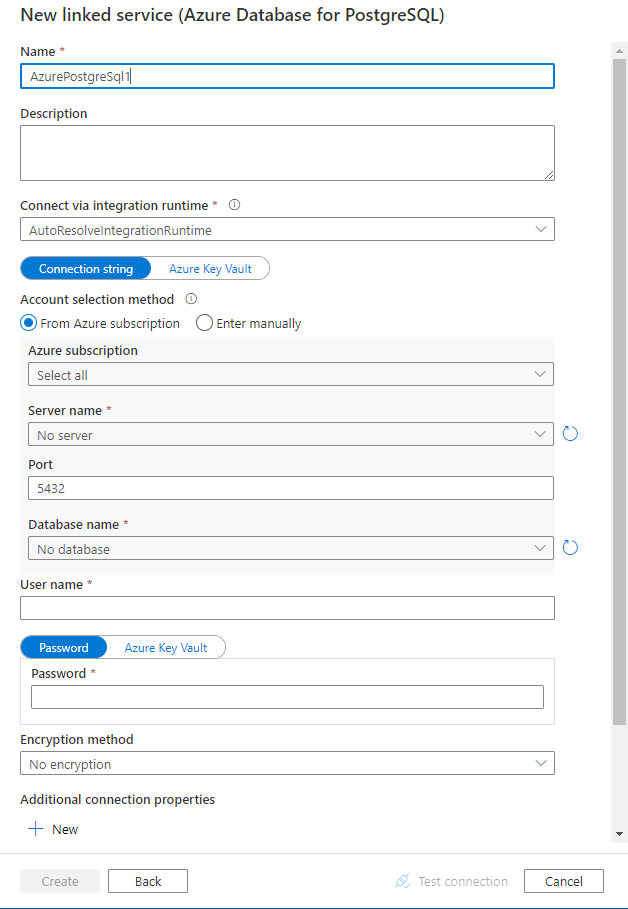
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
次のセクションでは、Azure Database for PostgreSQL コネクタに固有の Data Factory エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Azure Database for PostgreSQL コネクタ バージョン 2.0 では、トランスポート層セキュリティ (TLS) 1.3 モードと複数のセキュリティで保護されたソケット層 (SSL) モードがサポートされています。 Azure SQL Database コネクタのバージョンをバージョン 1.0 からアップグレードするには、この section を参照してください。 プロパティの詳細については、対応するセクションを参照してください。
バージョン 2.0
バージョン 2.0 を適用すると、Azure Database for PostgreSQLのリンクされたサービスで次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティは、AzurePostgreSql に設定する必要があります。 | はい |
| バージョン | 指定するバージョン。 値は 2.0 です。 |
はい |
| 認証タイプ | 基本、サービス プリンシパル、システム割り当てマネージド ID、またはユーザー割り当てマネージド ID 認証の種類から選択する | はい |
| サーバー | ホスト名と、必要に応じて、Azure Database for PostgreSQLが実行されているポートを指定します。 | はい |
| ポート | Azure Database for PostgreSQL サーバーの TCP ポート。 既定値は 5432 です。 |
いいえ |
| データベース | 接続するAzure Database for PostgreSQL データベースの名前。 | はい |
| SSLモード | サーバーのサポートに応じて、SSL を使用するかどうかを制御します。 - 無効: SSL は無効です。 サーバーで SSL が必要な場合、接続は失敗します。 - Allow: サーバーで許可されている場合は非 SSL 接続が優先されますが、SSL 接続も許可されます。 - 推奨: サーバーで許可されている場合は SSL 接続を優先しますが、SSL を使用しない接続は許可します。 - 必須: サーバーが SSL をサポートしていない場合、接続は失敗します。 - Verify_ca: サーバーが SSL をサポートしていない場合、接続は失敗します。 サーバー証明書の検証も行われます。 - Verify_full: サーバーが SSL をサポートしていない場合、接続は失敗します。 ホスト名を含むサーバー証明書の検証も行われます。 オプション: 無効 (0) / 許可 (1) / 優先 (2) (既定値) / 必須 (3) / Verify_ca (4) / Verify_full (5) |
いいえ |
| connectVia (接続ビア) | このプロパティは、データ ストアに接続するために使用される統合ランタイムを表します。 Azure Integration Runtimeまたはセルフホステッド Integration Runtimeを使用できます (データ ストアがプライベート ネットワークにある場合)。 指定しない場合は、既定のAzure Integration Runtimeが使用されます。 | いいえ |
| 追加の接続プロパティ: | ||
| スキーマ | スキーマ検索パスを設定します。 | いいえ |
| pooling | 接続プールを使用する必要があるかどうか。 | いいえ |
| 接続タイムアウト | 接続を確立する際、試行を終了してエラーを生成するまでに待機する時間 (秒)。 | いいえ |
| commandTimeout | コマンドを実行しようとする際の試行中に、試行を打ち切ってエラーを生成するまでの待機時間 (秒数)。 無限の場合はゼロに設定されます。 | いいえ |
| サーバー証明書を信頼する | サーバー証明書を検証せずに信頼するかどうか。 | いいえ |
| リードバッファサイズ (readBufferSize) | Npgsql が読み込み時に使用する内部バッファーのサイズを決定します。 データベースから大きな値を転送する場合、この値を増やすとパフォーマンスが向上する可能性があります。 | いいえ |
| タイムゾーン | セッション タイムゾーンを取得または設定します。 | いいえ |
| エンコード | PostgreSQL 文字列データをエンコード/デコードするための.NET エンコードを取得または設定します。 | いいえ |
基本認証
| プロパティ | 説明 | 必須 |
|---|---|---|
| ユーザー名 | 接続するためのユーザー名。 IntegratedSecurity を使用している場合は必要ありません。 | はい |
| パスワード | 接続するためのパスワード。 IntegratedSecurity を使用している場合は必要ありません。 安全に保存するには、このフィールドを SecureString としてマークします。 または、Azure Key Vaultに格納されているシークレットを |
はい |
例:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
例:
パスワードをAzure Key Vaultに格納する
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
システム割り当てマネージド ID 認証
データ ファクトリまたは Synapse ワークスペースは、Azure内の他のリソースに対する認証時にサービスを表す System 割り当てマネージド ID に関連付けることができます。 このマネージド ID は、PostgreSQL 認証用の Azure データベースに使用できます。 指定されたファクトリまたは Synapse ワークスペースでは、この ID を使用してデータベースにアクセスし、データベースとの間でデータをコピーできます。
システム割り当てマネージド ID を使用するには、次の手順に従います。
データ ファクトリまたは Synapse ワークスペースは、システム割り当てマネージド ID に関連付けることができます。 詳細については、 システム割り当てマネージド ID を生成する
システム割り当てマネージド ID On を持つ PostgreSQL のAzure データ。
Azure データベースの PostgreSQL サーバーにおけるシステムに割り当てられたマネージド ID 構成のスクリーンショット PostgreSQL 用 Azure データベースのリソース内の Security
認証を選択
Microsoft Entra認証のみ または PostgreSQL と Microsoft Entra 認証 のどちらかの認証方法を選択します。
[+ Microsoft Entra 管理者の追加] を選択します
Azure Data Factory リソースのシステム割り当てマネージド ID を、
Microsoft Entra Administrators 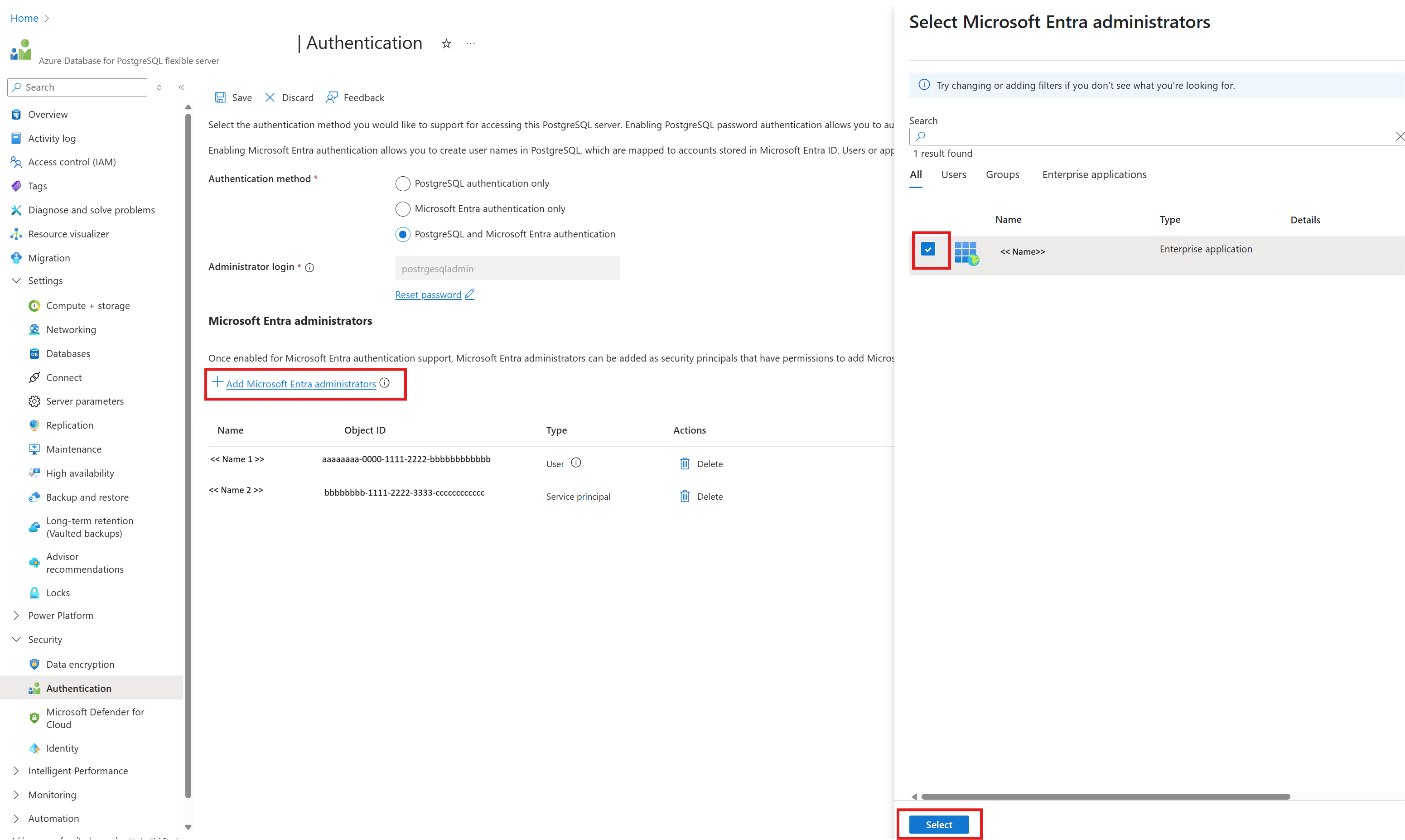
PostgreSQL のリンクされたサービスのAzure データベースを構成します。

例:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "SystemAssignedManagedIdentity"
}
}
}
注
この認証の種類は、セルフホステッド統合ランタイムではサポートされていません。
ユーザー割り当てマネージド ID 認証
データ ファクトリまたは Synapse ワークスペースは、Azure内の他のリソースに対する認証時にサービスを表す User 割り当てマネージド ID に関連付けることができます。 このマネージド ID は、PostgreSQL 認証用の Azure データベースに使用できます。 指定されたファクトリまたは Synapse ワークスペースでは、この ID を使用してデータベースにアクセスし、データベースとの間でデータをコピーできます。
前のセクションで説明した汎用的なプロパティに加えて、ユーザー割り当てマネージド ID 認証を使用するには、次のプロパティを指定します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 資格情報 | ユーザー割り当てマネージド ID を資格情報オブジェクトとして指定します。 | はい |
また、次の手順に従う必要があります。
Azureポータルで ユーザー割り当て済みマネージド ID リソースを作成してください。 詳細については、「ユーザー割り当てマネージド ID の管理」を参照してください
PostgreSQL リソースの Azure データベースに User 割り当てマネージド ID を割り当てる
Azure Database for PostgreSQL サーバーリソースのセキュリティセクションにおいて
認証を選択
認証方法が Microsoft Entra 認証のみ または PostgreSQL と Microsoft Entra 認証であるかどうかを確認します
+ Microsoft Entra 管理者を追加 リンクを選択し、ユーザーに割り当てられたマネージド ID を選択します。

Azure Data Factory リソースに User 割り当てマネージド ID を割り当てる
[設定] を選択し、[マネージド ID] を選択します
[ ユーザー割り当て ] タブの下。 [+ 追加] リンクを選択し、ユーザーマネージド ID を選択します

PostgreSQL のリンクされたサービスのAzure データベースを構成します。


例:
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "<your credential>",
"type": "CredentialReference"
}
}
}
}
サービス プリンシパルの認証
| プロパティ | 説明 | 必須 |
|---|---|---|
| ユーザー名 | サービス プリンシパルの表示名 | はい |
| テナント | Azure Database for PostgreSQL サーバーが配置されているテナント | はい |
| サービスプリンシパルID (servicePrincipalId) | サービス プリンシパルのアプリケーション ID | はい |
