適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
この記事では、Azure Data Factory パイプラインまたはAzure Synapse パイプラインでコピー アクティビティを使用してデータをコピーしたり、Azure SQL Databaseにコピーしたり、Data Flowを使用してAzure SQL Database内のデータを変換したりする方法について説明します。 詳細については、Azure Data Factory または Azure Synapse Analytics の入門記事を参照してください。
サポートされる機能
このAzure SQL Database コネクタは、次の機能でサポートされています。
| サポートされる機能 | IR | マネージド プライベート エンドポイント |
|---|---|---|
| Copy アクティビティ (ソース/シンク) | (1) (2) | ✓ |
| マッピング データ フロー (ソース/シンク) | ① | ✓ |
| Lookup アクティビティ | (1) (2) | ✓ |
| GetMetadata アクティビティ | (1) (2) | ✓ |
| スクリプト アクティビティ | (1) (2) | ✓ |
| ストアド プロシージャ アクティビティ | (1) (2) | ✓ |
(1) Azure統合ランタイム (2) セルフホステッド統合ランタイム
Copy activityの場合、このAzure SQL Database コネクタは次の関数をサポートします。
- SQL 認証と Microsoft Entra アプリケーション トークン認証を使用して、Azure リソースに対するサービス プリンシパルまたはマネージド ID を用いてデータをコピーします。
- ソースとして、SQL クエリまたはストアド プロシージャを使用してデータを取得する。 また、Azure SQL Database ソースから並列コピーを選択することもできます。詳細については、「SQL database からのパラメーター コピー」セクションを参照してください。
- シンクとして、ソース スキーマに基づいて、宛先テーブルが存在しない場合はこれを自動的に作成する。テーブルにデータを追加するか、コピー中にカスタム ロジックを使用してストアド プロシージャを呼び出す。
Azure SQL Database サーバーレスレベルを使用する場合は、サーバーが一時停止されると、自動再開の準備が整うのを待たずにアクティビティの実行が失敗することに注意してください。 実際の実行時に確実にサーバーを稼働した状態にするには、アクティビティの再試行を追加するか、追加のアクティビティを連鎖させます。
重要
Azure統合ランタイムを使用してデータをコピーする場合は、サーバー レベルのファイアウォール規則Azure サービスがサーバーにアクセスできるように構成します。 セルフホステッド統合ランタイムを使用してデータをコピーする場合は、適切な IP 範囲を許可するようにファイアウォールを構成します。 この範囲には、Azure SQL Databaseへの接続に使用されるコンピューターの IP が含まれます。
概要
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
- データのコピー ツール
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager テンプレート
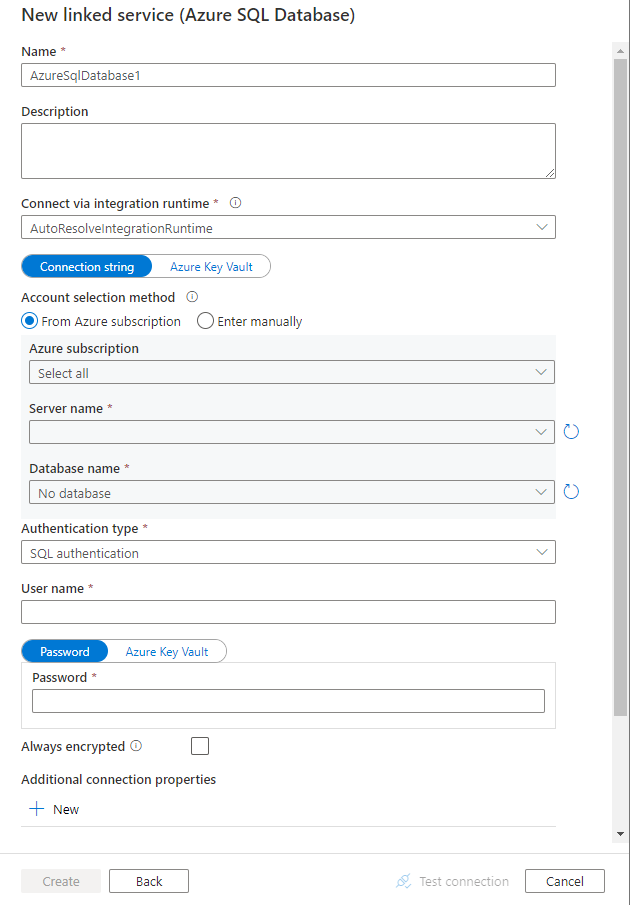
UI を使用してAzure SQL Databaseリンクされたサービスを作成する
Azure ポータル UI でAzure SQL Databaseリンクされたサービスを作成するには、次の手順に従います。
Azure Data Factoryまたは Synapse ワークスペースの [管理] タブを参照し、[リンクされたサービス] を選択し、[新規] をクリックします。
- Azureデータファクトリー
- Azure Synapse
Azure Data Factory UI を使用した新しいリンク サービスの作成のスクリーンショット SQL を検索し、Azure SQL Database コネクタを選択します。

サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
次のセクションでは、Azure SQL Database コネクタに固有のAzure Data Factoryまたは Synapse パイプライン エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Azure SQL Database コネクタ Recommended バージョンでは TLS 1.3 がサポートされています。 この section を参照して、Azure SQL Database コネクタのバージョンを Legacy 1 からアップグレードします。 プロパティの詳細については、対応するセクションを参照してください。
ヒント
エラー コード "UserErrorFailedToConnectToSqlServer" でエラーが発生し、"The session limit for the database is XXX and been been reached" のようなメッセージが表示された場合は、connection stringに Pooling=false を追加して、もう一度やり直してください。
Pooling=false は、SHIR(セルフ ホステッド Integration Runtime) 型のリンクされたサービスのセットアップにも推奨されます。 プーリングおよびその他の接続パラメーターは、リンクされたサービスの作成フォームにある [追加の接続プロパティ] セクションに新しいパラメーターの名前と値として追加できます。
推奨されるバージョン
これらのジェネリック プロパティは、Recommended バージョンを適用するときに、Azure SQL Databaseのリンクされたサービスでサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティを AzureSqlDatabase に設定する必要があります。 | はい |
| サーバー | 接続先の SQL Server インスタンスの名前またはネットワーク アドレス。 | はい |
| データベース | データベースの名前。 | はい |
| authenticationType | 認証に使用される型。 使用できる値は、SQL (既定値)、ServicePrincipal、SystemAssignedManagedIdentity、UserAssignedManagedIdentity です。 特定のプロパティと前提条件に関する関連する認証セクションに移動します。 | はい |
| alwaysEncryptedSettings | マネージド ID またはサービス プリンシパルを使用して、SQL サーバーに格納されている機密データを保護する Always Encrypted を有効にするために必要な alwaysencryptedsettings 情報を指定します。 詳細については、この表の後にある JSON の例および「Always Encrypted の使用」を参照してください。 指定されていない場合、既定の always encrypted 設定は無効になります。 | いいえ |
| 暗号化する | クライアントとサーバーの間で送信されるすべてのデータに TLS 暗号化が必要かどうかを示します。 オプション: 必須 (true の場合、既定値)/省略可能 (false の場合)/strict。 | いいえ |
| trustServerCertificate | 信頼を検証するための証明書チェーンをバイパスする間、チャネルが暗号化されるかどうかを示します。 | いいえ |
| hostNameInCertificate | 接続のサーバー証明書を検証するときに使用するホスト名。 指定しない場合、サーバー名が証明書の検証に使用されます。 | いいえ |
| connectVia | この統合ランタイムは、データ ストアに接続するために使用されます。 データ ストアがプライベート ネットワークにある場合は、Azure統合ランタイムまたはセルフホステッド統合ランタイムを使用できます。 指定しない場合は、既定のAzure統合ランタイムが使用されます。 | いいえ |
その他の接続プロパティについては、次の表を参照してください。
| プロパティ | 説明 | 必須 |
|---|---|---|
