Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule wyjaśniono agregację metryk w bazie danych szeregów czasowych, która wspiera metryki platformy Azure Monitor i metryki niestandardowe. Artykuł dotyczy również standardowych metryk usługi Application Insights.
Te informacje w tym artykule są złożone i są udostępniane osobom, które chcą zagłębić się w system metryk. Nie musisz go rozumieć, aby efektywnie korzystać z metryk usługi Azure Monitor.
Omówienie i terminy
Po dodaniu metryki do wykresu eksplorator metryk automatycznie wybiera jego domyślną agregację. Wartość domyślna ma sens w podstawowych scenariuszach, ale możesz użyć różnych agregacji, aby uzyskać więcej szczegółowych informacji na temat metryki. Wyświetlanie różnych agregacji na wykresie wymaga zrozumienia sposobu obsługi ich przez eksploratora metryk.
Najpierw zdefiniujmy kilka terminów:
- Wskaźnik — pojedyncza wartość pomiarowa zebrana dla określonego zasobu.
- Baza danych szeregów czasowych — baza danych zoptymalizowana pod kątem przechowywania i odczytu punktów danych, z których każdy zawiera wartość oraz odpowiadający mu znacznik czasu.
- Okres — ogólny okres czasu.
- Przedział czasu — okres między gromadzeniem dwóch wartości metryki.
- Zakres czasu — okres wyświetlany na wykresie. Typowa wartość domyślna to 24 godziny. Dostępne są tylko określone zakresy.
- Stopień szczegółowości czasu lub ziarna czasu — okres używany do agregowania wartości w celu umożliwienia wyświetlania na wykresie. Dostępne są tylko określone zakresy. Bieżąca minimalna wartość to 1 minuta. Wartość stopnia szczegółowości czasu powinna być mniejsza niż wybrany zakres czasu, aby była przydatna. W przeciwnym razie tylko jedna wartość jest wyświetlana dla całego wykresu.
- Typ agregacji — typ statystyki obliczony na podstawie wielu wartości metryk.
- Agregacja — proces przyjmowania wielu wartości wejściowych, a następnie używania ich do tworzenia pojedynczej wartości wyjściowej za pośrednictwem reguł zdefiniowanych przez typ agregacji. Na przykład biorąc średnią z wielu wartości.
Podsumowanie procesu
Metryki to seria wartości przechowywanych przy użyciu sygnatury czasowej. Na platformie Azure większość metryk jest przechowywana w bazie danych szeregów czasowych metryk platformy Azure. Podczas wykreślenia wykresu wartości wybranych metryk są pobierane z bazy danych, a następnie agregowane oddzielnie na podstawie wybranego stopnia szczegółowości czasu (nazywanego również ziarnem czasu). Możesz wybrać rozmiar stopnia szczegółowości czasu przy użyciu selektora metryk eksploratora. Jeśli nie wybierzesz jawnego wyboru, stopień szczegółowości czasu zostanie automatycznie wybrany na podstawie aktualnie wybranego zakresu czasu. Po wybraniu wartości metryk przechwytywanych w każdym interwale szczegółowości są agregowane i umieszczane na wykresie — jeden punkt danych na interwał.
Typy agregacji
W Eksploratorze metryk jest dostępnych pięć podstawowych typów agregacji. Eksplorator metryk ukrywa agregacje, które są nieistotne i nie może być używane dla danej metryki.
- Sum — suma wszystkich wartości przechwyconych w interwale agregacji. Czasami nazywane agregacją Total (Łączna agregacja).
- Count — liczba pomiarów przechwyconych w interwale agregacji. Funkcja Count nie uwzględnia wartości miary, tylko liczby rekordów.
- Average — średnia wartości metryk przechwyconych w interwale agregacji. W przypadku większości metryk ta wartość to Suma/Liczba.
- Min — najmniejsza wartość przechwycona w interwale agregacji.
- Max — największa wartość przechwycona w interwale agregacji.
Załóżmy na przykład, że wykres przedstawia całkowity ruch wychodzący w sieci dla maszyny wirtualnej z zastosowaniem agregacji SUM w ciągu ostatnich 24 godzin. Zakres czasu i stopień szczegółowości można zmienić z prawej górnej części wykresu, jak pokazano na poniższym zrzucie ekranu.
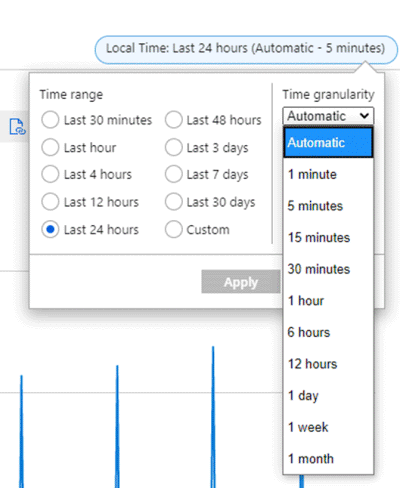
W przypadku stopnia szczegółowości czasu = 30 minut i zakresu czasu = 24 godziny:
- Wykres jest rysowany z 48 punktów danych. To są 24 godziny x 2 punkty danych na godzinę (co 60 min/30 min) z agregacją punktów danych w 1-minutowych interwałach.
- Wykres liniowy łączy 48 kropek w obszarze wykresu.
- Każdy punkt danych reprezentuje sumę wszystkich bajtów sieci wychodzących wysyłanych w każdym z odpowiednich 30-minutowych okresów.