| servicePrincipalCredentialType | サービス プリンシパル証明書またはサービス プリンシパル キーが必要な認証方法かどうかを選択する - ServicePrincipalCert: サービス プリンシパル証明書のサービス プリンシパル証明書に設定します。 - ServicePrincipalKey: サービス プリンシパル キー認証のサービス プリンシパル キーに設定します。 |
はい |
| servicePrincipalKey(サービスプリンシパルキー) | クライアント シークレット値。 サービス プリンシパル キーが選択されている場合に使用されます | はい |
| Azureクラウドタイプ | Azure Database for PostgreSQL サーバーのAzureクラウドの種類を選択します | はい |
| サービスプリンシパル組み込み証明書 | サービス プリンシパル証明書ファイル | はい |
| servicePrincipalEmbeddedCertPassword | 必要な場合はサービス プリンシパル証明書のパスワード | いいえ |
例:
サービス プリンシパル キー
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalKey": "<service principal key>"
}
}
}
例:
サービス プリンシパル証明書
{
"name": "AzurePostgreSqlLinkedService",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"annotations": [],
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": 5432,
"database": "<database name>",
"sslMode": 2,
"username": "<service principal name>",
"authenticationType": "<authentication type>",
"tenant": "<tenant>",
"servicePrincipalId": "<service principal ID>",
"azureCloudType": "<azure cloud type>",
"servicePrincipalCredentialType": "<service principal type>",
"servicePrincipalEmbeddedCert": "<service principal certificate>",
"servicePrincipalEmbeddedCertPassword": "<service principal embedded certificate password>"
}
}
}
注
セルフホステッド統合ランタイム バージョン 5.50 以降では、サービス プリンシパルとユーザー割り当てマネージド ID を使用したMicrosoft Entra ID認証がサポートされています。
バージョン 1.0
バージョン 1.0 を適用すると、Azure Database for PostgreSQLのリンクされたサービスで次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティは、AzurePostgreSql に設定する必要があります。 | はい |
| バージョン | 指定するバージョン。 値は 1.0 です。 |
はい |
| コネクションストリング | PostgreSQL 用 Azure Database に接続するための Npgsql の接続文字列。 Azure Key Vaultにパスワードを入力し、connection stringから password 構成をプルすることもできます。 詳細については、次のサンプルと Store credentials in Azure Key Vault を参照してください。 |
はい |
| connectVia (接続ビア) | このプロパティは、データ ストアに接続するために使用される統合ランタイムを表します。 Azure Integration Runtimeまたはセルフホステッド Integration Runtimeを使用できます (データ ストアがプライベート ネットワークにある場合)。 指定しない場合は、既定のAzure Integration Runtimeが使用されます。 | いいえ |
一般的なconnection stringは host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password> です。 ケースごとにさらに多くのプロパティを設定できます。それらのプロパティを次に示します。
| プロパティ | 説明 | オプション | 必須 |
|---|---|---|---|
| EncryptionMethod (EM) | ドライバーとデータベース サーバー間で送信されるデータを暗号化するためにドライバーが使用するメソッド。 たとえば、EncryptionMethod=<0/1/6>; のように指定します。 |
0 (暗号化なし) (既定) /1 (SSL)/6 (RequestSSL) | いいえ |
| ValidateServerCertificate (VSC) | SSL 暗号化が有効 (Encryption Method=1) になっているときに、データベース サーバーによって送信される証明書をドライバーが検証するかどうかを決定します。 たとえば、ValidateServerCertificate=<0/1>; のように指定します。 |