| applicationIntent | サーバーに接続するときのアプリケーションのワークロードの種類。 使用できる値は ReadOnly と ReadWrite です。 |
いいえ |
| connectTimeout | サーバーへの接続が確立されるまでに待機する時間 (秒) です。この時間が経過すると接続要求を終了し、エラーを生成します。 | いいえ |
| connectRetryCount | アイドル状態の接続エラーを特定した後に試行された再接続の数。 値は 0 から 255 までの整数である必要があります。 | いいえ |
| connectRetryInterval | アイドル状態の接続エラーを特定した後の、再接続試行の時間間隔 (秒)。 SQL Server のバージョンをアップグレードする値は 1 から 60 までの整数である必要があります。 | いいえ |
| loadBalanceTimeout | 接続が破棄される前に接続が接続プールに存在する最小時間 (秒)。 | いいえ |
| commandTimeout | コマンド実行の試行を終了してエラーを生成するまでの既定の待機時間 (秒)。 | いいえ |
| integratedSecurity | 使用できる値は true または false です。
false を指定する場合は、接続に userName とパスワードが指定されるかどうかを示します。
true を指定するときに、現在のWindows アカウントの資格情報を認証に使用するかどうかを示します。 |
いいえ |
| failoverPartner | プライマリ サーバーがダウンしている場合に接続するパートナー サーバーの名前またはアドレス。 | いいえ |
| maxPoolSize | 特定の接続について、接続プールで許可される接続の最大数。 | いいえ |
| minPoolSize | 特定の接続について、接続プールで許可される接続の最小数。 | いいえ |
| multipleActiveResultSets | 使用できる値は true または false です。
true を指定すると、アプリケーションは複数のアクティブな結果セット (MARS) を維持できます。
false を指定すると、アプリケーションは、その接続で他のバッチを実行する前に、1 つのバッチからすべての結果セットを処理または取り消す必要があります。 |
いいえ |
| multiSubnetFailover | 使用できる値は true または false です。 アプリケーションが異なるサブネット上の AlwaysOn 可用性グループ (AG) に接続する場合、このプロパティを true に設定すると、現在アクティブなサーバーの検出と接続が速くなります。 |
いいえ |
| packetSize | サーバーのインスタンスとの通信に使用されるネットワーク パケットのサイズ (バイト)。 | いいえ |
| pooling | 使用できる値は true または false です。
true を指定すると、接続がプールされます。
false を指定すると、接続が要求されるたびに接続が明示的に開かれます。 |
いいえ |
SQL 認証
SQL 認証を使用するには、前のセクションで説明した汎用プロパティに加えて、次のプロパティを指定します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| userName | サーバーへの接続に使用されるユーザー名。 | はい |
| パスワード | 該当するユーザー名のパスワード。 安全に保存するには、このフィールドを SecureString としてマークします。 または、Azure Key Vaultに格納されているシークレットを |
はい |
例: SQL 認証の使用
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: Azure Key Vault 内のパスワード
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: Always Encrypted の使用
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
サービス プリンシパルの認証
前のセクションで説明した汎用的なプロパティに加えて、サービス プリンシパルの認証を使用するには、次のプロパティを指定します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| servicePrincipalId | アプリケーションのクライアント ID を取得します。 | はい |
| servicePrincipalCredential | サービス プリンシパルの資格情報。 アプリケーションのキーを取得します。 このフィールドを SecureString としてマークして安全に格納するか、 Azure Key Vault に格納されているシークレットを参照します。 | はい |
| テナント | ドメイン名やテナント ID など、アプリケーションが存在するテナントの情報を指定します。 Azure ポータルの右上隅にマウス ポインターを置いて取得します。 | はい |
| azureCloudType | サービス プリンシパル認証の場合は、Microsoft Entra アプリケーションAzure登録するクラウド環境の種類を指定します。 指定できる値は、AzurePublic、AzureChina、AzureUsGovernment、および AzureGermany です。 既定では、データ ファクトリまたは Synapse パイプラインのクラウド環境が使用されます。 |
いいえ |
以下の手順に従う必要もあります。
Azure ポータルからMicrosoft Entra アプリケーションを作成します。 アプリケーション名と、リンクされたサービスを定義する次の値を記録しておきます。
- アプリケーション ID
- アプリケーション キー
- テナント ID
まだ行っていない場合は、Azure ポータルでサーバーのMicrosoft Entra の管理者を設定します。 Microsoft Entra管理者は、Microsoft Entra ユーザーまたはMicrosoft Entra グループである必要がありますが、サービス プリンシパルにすることはできません。 この手順は、次の手順でMicrosoft Entra ID を使用して、サービス プリンシパルの包含データベース ユーザーを作成できるように行われます。
サービス プリンシパルの包含データベース ユーザーを作成します。 少なくとも ALTER ANY USER 権限を持つMicrosoft Entra ID を使用して、SQL Server Management Studioなどのツールを使用して、データのコピー元またはコピー先のデータベースに接続します。 次の T-SQL を実行します。
CREATE USER [your application name] FROM EXTERNAL PROVIDER;SQL ユーザーや他のユーザーに対する通常の方法で、サービス プリンシパルに必要なアクセス許可を付与します。 次のコードを実行します。 詳細については、こちらのドキュメントを参照してください。
ALTER ROLE [role name] ADD MEMBER [your application name];Azure Data Factoryワークスペースまたは Synapse ワークスペースでAzure SQL Databaseリンクされたサービスを構成します。
サービス プリンシパル認証を使うリンクされたサービスの例
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"hostNameInCertificate": "<host name>",
"authenticationType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
システム割り当てマネージド ID 認証
データ ファクトリまたは Synapse ワークスペースは、Azure内の他のリソースに対する認証時にサービスを表すAzure リソース の
システム割り当てマネージド ID 認証を使用するには、前のセクションで説明した汎用プロパティを指定し、次の手順に従います。
まだ行っていない場合は、Azure ポータルでサーバーのMicrosoft Entra の管理者を設定します。 Microsoft Entra管理者は、Microsoft EntraユーザーまたはMicrosoft Entra グループにすることができます。 マネージド ID を持つグループに管理者ロールを付与する場合は、ステップ 3 と 4 をスキップします。 管理者はデータベースに対してフル アクセス権を持っています。