Kliknij obrazy w tej sekcji, aby wyświetlić większe wersje.
Jeśli zmienisz stopień szczegółowości czasu na 15 minut, wykres zostanie narysowany z 96 zagregowanych punktów danych. Oznacza to, 60min/15min = 4 punkty danych na godzinę x 24 godziny.

W przypadku stopnia szczegółowości czasu 5 minut uzyskasz 24 x (60/5) = 288 punktów.
W przypadku stopnia szczegółowości czasu 1 minuty (najmniejszego możliwego na wykresie) uzyskasz 24 x 60/1 = 1440 punktów.

Wykresy wyglądają inaczej dla tych sumacji, jak pokazano na poprzednich zrzutach ekranu. Zwróć uwagę, że ta maszyna wirtualna ma wiele danych wyjściowych w krótkim okresie czasu w porównaniu do pozostałej części przedziału czasu.
Stopień szczegółowości czasu umożliwia dostosowanie współczynnika "sygnał-szum" na wykresie. Wyższe agregacje usuwają szum i wygładzają skoki. Zwróć uwagę na odmiany na wykresie 1-minutowym na dole i jak się wygładzają podczas przejścia do wyższych wartości szczegółowości.
To zachowanie wygładzania jest ważne podczas wysyłania tych danych do innych systemów — na przykład alertów. Zwykle nie chcesz być ostrzegany z powodu krótkich skoków czasu procesora powyżej 90%. Jeśli jednak procesor pozostaje na poziomie 90% przez 5 minut, prawdopodobnie jest to ważne. Jeśli skonfigurujesz regułę alertu dla procesora CPU (lub dowolnej metryki), zwiększenie szczegółowości czasowej może zmniejszyć liczbę otrzymywanych fałszywych alertów.
Ważne jest, aby ustalić, co jest "normalne" dla obciążenia, aby wiedzieć, jaki przedział czasu jest najlepszy. Jest to jedna z zalet alertów dynamicznych, które nie zostały tutaj omówione w innym temacie.
Jak system zbiera metryki
Różne metody zbierania danych zależą od metryki.
Uwaga / Notatka
Poniższe przykłady są uproszczone na potrzeby ilustracji, a rzeczywiste dane metryk zawarte w każdej agregacji mają wpływ na dane dostępne podczas oceny.
Częstotliwość zbierania miar
Istnieją dwa typy okresów kolekcji.
Regularne — metryka jest zbierana w spójnym przedziale czasu, który nie różni się.
Oparte na działaniach — metryka jest zbierana na podstawie tego, kiedy wystąpi transakcja określonego typu. Każda transakcja ma metryczny wpis i sygnaturę czasową. Nie są one zbierane w regularnych odstępach czasu, więc istnieje różna liczba rekordów w danym okresie.
Granularność
Minimalny stopień szczegółowości czasu wynosi 1 minutę, ale podstawowy system może przechwytywać dane szybciej w zależności od metryki. Na przykład procent wykorzystania procesora dla maszyny wirtualnej Azure jest rejestrowany co 15 sekund. Ponieważ błędy HTTP są śledzone jako transakcje, mogą łatwo przekroczyć więcej niż jedną minutę. Inne metryki, takie jak usługa SQL Storage, są przechwytywane w odstępach czasu co 20 minut. Ten wybór należy do indywidualnego dostawcy zasobu i jego rodzaju. Większość stara się zapewnić najmniejszy możliwy interwał czasu.
Wymiary, dzielenie i filtrowanie
Wskaźniki są przechwytywane dla każdego zasobu. Jednak poziom zbierania, przechowywania i tworzenia wykresów metryk może się różnić. Ten poziom jest reprezentowany przez inne metryki dostępne w wymiarach metryk. Każdy indywidualny dostawca zasobów definiuje, jak szczegółowe są zbierane dane. Usługa Azure Monitor definiuje tylko sposób prezentowania i przechowywania takich szczegółów.
Podczas tworzenia wykresu metryki w Eksploratorze metryk możesz "podzielić" wykres według wymiaru. Podzielenie wykresu oznacza, że analizujesz dane źródłowe, aby uzyskać więcej szczegółów i zobaczyć, że te dane zostały zwizualizowane lub przefiltrowane w Eksploratorze metryk.
Na przykład Microsoft.ApiManagement/service ma Location jako wymiar w wielu metrykach.
Pojemność jest jedną z takich metryk. Posiadanie wymiaru Lokalizacja oznacza, że podstawowy system przechowuje rekord metryczny dla pojemności każdej lokalizacji, a nie tylko jeden dla zagregowanej ilości. Następnie możesz pobrać lub podzielić te informacje na wykresie metrycznym.
Patrząc na ogólny czas trwania żądań do bramy, istnieją dwa wymiary: Lokalizacja i Nazwa hosta, ponownie informując o lokalizacji trwania oraz nazwie hosta, z którego pochodzi.
Jedną z bardziej elastycznych metryk, Requests, ma 7 różnych wymiarów.
Zapoznaj się z artykułem Obsługiwane metryki w usłudze Azure Monitor , aby uzyskać szczegółowe informacje na temat każdej metryki i dostępnych wymiarów. Ponadto dokumentacja każdego dostawcy zasobów i typu może zawierać dodatkowe informacje na temat wymiarów i tego, co mierzą.
Możesz użyć dzielenia i filtrowania razem, aby zagłębić się w problem. Poniżej znajduje się przykład grafiki przedstawiającej średni bajt zapisu dysku dla grupy maszyn wirtualnych w grupie zasobów. Mamy zestawienie wszystkich maszyn wirtualnych z tą metryką, ale możemy chcieć dogłębnie zbadać, które odpowiadają za szczyty w pobliżu godziny 6:00. Czy są to same maszyny? Ile maszyn jest zaangażowanych?