0 (無効) (既定) / 1 (有効) | いいえ |
例:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;password=<password>"
}
}
}
例:
パスワードをAzure Key Vaultに格納する
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.azure.com;database=<database>;port=<port>;uid=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
データセットのプロパティ
データセットの定義に使用できるセクションとプロパティの一覧については、データセットに関する記事をご覧ください。 このセクションでは、データセットでサポートAzure Database for PostgreSQLプロパティの一覧を示します。
Azure Database for PostgreSQLからデータをコピーするには、データセットの type プロパティを AzurePostgreSqlTable に設定します。 次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | データセットの type プロパティは 、AzurePostgreSqlTable に設定する必要があります。 | はい |
| スキーマ | スキーマの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| テーブル | テーブル/ビューの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| テーブル名 | テーブルの名前。 このプロパティは下位互換性のためにサポートされています。 新しいワークロードでは、schema と table を使用します。 |
いいえ (アクティビティ ソースの "query" が指定されている場合) |
例:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Copy activity のプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインおよびアクティビティに関するページを参照してください。 このセクションでは、Azure Database for PostgreSQL ソースでサポートされるプロパティの一覧を示します。
Azure Database for PostgreSQL をソースとして
Azure Database for PostgreSQLからデータをコピーするには、コピー アクティビティのソースの種類を AzurePostgreSqlSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | コピー アクティビティのソースの type プロパティは AzurePostgreSqlSource に設定する必要があります | はい |
| クエリ | カスタム SQL クエリを使用してデータを読み取ります。 たとえば、SELECT * FROM mytable や SELECT * FROM "MyTable" などです。 PostgreSQL では、エンティティ名が引用符で囲まれていない場合、大文字と小文字が区別されません。 |
いいえ (データセットの tableName プロパティが指定されている場合) |
| queryTimeout | コマンド実行の試行を終了してエラーを生成するまでの待機時間。既定値は 120 分です。 このプロパティにパラメーターを設定する場合、使用できる値は "02:00:00" (120 分) などの期間です。 詳細については、「CommandTimeout」を参照してください。 | いいえ |
| パーティションオプション | Azure SQL Databaseからデータを読み込むのに使用するデータパーティション分割オプションを指定します。 使用できる値は、None (既定値)、PhysicalPartitionsOfTable、DynamicRange です。 パーティション オプションが有効になっている (つまり、 None ではない) 場合、Azure SQL Databaseから同時にデータを読み込む並列処理の程度は、コピー アクティビティの parallelCopies 設定によって制御されます。 |
いいえ |
| パーティション設定 | データ パーティション分割の設定のグループを指定します。 パーティション オプションが None でない場合に適用されます。 |
いいえ |
partitionSettings の下: |
||
| partitionNames | コピーする必要がある物理パーティションのリスト。 パーティション オプションが PhysicalPartitionsOfTable である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfTabularPartitionName をフックします。 例については、「Azure Database for PostgreSQL からの Parallel コピー」セクションを参照してください。 |