マネージド ID の包含データベース ユーザーを作成します。 少なくとも ALTER ANY USER 権限を持つMicrosoft Entra ID を使用して、SQL Server Management Studioなどのツールを使用して、データのコピー元またはコピー先のデータベースに接続します。 次の T-SQL を実行します。
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;通常の SQL ユーザーなどと同様に、マネージド ID に必要なアクセス許可を付与します。 次のコードを実行します。 詳細については、こちらのドキュメントを参照してください。
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Azure SQL Databaseリンクされたサービスを構成します。
例
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
ユーザー割り当てマネージド ID 認証
データ ファクトリまたは Synapse ワークスペースは、Azure内の他のリソースに対する認証時にサービスを表すユーザー割り当てマネージド ID に関連付けることができます。 このマネージド ID は、Azure SQL Database認証に使用できます。 指定されたファクトリまたは Synapse ワークスペースでは、この ID を使用してデータベースにアクセスし、データベースとの間でデータをコピーできます。
前のセクションで説明した汎用的なプロパティに加えて、ユーザー割り当てマネージド ID 認証を使用するには、次のプロパティを指定します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 認証情報 | ユーザー割り当てマネージド ID を資格情報オブジェクトとして指定します。 | はい |
以下の手順に従う必要もあります。
まだ行っていない場合は、Azure ポータルでサーバーのMicrosoft Entra の管理者を設定します。 Microsoft Entra管理者は、Microsoft EntraユーザーまたはMicrosoft Entra グループにすることができます。 ユーザー割り当てマネージド ID を持つグループに管理者ロールを付与する場合は、ステップ 3 をスキップします。 管理者はデータベースに対してフル アクセス権を持っています。
ユーザー割り当てマネージド ID の包含データベース ユーザーを作成します。 少なくとも ALTER ANY USER 権限を持つMicrosoft Entra ID を使用して、SQL Server Management Studioなどのツールを使用して、データのコピー元またはコピー先のデータベースに接続します。 次の T-SQL を実行します。
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;1 つ以上のユーザー割り当てマネージド ID を作成し、通常の SQL ユーザーなどと同様に、ユーザー割り当てマネージド ID に必要なアクセス許可を付与します。 次のコードを実行します。 詳細については、こちらのドキュメントを参照してください。
ALTER ROLE [role name] ADD MEMBER [your_resource_name];1 つ以上のユーザー割り当てマネージド ID をデータ ファクトリに割り当てて、ユーザー割り当てマネージド ID ごとに資格情報を作成します。
Azure SQL Databaseリンクされたサービスを構成します。
例
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
レガシ バージョン
これらのジェネリック プロパティは、Legacy バージョンを適用するときにAzure SQL Databaseリンクされたサービスでサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティを AzureSqlDatabase に設定する必要があります。 | はい |
| connectionString |
connectionString プロパティのAzure SQL Database インスタンスに接続するために必要な情報を指定します。 パスワードまたはサービス プリンシパル キーをAzure Key Vaultに配置することもできます。 SQL 認証の場合は、connection stringから password 構成をプルします。 詳細については、「Store credentials in Azure Key Vault」を参照してください。 |
はい |
| alwaysEncryptedSettings | マネージド ID またはサービス プリンシパルを使用して、SQL サーバーに格納されている機密データを保護する Always Encrypted を有効にするために必要な alwaysencryptedsettings 情報を指定します。 詳しくは、「Always Encrypted の使用」セクションをご覧ください。 指定されていない場合、既定の always encrypted 設定は無効になります。 | いいえ |
| connectVia | この統合ランタイムは、データ ストアに接続するために使用されます。 データ ストアがプライベート ネットワークにある場合は、Azure統合ランタイムまたはセルフホステッド統合ランタイムを使用できます。 指定しない場合は、既定のAzure統合ランタイムが使用されます。 | いいえ |
さまざまな認証の種類に対する固有のプロパティと前提条件については、それぞれ以降のセクションをご覧ください。
- レガシ バージョンの SQL 認証
- レガシ バージョンのサービス プリンシパル認証
- レガシ バージョンのシステム割り当てマネージド ID 認証
- レガシ バージョンのユーザー割り当てマネージド ID 認証
レガシ バージョンの SQL 認証
SQL 認証を使用するには、前のセクションで説明した汎用プロパティを指定します。
レガシ バージョンのサービス プリンシパル認証
前のセクションで説明した汎用的なプロパティに加えて、サービス プリンシパルの認証を使用するには、次のプロパティを指定します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| servicePrincipalId | アプリケーションのクライアント ID を取得します。 | はい |
| servicePrincipalKey | アプリケーションのキーを取得します。 このフィールドを SecureString としてマークして安全に格納するかAzure Key Vaultに格納されているシークレットを参照します。 | はい |
| テナント | ドメイン名やテナント ID など、アプリケーションが存在するテナントの情報を指定します。 Azure ポータルの右上隅にマウス ポインターを置いて取得します。 | はい |
| azureCloudType | サービス プリンシパル認証の場合は、Microsoft Entra アプリケーションAzure登録するクラウド環境の種類を指定します。 指定できる値は、AzurePublic、AzureChina、AzureUsGovernment、および AzureGermany です。 既定では、データ ファクトリまたは Synapse パイプラインのクラウド環境が使用されます。 |
いいえ |
また、サービス プリンシパル認証の手順に従って、対応するアクセス許可を付与する必要もあります。
レガシ バージョンのシステム割り当てマネージド ID 認証
システム割り当てマネージド ID 認証を使用するには、「システム割り当てマネージド ID 認証」の推奨バージョンと同じ手順に従います。
レガシ バージョンのユーザー割り当てマネージド ID 認証
ユーザー割り当てマネージド ID 認証を使用するには、「ユーザー割り当てマネージド ID 認証」の推奨バージョンと同じ手順に従います。
データセットのプロパティ
データセットの定義に使用できるセクションとプロパティの詳細な一覧については、データセットに関するページを参照してください。
Azure SQL Database のデータセットでサポートされているプロパティは次のとおりです。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | データセットの type プロパティは、AzureSqlTable に設定する必要があります。 | はい |
| スキーマ | スキーマの名前。 | ソースの場合はいいえ、シンクの場合ははい |
| テーブル | テーブル/ビューの名前。 | ソースの場合はいいえ、シンクの場合ははい |
| tableName | スキーマがあるテーブル/ビューの名前。 このプロパティは下位互換性のためにサポートされています。 新しいワークロードでは、schema と table を使用します。 |
ソースの場合はいいえ、シンクの場合ははい |
データセットのプロパティの例
{
"name": "AzureSQLDbDataset",
"properties":
{
"type": "AzureSqlTable",
"linkedServiceName": {
"referenceName": "<Azure SQL Database linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Copy activity のプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関するページを参照してください。 このセクションでは、Azure SQL Databaseソースとシンクでサポートされるプロパティの一覧を示します。
Azure SQL Databaseをソースとして使用する
ヒント
データパーティションを使用して Azure SQL Database からデータを効率的に読み込むには、SQL データベースからの並列コピーをご覧ください。
Azure SQL Databaseからデータをコピーするには、コピー アクティビティ source セクションで次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | コピー アクティビティの source の type プロパティは AzureSqlSource に設定する必要があります。 "SqlSource" タイプは、現在も下位互換性のためにサポートされています。 | はい |
| sqlReaderQuery | このプロパティは、カスタム SQL クエリを使用してデータを読み取ります。 たとえば select * from MyTable です。 |
いいえ |
| sqlReaderStoredProcedureName | ソース テーブルからデータを読み取るストアド プロシージャの名前。 最後の SQL ステートメントはストアド プロシージャの SELECT ステートメントにする必要があります。 | いいえ |
| storedProcedureParameters | ストアド プロシージャのパラメーター。 使用可能な値は、名前または値のペアです。 パラメーターの名前とその大文字と小文字は、ストアド プロシージャのパラメーターの名前とその大文字小文字と一致する必要があります。 |
いいえ |
| isolationLevel | SQL ソースのトランザクション ロック動作を指定します。 使用できる値は、ReadCommitted、ReadUncommitted、RepeatableRead、Serializable、Snapshot です。 指定しない場合、データベースの既定の分離レベルが使用されます。 詳細についてはこちらのドキュメントをご覧ください。 | いいえ |
| partitionOptions | Azure SQL Databaseからデータを読み込むのに使用するデータパーティション分割オプションを指定します。 使用できる値は、None (既定値)、PhysicalPartitionsOfTable、DynamicRange です。 パーティション オプションが有効になっている (つまり、 None ではない) 場合、Azure SQL Databaseから同時にデータを読み込む並列処理の程度は、コピー アクティビティの parallelCopies 設定によって制御されます。 |
いいえ |
| partitionSettings | データ パーティション分割の設定のグループを指定します。 パーティション オプションが None でない場合に適用されます。 |
いいえ |
partitionSettings の下: |
||
| partitionColumnName | 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (int、smallint、bigint、date、smalldatetime、datetime、datetime2、または datetimeoffset) のソース列の名前を指定します。 指定しない場合、テーブルのインデックスまたは主キーが自動検出され、パーティション列として使用されます。パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?DfDynamicRangePartitionCondition をフックします。 例については、「SQL データベースからの並列コピー」セクションを参照してください。 |
いいえ |
| partitionUpperBound | パーティション範囲の分割のための、パーティション列の最大値。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 パーティション オプションが DynamicRange である場合に適用されます。 例については、「SQL データベースからの並列コピー」セクションを参照してください。 |
いいえ |
| partitionLowerBound | パーティション範囲の分割のための、パーティション列の最小値。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 パーティション オプションが DynamicRange である場合に適用されます。 例については、「SQL データベースからの並列コピー」セクションを参照してください。 |
いいえ |
以下の点に注意してください。
- sqlReaderQuery が AzureSqlSource に指定されている場合、コピー アクティビティはAzure SQL Database ソースに対してこのクエリを実行してデータを取得します。 sqlReaderStoredProcedureName と storedProcedureParameters を指定して、ストアド プロシージャを指定することもできます (ストアド プロシージャでパラメーターを使用する場合)。
- ソースのストアド プロシージャを使用してデータを取得する場合、異なるパラメーター値が渡されたときにストアド プロシージャが別のスキーマを返すように設計されていると、UI からスキーマをインポートするとき、または自動テーブル作成を使用して SQL データベースにデータをコピーするときに、エラーが発生したり、予期しない結果が表示されます。
SQL クエリの例
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
ストアド プロシージャの例
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
ストアド プロシージャの定義
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
シンクとしてAzure SQL Databaseを使用する
ヒント
サポートされている書き込み動作、構成、ベスト プラクティスの詳細については、
Azure SQL Databaseにデータをコピーするには、コピー アクティビティ sink セクションで次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | コピー アクティビティの sink の type プロパティは AzureSqlSink に設定する必要があります。 "SqlSink" タイプは、現在も下位互換性のためにサポートされています。 | はい |
| preCopyScript | Azure SQL Databaseにデータを書き込む前に実行するコピー アクティビティの SQL クエリを指定します。 これは、コピー実行ごとに 1 回だけ呼び出されます。 前に読み込まれたデータをクリーンアップするには、このプロパティを使います。 | いいえ |
| tableOption | シンク テーブルが存在しない場合に、ソースのスキーマに基づいて、シンク テーブルを自動的に作成するかどうかを指定します。 シンクでストアド プロシージャが指定されている場合、テーブルの自動作成はサポートされません。 使用できる値は none (既定値)、autoCreate です。 |