いいえ |
| パーティションカラム名 | 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (int、smallint、bigint、date、timestamp without time zone、timestamp with time zone または time without time zone) のソース列の名前を指定します。 指定されていない場合は、テーブルの主キーが自動検出され、パーティション列として使用されます。パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionColumnName をフックします。 例については、「Azure Database for PostgreSQL からの Parallel コピー」セクションを参照してください。 |
いいえ |
| partitionUpperBound | データをコピーするパーティション列の最大値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionUpbound をフックします。 例については、「Azure Database for PostgreSQL からの Parallel コピー」セクションを参照してください。 |
いいえ |
| partitionLowerBound | データをコピーするパーティション列の最小値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionLowbound をフックします。 例については、「Azure Database for PostgreSQL からの Parallel コピー」セクションを参照してください。 |
いいえ |
例:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
PostgreSQL 向け Azure データベースをシンクとして使用
データをAzure Database for PostgreSQLにコピーするには、コピー アクティビティのシンクの種類を SqlSink に設定します。 コピー アクティビティの sink セクションでは、次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 | コネクタのサポート バージョン |
|---|---|---|---|
| 型 | コピー アクティビティのシンクの type プロパティは AzurePostgreSQLSink に設定する必要があります | はい | バージョン 1.0 とバージョン 2.0 |
| preCopyScript | 各実行でデータをAzure Database for PostgreSQLに書き込む前に、コピー アクティビティを実行するための SQL クエリを指定します。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。 | いいえ | バージョン 1.0 とバージョン 2.0 |
| writeMethod | Azure Database for PostgreSQLにデータを書き込むのに使用するメソッド。 使用できる値は 、CopyCommand (既定ではパフォーマンスが高い)、 BulkInsert 、 Upsert (バージョン 2.0 のみ) です。 |
いいえ | バージョン 1.0 とバージョン 2.0 |
| upsertSettings | 書き込み動作の設定のグループを指定します。 WriteBehavior オプションが Upsert である場合に適用します。 |
いいえ | バージョン 2.0 |
upsertSettings の下: |
|||
| キー | 行を一意に識別するための列名を指定します。 1 つのキーまたは一連のキーを使用できます。 キーは、主キーまたは一意の列である必要があります。 指定しない場合は、主キーが使用されます。 | いいえ | バージョン 2.0 |
| writeBatchSize | バッチごとにAzure Database for PostgreSQLに読み込まれる行の数。 許可される値は行数を表す整数です。 |
いいえ (既定値は 1,000,000) | バージョン 1.0 とバージョン 2.0 |
| writeBatchTimeout | タイムアウトする前に一括挿入操作の完了を待つ時間です。 Timespan 文字列を値として使用できます。 たとえば "00:30:00" (30 分) を指定できます。 |
いいえ (既定値は 00:30:00) | バージョン 1.0 とバージョン 2.0 |
例 1: コピーコマンド
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSqlSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
例 2: データのアップサート
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"writeMethod": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
]
},
}
}
}
]
データをアップサートする