いいえ |
| sqlWriterStoredProcedureName | ターゲット テーブルにソース データを適用する方法を定義しているストアド プロシージャの名前です。 このストアド プロシージャはバッチごとに呼び出されます。 1 回だけ実行され、ソース データとは関係がない操作 (削除/切り詰めなど) の場合は、 preCopyScript プロパティを使用します。例については、「SQL シンクからのストアド プロシージャの呼び出し」を参照してください。 |
いいえ |
| storedProcedureTableTypeParameterName | ストアド プロシージャで指定されたテーブル型のパラメーター名。 | いいえ |
| sqlWriterTableType | ストアド プロシージャで使用するテーブル型の名前。 コピー アクティビティでは、このテーブル型の一時テーブルでデータを移動できます。 その後、ストアド プロシージャのコードにより、コピーされたデータを既存のデータと結合できます。 | いいえ |
| storedProcedureParameters | ストアド プロシージャのパラメーター。 使用可能な値は、名前と値のペアです。 パラメーターの名前とその大文字と小文字は、ストアド プロシージャのパラメーターの名前とその大文字小文字と一致する必要があります。 |
いいえ |
| writeBatchSize | SQL テーブルに挿入する "バッチあたりの" 行数。 使用可能な値は integer (行数) です。 既定では行のサイズに基づいて、サービスにより適切なバッチ サイズが動的に決定されます。 |
いいえ |
| writeBatchTimeout | タイムアウトする前に挿入、アップサート、およびストアド プロシージャ操作が完了するまでの待機時間です。 使用可能な値は期間に対する値です。 たとえば "00:30:00" (30 分) を指定できます。 値を指定しない場合、タイムアウトの既定値は "00:30:00" です。 |
いいえ |
| disableMetricsCollection | このサービスでは、コピー パフォーマンスの最適化と推奨事項のための Azure SQL Database DTU などのメトリックが収集されます。これにより、マスター DB へのアクセスが追加されます。 この動作に不安がある場合は、true を指定してオフにします。 |
いいえ (既定値は false) |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されるコンカレント接続数の上限。 コンカレント接続数を制限する場合にのみ、値を指定します。 | いいえ |
| WriteBehavior | Azure SQL Databaseにデータを読み込むためのコピー アクティビティの書き込み動作を指定します。 使用できる値は、Insert と Upsert です。 既定では、サービスは Insert を使用してデータを読み込みます。 |
いいえ |
| upsertSettings | 書き込み動作の設定のグループを指定します。 WriteBehavior オプションが Upsert である場合に適用します。 |
いいえ |
upsertSettings の下: |
||
| useTempDB | アップサートの中間テーブルとしてグローバル一時テーブルと物理テーブルのいずれを使用するかを指定します。 既定では、サービスはグローバル一時テーブルを中間テーブルとして使用します。 値は true です。 |
いいえ |
| interimSchemaName | 物理テーブルを使う場合は、中間テーブルを作成するために中間スキーマを指定します。 注: ユーザーは、テーブルの作成と削除を行うアクセス許可を持っている必要があります。 既定では、中間テーブルはシンク テーブルと同じスキーマを共有します。 useTempDB オプションが False である場合に適用します。 |
いいえ |
| キー | 行を一意に識別するための列名を指定します。 1 つのキーまたは一連のキーのいずれかを使用できます。 指定しない場合は、主キーが使用されます。 | いいえ |
例 1: データを追加する
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
例 2: コピー中にストアド プロシージャを呼び出す
詳しくは、「SQL シンクからのストアド プロシージャの呼び出し」をご覧ください。
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
例 3: データをアップサートする
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
SQL データベースからの並列コピー
コピー アクティビティの Azure SQL Database コネクタでは、データを並列にコピーするための組み込みのデータ パーティション分割が提供されます。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
パーティション分割コピーを有効にすると、コピー アクティビティは、パーティションごとにデータを読み込むAzure SQL Database ソースに対して並列クエリを実行します。 並列度は、コピー アクティビティの parallelCopies 設定によって制御されます。 たとえば、parallelCopies を 4 に設定すると、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成および実行され、各クエリはAzure SQL Databaseからデータの一部を取得します。
特にAzure SQL Databaseから大量のデータを読み込む場合は、データパーティション分割を使用して並列コピーを有効にすることをお勧めします。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 |
パーティション オプション: テーブルの物理パーティション。 実行中に、サービスによって物理パーティションが自動的に検出され、パーティションごとにデータがコピーされます。 テーブルに物理パーティションがあるかどうかを確認するには、こちらのクエリを参照してください。 |
| 物理パーティションがなく、データ パーティション分割用の整数または日時の列がある大きなテーブル全体から読み込む。 |
パーティション オプション: ダイナミック レンジ パーティション。 パーティション列 (省略可能): データのパーティション分割に使う列を指定します。 指定されていない場合は、インデックスまたは主キー列が使用されます。 パーティションの上限とパーティションの下限 (省略可能): パーティション ストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、テーブル内のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 |
| 物理パーティションがなく、データ パーティション分割用の整数列または日付/日時列がある大量のデータを、カスタム クエリを使用して読み込む。 |
パーティション オプション: ダイナミック レンジ パーティション。 クエリ: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>パーティション列: データのパーティション分割に使う列を指定します。 パーティションの上限とパーティションの下限 (省略可能): パーティション ストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、クエリ結果のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 さまざまなシナリオのサンプル クエリを次に示します。 1. テーブル全体に対してクエリを実行する: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. 列の選択と追加の where 句フィルターが含まれるテーブルからのクエリ: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. サブクエリを使用したクエリ: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. サブクエリにパーティションがあるクエリ: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
パーティション オプションを使用してデータを読み込む場合のベスト プラクティス:
- データ スキューを回避するため、パーティション列 (主キーや一意キーなど) には特徴のある列を選択します。
- テーブルに組み込みパーティションがある場合は、パフォーマンスを向上させるためにパーティション オプションとして "テーブルの物理パーティション" を使用します。
- Azure Integration Runtimeを使用してデータをコピーする場合は、より大きな "Data Integration Units (DIU)" (>4) を設定して、より多くのコンピューティング リソースを利用できます。 そこで、該当するシナリオを確認してください。
- パーティション数は、"コピーの並列処理の次数" によって制御されます。この数値を大きくしすぎるとパフォーマンスが低下するため、この数値は、(DIU またはセルフホステッド IR ノードの数) x (2 から 4) に設定することをお勧めします。
例: 複数の物理パーティションがある大きなテーブル全体から読み込む
"source": {
"type": "AzureSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
例: 動的範囲パーティションを使用してクエリを実行する
"source": {
"type": "AzureSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
物理パーティションを確認するためのサンプル クエリ
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
テーブルに物理パーティションがある場合、次のように、"HasPartition" は "yes" と表示されます。

Azure SQL Databaseにデータを読み込むためのベスト プラクティス
Azure SQL Databaseにデータをコピーするときに、異なる書き込み動作が必要になる場合があります。
- 追加: ソース データには新しいレコードのみが含まれている。
- アップサート: ソース データには挿入と更新の両方が含まれている。
- 上書き: 毎回ディメンション テーブル全体を再度読み込みたい。
- カスタム ロジックを使った書き込み: 宛先テーブルへの最終挿入の前に追加の処理が必要である。
サービスで構成する方法とベスト プラクティスについては、対応するセクションを参照してください。
データを追加する
データの追加は、このAzure SQL Database シンク コネクタの既定の動作です。 サービスでは、テーブルに効率的に書き込むために一括挿入が実行されます。 コピー アクティビティで、それに応じてソースとシンクを構成できます。
データをアップサートする
Copy activityは、データベース一時テーブルへのデータのネイティブ読み込みをサポートし、キーが存在する場合はシンク テーブル内のデータを更新し、それ以外の場合は新しいデータを挿入できるようになりました。 コピー アクティビティでのアップサート設定の詳細については、シンクとしての Azure SQL Databaseに関するページを参照してください。
テーブル全体を上書きする
コピー アクティビティ シンクで preCopyScript プロパティを構成できます。 この場合、実行される Copy アクティビティごとに、サービスで最初にスクリプトが実行されます。 次に、コピーが実行されてデータが挿入されます。 たとえば、テーブル全体を最新のデータで上書きするには、ソースから新しいデータを一括で読み込む前に、すべてのレコードを最初に削除するスクリプトを指定します。
カスタム ロジックでデータを書き込む
カスタム ロジックでデータを書き込む手順は、「データをアップサートする」セクションで説明されている手順に似ています。 コピー先テーブルへのソース データの最終的な挿入前に追加の処理を適用する必要がある場合は、ステージング テーブルに読み込み、ストアド プロシージャ アクティビティを呼び出すか、コピー アクティビティ シンクでストアド プロシージャを呼び出してデータを適用するか、Mapping Data Flowを使用できます。
SQL シンクからのストアド プロシージャの呼び出し
Azure SQL Databaseにデータをコピーする場合は、ソース テーブルの各バッチに追加のパラメーターを指定して、ユーザー指定のストアド プロシージャを構成して呼び出すこともできます。 ストアド プロシージャ機能は テーブル値パラメーターを利用しています。
組み込みのコピー メカニズムでは目的を達成できない場合は、ストアド プロシージャを使用できます。 1 つの例は、宛先テーブルへのソース データの最終挿入の前に追加の処理を適用する場合です。 その他の処理の例をいくつか挙げると、列のマージ、追加の値の検索、複数のテーブルへの挿入があります。
次の例は、ストアド プロシージャを使用して、Azure SQL Databaseのテーブルにアップサートを実行する方法を示しています。 入力データと、シンクの Marketing テーブルのそれぞれに 3 つの列 (ProfileID、State、Category) があるものとします。 ProfileID 列に基づいてアップサートを行い、"ProductA" という特定のカテゴリに対してのみ適用します。
データベースで、sqlWriterTableType と同じ名前のテーブル型を定義します。 テーブル型のスキーマは、入力データから返されるスキーマと同じです。
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )データベース内で、sqlWriterStoredProcedureName と同じ名前のストアド プロシージャを定義します。 これによって指定したソースの入力データが処理され、出力テーブルにマージされます。 ストアド プロシージャ内のテーブル型のパラメーター名は、データセットで定義されている tableName と同じです。
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDAzure Data Factoryまたは Synapse パイプラインで、コピー アクティビティの SQL シンク セクションを次のように定義します。
"sink": { "type": "AzureSqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
ストアド プロシージャを使用してAzure SQL Databaseにデータを書き込む場合、シンクはソース データをミニ バッチに分割し、挿入を実行するため、ストアド プロシージャ内の追加のクエリを複数回実行できます。 Azure SQL Databaseにデータを書き込む前に実行するコピー アクティビティのクエリがある場合は、ストアド プロシージャに追加することはお勧めしません。Pre-copy script ボックスに追加します。
Mapping Data Flow のプロパティ
マッピング データ フローでデータを変換する場合は、Azure SQL Databaseからテーブルの読み取りと書き込みを行うことができます。 詳細については、マッピング データ フローのソース変換とシンク変換に関する記事をご覧ください。
ソース変換
Azure SQL Databaseに固有の設定は、ソース変換の Source Options タブで使用できます。
[入力](Input): テーブルにあるソースを指す (Select * from <table-name> に相当) かカスタム SQL クエリを入力するかを選択します。
クエリ: input フィールドで [クエリ] を選択した場合は、ソースに対する SQL クエリを入力します。 この設定により、データセットで選択したすべてのテーブルがオーバーライドされます。 ここでは Order By 句はサポートされていませんが、完全な SELECT FROM ステートメントを設定することができます。 ユーザー定義のテーブル関数を使用することもできます。 select * from udfGetData() は、テーブルを返す SQL の UDF です。 このクエリでは、お使いのデータ フローで使用できるソース テーブルが生成されます。 テスト対象またはルックアップ対象の行を減らすうえでも、クエリの使用は有効な手段です。
ヒント
SQL の共通テーブル式 (CTE) は、マッピング データ フローの Query モードではサポートされません。このモードを使用する前提条件は、クエリを SQL クエリの FROM 句で使用することはできるが CTE では使用できないという条件であるためです。 CTE を使用するには、次のクエリを使用してストアド プロシージャを作成する必要があります。