Copy activityはアップサート操作をネイティブにサポートします。 アップサートを実行するには、ユーザーは主キーまたは一意の列であるキー列を指定する必要があります。 ユーザーがキー列を指定しない場合は、シンク テーブルの主キー列が使用されます。 コピー アクティビティは、キー列の値がソース テーブルのキー列の値と一致するシンク テーブル内のキー以外の列を更新します。それ以外の場合は、新しいデータが挿入されます。
Azure Database for PostgreSQLからの並列コピー
コピー アクティビティのAzure Database for PostgreSQL コネクタでは、データを並列にコピーするための組み込みのデータ パーティション分割が提供されます。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
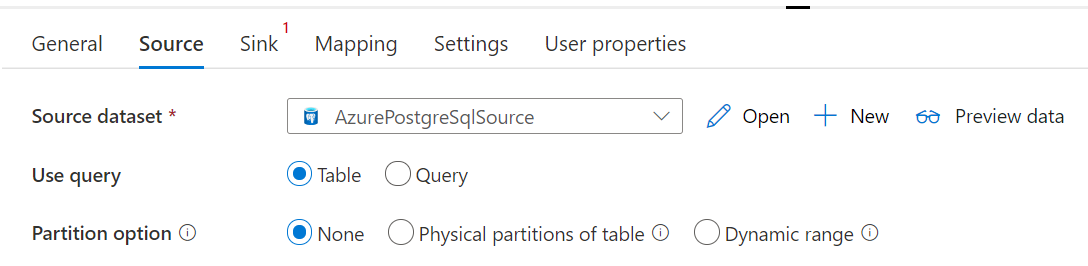
パーティション分割コピーを有効にすると、コピー アクティビティは、パーティションごとにデータを読み込むAzure Database for PostgreSQL ソースに対して並列クエリを実行します。 並列度は、コピー アクティビティの parallelCopies 設定によって制御されます。 たとえば、parallelCopies を 4 に設定すると、サービスは、指定したパーティション オプションと設定に基づいて 4 つのクエリを同時に生成して実行し、各クエリはAzure Database for PostgreSQLからデータの一部を取得します。
特にAzure Database for PostgreSQLから大量のデータを読み込む場合は、データパーティション分割を使用して並列コピーを有効にすることをお勧めします。 さまざまなシナリオの推奨構成を以下に示します。 ファイル ベースのデータ ストアにデータをコピーする場合は、フォルダーに複数のファイルとして書き込む (フォルダー名のみを指定する) ようにすることをお勧めします。その場合、パフォーマンスは 1 つのファイルに書き込むよりも優れています。
| シナリオ | 推奨設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 |
パーティション オプション: テーブルの物理パーティション。 実行中に、サービスによって物理パーティションが自動的に検出され、パーティションごとにデータがコピーされます。 |
| 物理パーティションがなく、データ パーティション分割用の整数列がある大きなテーブル全体から読み込む。 |
パーティション オプション: ダイナミック レンジ パーティション。 パーティション列: データのパーティション分割に使う列を指定します。 指定されていない場合は、主キー列が使用されます。 |
| カスタム クエリを使用して大量のデータを読み込む (物理パーティションがある場合)。 |
パーティション オプション: テーブルの物理パーティション。 クエリ: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>パーティション名: データのコピー元のパーティション名を 1 つ以上指定します。 指定されていない場合は、PostgreSQL データセットで指定したテーブルの物理パーティションがサービスによって自動検出されます。 実行中、サービスは ?AdfTabularPartitionName を実際のパーティション名に置き換え、Azure Database for PostgreSQLに送信します。 |
| カスタム クエリを使用して大量のデータを読み込む (物理パーティションがなく、データ パーティション分割用の整数列がある場合)。 |
パーティション オプション: ダイナミック レンジ パーティション。 クエリ: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>パーティション列: データのパーティション分割に使う列を指定します。 整数データ型または date/datetime データ型の列に対してパーティション分割を実行できます。 パーティションの上限 と パーティションの下限: パーティション列に対してフィルター処理して、下限と上限の範囲の間でのみデータを取得するかどうかを指定します。 実行中、サービスは、 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound、および ?AdfRangePartitionLowboundを各パーティションの実際の列名と値の範囲に置き換え、Azure Database for PostgreSQLに送信します。 たとえば、パーティション列 "ID" が下限を 1 に、上限が 80 に設定され、並列コピーが 4 に設定されている場合、サービスは 4 つのパーティションでデータを取得します。 これらの ID の範囲はそれぞれ [1, 20]、[21, 40]、[41, 60]、[61, 80] です。 |
パーティション オプションを使用してデータを読み込む場合のベスト プラクティス:
- データ スキューを回避するため、パーティション列 (主キーや一意キーなど) には特徴のある列を選択します。
- テーブルに組み込みパーティションがある場合は、パフォーマンスを向上させるためにパーティション オプションとして "テーブルの物理パーティション" を使用します。
- Azure Integration Runtimeを使用してデータをコピーする場合は、より大きな "Data Integration Units (DIU)" (>4) を設定して、より多くのコンピューティング リソースを利用できます。 そこで、該当するシナリオを確認してください。
- "コピーの並列処理の次数" はパーティション番号を制御します。この数を大きすぎると、パフォーマンスが低下することがあります。 この数を (DIU またはセルフホステッド IR ノードの数) * (2 から 4) に設定することをお勧めします。
例: 複数の物理パーティションがある大きなテーブル全体から読み込む
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
例: 動的範囲パーティションを使用してクエリを実行する
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Mapping Data Flow のプロパティ
マッピング データ フローでデータを変換するときに、Azure Database for PostgreSQLからテーブルの読み取りと書き込みを行うことができます。 詳細については、マッピング データ フローのソース変換とシンク変換に関する記事を参照してください。 ソースとシンクの種類として、Azure Database for PostgreSQL データセットまたは inline データセット を使用できます。
注
現時点では、マッピング データ フローの Azure Database for PostgreSQL コネクタの V1 バージョンと V2 バージョンの両方で基本認証のみがサポートされています。
ソース変換
次の表に、Azure Database for PostgreSQL ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、[ソース オプション] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| テーブル | [テーブル] を入力として選択した場合、データセットで指定されたテーブルからすべてのデータがデータ フローによってフェッチされます。 | いいえ | - |
(インライン データセットのみ) テーブル名 |
| クエリ | [クエリ] を入力として選択した場合は、ソースからデータをフェッチする SQL クエリを指定します。これにより、データセットで指定したテーブルがオーバーライドされます。 テストまたはルックアップ対象の行を減らすうえで、クエリの使用は有効な手段です。 Order By 句はサポートされていませんが、完全な SELECT FROM ステートメントを設定できます。 ユーザー定義のテーブル関数を使用することもできます。 select * from udfGetData() は、データ フローで使用できるテーブルを返す SQL の UDF です。 クエリ例: select * from mytable where customerId > 1000 and customerId < 2000 または select * from "MyTable"。 PostgreSQL では、エンティティ名が引用符で囲まれていない場合、大文字と小文字が区別されません。 |
いいえ | 糸 | クエリ |
| [スキーマ名] | 入力としてストアド プロシージャを選択する場合、ストアド プロシージャのスキーマを指定するか、[更新] を選択し、スキーマ名を検出するようにサービスに要求します。 | いいえ | 糸 | スキーマ名 |
| ストアド プロシージャ | 入力として [ストアド プロシージャ] を選択する場合、ソース テーブルからデータを読み込むストアド プロシージャの名前を指定するか、[更新] を選択し、プロシージャ名を検出するようにサービスに要求します。 | はい ([ストアド プロシージャ] を入力として選択した場合) | 糸 | 手順名 |
| プロシージャのパラメーター | 入力として [ストアド プロシージャ] を選択した場合、プロシージャで設定された順序でストアド プロシージャの入力パラメーターを指定するか、[インポート] を選択し、フォーム @paraName を使用してすべてのプロシージャ パラメーターをインポートします。 |
いいえ | Array | inputs |
| バッチ サイズ | 大量データをバッチにまとめるバッチ サイズを指定します。 | いいえ | 整数 | batchSize |
| 分離レベル | 次のいずれかの分離レベルを選択します。 - コミットされたものを読み取り - コミットされていないものを読み取り (既定値) - 反復可能読み取り - シリアル化可能 - なし (分離レベルを無視) |
いいえ | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE なし |
分離レベル (isolationLevel) |
Azure Database for PostgreSQL ソース スクリプトの例
ソースの種類としてAzure Database for PostgreSQLを使用する場合、関連するデータ フロー スクリプトは次のようになります。
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
シンク変換