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
次に、マッピング データ フローのソース変換でストアド プロシージャ モードを使用し、@query の例のように with CTE as (select 'test' as a) select * from CTE を設定します。 その後は期待どおりに CTE を使用できます。
[Stored procedure]: ソース データベースから実行されるストアド プロシージャからプロジェクションおよびソース データを生成する場合は、このオプションを選択します。 スキーマ、プロシージャ名、パラメーターを入力することも、[Refresh]\(最新の情報に更新\) をクリックして、スキーマとプロシージャ名の検出をサービスに要求することもできます。 次に、[Import ] をクリックして、すべてのプロシージャ パラメーターをフォーム @paraName を使用してインポートできます。
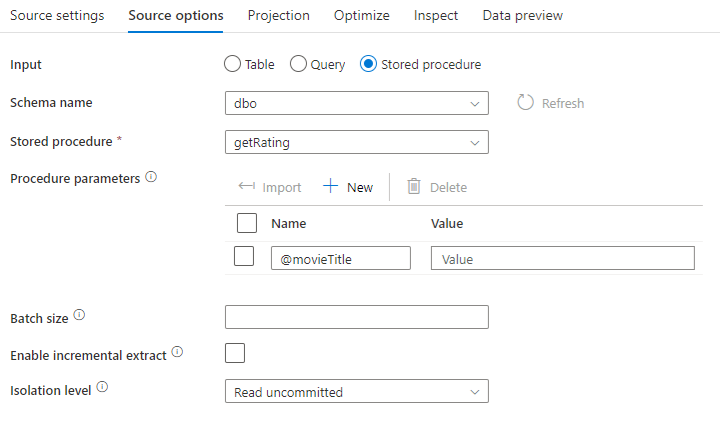
- SQL の例:
Select * from MyTable where customerId > 1000 and customerId < 2000 - パラメーター化された SQL の例:
"select * from {$tablename} where orderyear > {$year}"
バッチ サイズ: 大量データを読み取りにまとめるバッチ サイズを入力します。
分離レベル: マッピング データ フローでの SQL ソースの既定値は [コミットされていないものを読み取り] です。 ここで分離レベルを次のいずれかの値に変更できます。
- コミットされたものを読み取り
- コミットされていないものを読み取り
- 反復可能読み取り
- シリアル化可能
- なし (分離レベルを無視)
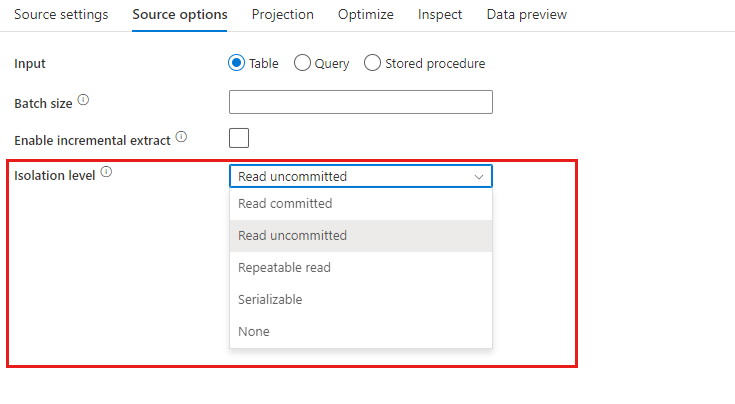
増分抽出を有効にする: このオプションを使用して、パイプラインが最後に実行されてから変更された行のみを処理するように ADF に指示します。 スキーマ ドリフトを使用した増分抽出を有効にするには、ネイティブ変更データ キャプチャが有効になっているテーブルではなく、Incremental/Watermark 列に基づくテーブルを選択します。
増分列: 増分抽出機能を使用する場合は、ソース テーブルのウォーターマークとして使用する日時または数値列を選択する必要があります。
ネイティブ変更データ キャプチャを有効にする (プレビュー): このオプションを使用して、パイプラインが最後に実行されてから SQL 変更データ キャプチャ テクノロジによってキャプチャされた差分データのみを処理するように ADF に指示します。 このオプションを使用すると、行の挿入、更新、削除を含む差分データが自動的に読み込まれ、増分列は必要ありません。 ADF でこのオプションを使用する前に、Azure SQL DB で変更データ キャプチャを有効化する必要があります。 ADF のこのオプションの詳細については、「ネイティブ変更データ キャプチャ」を参照してください。
最初から読み取りを開始する: 増分抽出でこのオプションを設定すると、増分抽出が有効になっているパイプラインの最初の実行時にすべての行を読み取るよう ADF に指示します。
シンク変換
Azure SQL Databaseに固有の設定は、シンク変換の Settings タブで使用できます。
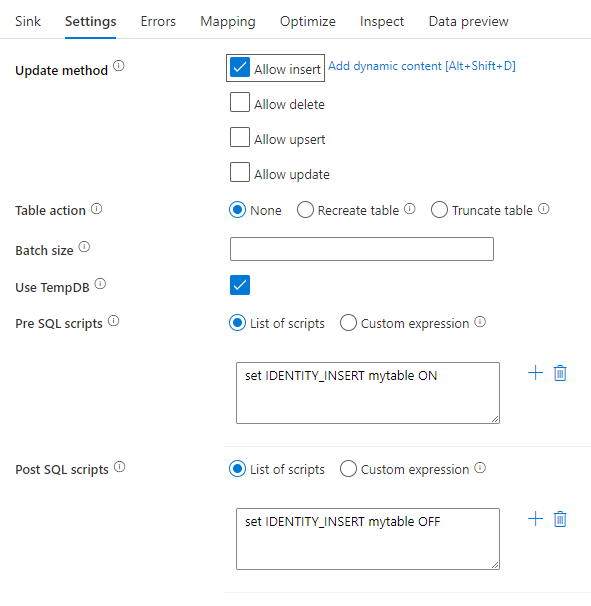
更新方法: 対象となるデータベースに対して許可される操作を指定します。 既定では、挿入のみが許可されます。 行を更新、アップサート、または削除するには、それらのアクションに対して行をタグ付けするために行の変更変換が必要になります。 更新、アップサート、削除の場合、1 つまたは複数のキー列を設定して、変更する行を決定する必要があります。
![[キー列]](media/data-flow/keycolumn.png)
ここでキーとして選択する列の名前は、後続の更新、アップサート、削除でサービスによって使用されます。 そのため、シンク マッピングに存在する列を選択する必要があります。 このキー列に値を書き込まない場合、[Skip writing key columns]\(キー列の書き込みをスキップする\) をクリックします。
ここで使用するキー列をパラメーター化して、ターゲット Azure SQL Database テーブルを更新できます。 複合キーの複数の列がある場合、[カスタム式] をクリックすると、データ フロー式言語を使用して動的コンテンツを追加できます。これには、複合キーの列名を含む文字列の配列を含めることができます。
テーブル アクション: 書き込み前に変換先テーブルのすべての行を再作成するか削除するかを指定します。
- なし: テーブルに対してアクションは実行されません。
- 再作成: テーブルが削除され、再作成されます。 新しいテーブルを動的に作成する場合に必要です。
- 切り詰め: ターゲット テーブルのすべての行が削除されます。
バッチ サイズ: 各バケットに書き込まれる行数を制御します。 バッチ サイズを大きくすると、圧縮とメモリの最適化が向上しますが、データをキャッシュする際にメモリ不足の例外が発生するリスクがあります。
[Use TempDB]\(TempDB を使用\): 既定では、読み込みプロセスの一環としてデータを保存するために、グローバル一時テーブルが使用されます。 [Use TempDB]\(TempDB を使用\) オプションをオフにし、代わりに、このシンクに使用されているデータベース内にあるユーザー データベースに、一時的に保持するテーブルを保存するようサービスに要求することもできます。

事前および事後の SQL スクリプト: データがシンク データベースに書き込まれる前 (前処理) と書き込まれた後 (後処理) に実行される複数行の SQL スクリプトを入力します
ヒント
- 複数のコマンドを含む単一のバッチ スクリプトを複数のバッチに分割することをお勧めします。
- バッチの一部として実行できるのは、単純に更新数を返すデータ操作言語 (DML) ステートメントおよびデータ定義言語 (DDL) ステートメントだけです。 詳細については、「バッチ操作の実行」を参照してください。
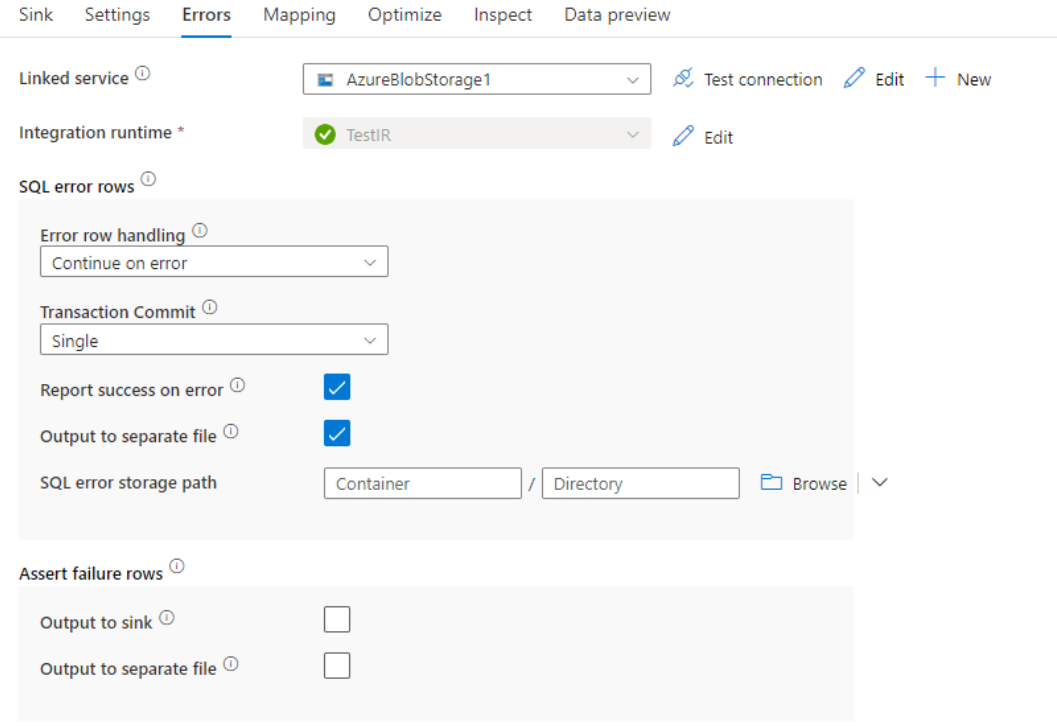
エラー行の処理
Azure SQL DB に書き込む場合、変換先によって設定された制約により、特定のデータ行が失敗する可能性があります。 一般的なエラーには次のようなものがあります。
- テーブル内の文字列データまたはバイナリ データが切り捨てられる
- 列に値 NULL を挿入できない
- INSERT ステートメントが CHECK 制約と競合している
既定では、データ フローの実行は最初に発生したエラーで失敗します。 [エラーのまま続行する] を選択すると、個々の行でエラーが発生した場合でもデータ フローを完了することができます。 サービスには、これらのエラー行を処理するためのさまざまなオプションが用意されています。
トランザクション コミット: データを 1 つのトランザクションまたはバッチのどちらで書き込むかを選択します。 1 つのトランザクションの場合はパフォーマンスが低下しますが、トランザクションが完了するまで書き込みデータは他のユーザーに表示されません。
出力拒否されたデータ: 有効にすると、エラー行をAzure Blob Storageの csv ファイルまたは任意のAzure Data Lake Storage Gen2アカウントに出力できます。 これにより、3 つの列 (INSERT または UPDATE などの SQL 操作、データ フロー エラー コード、および行のエラー メッセージ) を含むエラー行が書き込まれます。
エラー発生時に成功を報告: 有効にすると、エラー行が見つかった場合でもデータ フローは成功としてマークされます。
Azure SQL Databaseのデータ型マッピング
Azure SQL DatabaseからまたはAzure SQL Databaseにデータをコピーする場合、次のマッピングがAzure SQL Databaseのデータ型とAzure Data Factoryの中間データ型の間で使用されます。 同じマッピングが Synapse パイプライン機能によって使用され、Azure Data Factoryを直接実装します。 コピー アクティビティでソースのスキーマとデータ型がシンクにマッピングされるしくみについては、スキーマとデータ型のマッピングに関する記事を参照してください。