次の表は、Azure Database for PostgreSQL のシンクでサポートされるプロパティを示します。 これらのプロパティは、[シンク オプション] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| 更新方法 | 対象となるデータベースに対して許可される操作を指定します。 既定では、挿入のみが許可されます。 行を更新、アップサート、または削除するには、それらのアクションに対して行をタグ付けするために行の変更変換が必要になります。 |
はい |
true または false |
削除可能 insertable updateable upsertable |
| [キー列] | 更新、アップサート、および削除の場合は、変更する行を決定するためにキー列を設定する必要があります。 キーとして選択した列名は、後続の更新、アップサート、削除の一部として使用されます。 そのため、シンク マッピングに存在する列を選択する必要があります。 |
いいえ | Array | キー |
| Skip writing key columns\(キー列の書き込みをスキップする) | キー列に値を書き込まない場合は、[Skip writing key columns]\(キー列の書き込みをスキップする\) を選択します。 | いいえ |
true または false |
skipKeyWrites |
| テーブル アクション | 書き込む前に、コピー先テーブルのすべての行を再作成するか削除するかを決定します。 - なし: テーブルに対するアクションは実行されません。 - 再作成: テーブルが削除され、再作成されます。 新しいテーブルを動的に作成する場合に必要です。 - 切り捨て: ターゲット テーブルのすべての行が削除されます。 |
いいえ |
true または false |
recreate 切り詰める |
| バッチ サイズ | 各バッチで書き込まれる行の数を指定します。 バッチ サイズを大きくすると、圧縮とメモリの最適化が向上しますが、データをキャッシュする際にメモリ不足の例外が発生するリスクがあります。 | いいえ | 整数 | batchSize |
| ユーザー DB スキーマの選択 | 既定では、一時テーブルはステージングとしてシンク スキーマの下に作成されます。 または、[ シンク スキーマを使用 する] オプションをオフにして、代わりに、Data Factory がステージング テーブルを作成してアップストリーム データを読み込み、完了時に自動的にクリーンアップするスキーマ名を指定することもできます。 データベースにテーブルの作成権限があり、スキーマに対する変更権限があることを確認します。 | いいえ | 糸 | stagingSchemaName |
| 事前および事後の SQL スクリプト | データがシンク データベースに書き込まれる前 (前処理) および後 (後処理) に実行される複数行の SQL スクリプトを指定します。 | いいえ | 糸 | preSQLs postSQLs |
ヒント
- 複数のコマンドを含む 1 つのバッチ スクリプトを複数のバッチに分割します。
- バッチの一部として実行できるのは、単純に更新数を返すデータ操作言語 (DML) ステートメントおよびデータ定義言語 (DDL) ステートメントだけです。 詳細については、「バッチ操作の実行」を参照してください
増分抽出を有効にする: このオプションを使用して、パイプラインが最後に実行されてから変更された行のみを処理するように ADF に指示します。
増分日付列: 増分抽出機能を使う場合は、ソース テーブルのウォーターマークとして使う日時列を選ぶ必要があります。
最初から読み取りを開始する: このオプションを増分抽出で設定すると、増分抽出が有効になっているパイプラインの最初の実行時にすべての行を読み取るよう ADF に指示されます。
PostgreSQL 用 Azure データベースのシンク スクリプトの例
シンクの種類としてAzure Database for PostgreSQLを使用する場合、関連するデータ フロー スクリプトは次のようになります。
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSqlSink
スクリプト活動
重要
スクリプト アクティビティは、バージョン 2.0 コネクタでのみサポートされています。
重要
出力パラメーターを使用する複数クエリ ステートメントはサポートされていません。 出力クエリは、同じまたは異なるスクリプト アクティビティ内で個別のスクリプト ブロックに分割することをお勧めします。
位置指定パラメーターを使用する複数クエリ ステートメントはサポートされていません。 位置指定クエリは、同じまたは異なるスクリプト アクティビティ内で個別のスクリプト ブロックに分割することをお勧めします。
スクリプト アクティビティの詳細については、「スクリプト アクティビティ」を参照してください。
Lookup アクティビティのプロパティ
プロパティの詳細については、ルックアップ アクティビティに関する記事を参照してください。
Azure Database for PostgreSQL コネクタをアップグレードする
[リンクされたサービスの編集] ページで、[バージョン] で 2.0 を選択し、リンクされたサービスプロパティバージョン 2.0 を参照してリンクされたサービスを構成します。
関連コンテンツ
コピー アクティビティによってソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。