| Azure SQL Database データ型 | Data Factory の中間データ型 |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | ブール値 |
| char | String、Char[] |
| date | DateTime |
| Datetime | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM 属性(varbinary(max)) | Byte[] |
| Float | Double |
| イメージ | Byte[] |
| INT | Int32 |
| money | Decimal |
| nchar | String、Char[] |
| ntext | String、Char[] |
| numeric | Decimal |
| nvarchar | String、Char[] |
| real | Single |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| smallint | Int16 |
| smallmoney | Decimal |
| sql_variant | Object |
| SMS 送信 | String、Char[] |
| time | TimeSpan |
| timestamp | Byte[] |
| tinyint | Byte |
| UNIQUEIDENTIFIER | Guid |
| varbinary | Byte[] |
| varchar | String、Char[] |
| xml | String |
Note
Decimal 型の中間型にマップされるデータ型の場合、現在、Copy activity は有効桁数を 28 桁までサポートしています。 28 よりも大きな有効桁数のデータがある場合は、SQL クエリで文字列に変換することを検討してください。
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
GetMetadata アクティビティのプロパティ
プロパティの詳細については、GetMetadata アクティビティに関するページを参照してください。
Always Encrypted の使用
Always Encrypted を使用してデータをAzure SQL Databaseにコピーする場合は、次の手順に従います。
Column マスター キー (CMK)を Azure Key Vault に格納します。 Azure Key Vault を使用した Always Encrypted の構成方法について詳しく知るには
列マスター キー (CMK) が格納されているキー コンテナーへのアクセス権を取得します。 必要なアクセス許可については、こちらの記事を参照してください。
リンク サービスを作成して SQL データベースに接続し、マネージド ID またはサービス プリンシパルを使用して "Always Encrypted" 機能を有効にします。
Note
Azure SQL Database Always Encrypted では、次のシナリオがサポートされます。
- ソース データ ストアまたはシンク データ ストアのいずれかで、キー プロバイダー認証の種類としてマネージド ID またはサービス プリンシパルを使用する。
- ソース データ ストアとシンク データ ストアの両方で、キー プロバイダー認証の種類としてマネージド ID を使用する。
- ソース データ ストアとシンク データ ストアの両方で、キー プロバイダー認証の種類として同じサービス プリンシパルを使用する。
Note
現在、マッピング データ フローでのシンク変換では、Azure SQL Database Always Encrypted はサポートされていません。
ネイティブ変更データ キャプチャ
Azure Data Factoryでは、SQL Server、Azure SQL DB、および Azure SQL MI のネイティブ変更データ キャプチャ機能をサポートできます。 SQL ストアの行の挿入、更新、削除などの変更されたデータは、ADF マッピング データフローによって自動的に検出および抽出できます。 マッピング データフローのコード エクスペリエンスがないため、ユーザーはデータベースを宛先のストアとして追加することで、SQL ストアからのデータ レプリケーション シナリオを簡単に実現できます。 さらに、ユーザーは間にデータ変換ロジックを作成して、SQL ストアから増分 ETL シナリオを実現することもできます。
チェックポイントを ADF が記録して最後の実行から変更データを自動的に取得できるようにするために、パイプラインとアクティビティ名は変更しないようにしてください。 パイプライン名またはアクティビティ名を変更すると、チェックポイントがリセットされます。これにより、次回の実行時に最初から変更を開始したり、変更を取得したりすることができます。 パイプライン名またはアクティビティ名を変更しても、直近の実行の後に変更されたデータを自動的に取得するためにチェックポイントを保持する場合は、データフロー アクティビティで独自のチェックポイント キーを使用して、これを実現してください。
パイプラインをデバッグすると、この機能は同じように動作します。 デバッグ実行中にブラウザーを更新すると、チェックポイントがリセットされることに注意してください。 デバッグ実行のパイプライン結果に問題がなければ、パイプラインの発行とトリガーに進むことができます。 最初に発行されたパイプラインをトリガーした時点では、最初から自動的に再起動されるか、またはその後からの変更が取得されます。
[モニター] セクションでは、常にパイプラインを再実行できます。 この場合、変更されたデータは、選択したパイプライン実行の前のチェックポイントから常にキャプチャされます。
例 1:
マッピング データフロー内のデータベースに参照されるシンク変換を使用して SQL CDC 対応データセットに参照されるソース変換を直接チェーンすると、SQL ソースで行われた変更がターゲット データベースに自動的に適用されるため、データベース間のデータ レプリケーション シナリオを簡単に取得できます。 シンク変換で更新方法を使用して、挿入を許可するか、更新を許可するか、ターゲット データベースで削除を許可するかを選択できます。 マッピング データフローのスクリプトの例を次に示します。
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
例 2:
SQL CDC を使用したデータベース間のデータ レプリケーションではなく ETL シナリオを有効にする場合は、isInsert(1)、isUpdate(1)、isDelete(1) などのマッピング データフローで式を使用して、異なる操作の種類の行を区別できます。 値を持つ 1 つの列を派生する際にデータフローをマッピングするためのスクリプト例の 1 つを次に示します。1 は挿入された行を示し、2 は更新された行を示し、3 はダウンストリーム変換で差分データを処理するために削除された行を示します。
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
既知の制限事項:
- SQL CDC からの net 変更のみが、cdc.fn_cdc_get_net_changes_ 経由で ADF によって読み込まれます。
Azure SQL Database バージョンをアップグレードする
Azure SQL Databaseバージョンをアップグレードするには、リンク サービスの編集ページで、Version の下にある Recommended を選択し、推奨バージョンの リンク サービス プロパティ を参照して、リンク サービスを設定します。
推奨バージョンとレガシ バージョンの違い
次の表は、推奨バージョンとレガシ バージョンを使用したAzure SQL Databaseの違いを示しています。
| 推奨されるバージョン | レガシ バージョン |
|---|---|
encrypt を strict とすることで TLS 1.3 をサポートします。 |
TLS 1.3 はサポートされません。 |
関連コンテンツ
Copy アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、「サポートされるデータ ストアと形式」を参照してください。