Kliknij obrazy w tej sekcji, aby wyświetlić większe wersje.
Po zastosowaniu podziału możemy zobaczyć bazowe dane, ale jest to trochę bałagan. Okazuje się, że na powyższym wykresie jest agregowanych 20 maszyn wirtualnych. W tym przypadku, użyliśmy myszy, aby najechać kursorem na duży szczyt o 6:00, który informuje nas, że CH-DCVM11 jest przyczyną. Trudno jednak zobaczyć resztę danych skojarzonych z tą maszyną wirtualną z powodu innych maszyn wirtualnych zaśmiecających wykres.

Użycie filtrowania umożliwia oczyszczenie wykresu, aby zobaczyć, co naprawdę się dzieje. Możesz sprawdzić lub usunąć zaznaczenie maszyn wirtualnych, które chcesz zobaczyć. Zwróć uwagę na kropkowane linie. Te opisano w późniejszej sekcji.

Aby uzyskać więcej informacji na temat pokazywania podzielonych danych wymiarów na wykresie eksploratora metryk, zobacz Używanie filtrów wymiarów i dzielenie.
Wartości NULL i zero
Gdy system oczekuje danych metryk z zasobu, ale nie otrzyma go, rejestruje wartość NULL. Wartość NULL różni się od wartości zerowej, która staje się ważna podczas obliczania agregacji i tworzenia wykresów. Wartości NULL nie są liczone jako prawidłowe pomiary.
Wartości NULL są wyświetlane inaczej na różnych wykresach. Wykresy punktowe pomijają umieszczenie kropki na wykresie. Wykresy słupkowe pomijają wyświetlanie słupka. Na wykresach liniowych wartość NULL może być wyświetlana jako linie kropkowane lub kreskowane, takie jak pokazane na zrzucie ekranu w poprzedniej sekcji. Podczas obliczania średnich, które obejmują NULLs, istnieje mniej punktów danych, z których należy wziąć średnią. Takie zachowanie może czasami spowodować nieoczekiwany spadek wartości na wykresie, choć mniej niż wtedy, gdy wartość została przekonwertowana na zero i użyta jako prawidłowy punkt danych.
Metryki niestandardowe zawsze używają wartości NULL, gdy żadne dane nie są odbierane. W przypadku metryk platformy każdy dostawca zasobów decyduje, czy używać zer, czy NULLs w oparciu o to, co ma największe znaczenie dla danej metryki.
Alerty usługi Azure Monitor wykorzystują wartości, które dostawca zasobów zapisuje w bazie danych metryk, dlatego ważne jest, aby na początku zapoznać się z danymi, by zrozumieć, jak dostawca zasobów obsługuje wartości NULL.
Jak działa agregacja
Wykresy metryk w poprzednim systemie pokazują różne typy zagregowanych danych. System wstępnie przetwarza dane, aby żądane wykresy mogły być wyświetlane szybciej bez wielu powtarzających się obliczeń.
W tym przykładzie:
- Zbieramy fikcyjną metrykę transakcyjną o nazwie Błędy HTTP
- Serwer jest wymiarem metryki błędów HTTP.
- Mamy 3 serwery — serwer A, B i C.
Aby uprościć wyjaśnienie, zaczynamy od typu agregacji SUM.
Agregacja w czasie poniżej minuty do 1 minuty
Pierwsze nieprzetworzone dane metryk są zbierane i przechowywane w bazie danych metryk usługi Azure Monitor. W takim przypadku każdy serwer ma rekordy transakcji przechowywane ze znacznikiem czasu, ponieważ serwer jest wymiarem. Biorąc pod uwagę, że najmniejszy okres czasu, który można wyświetlić dla klienta, wynosi 1 minutę, te znaczniki czasu są najpierw agregowane w minutowe wartości metryczne dla każdego serwera. Proces agregacji serwera B jest pokazany na poniższej ilustracji. Serwery A i C są wykonywane w taki sam sposób i mają różne dane.
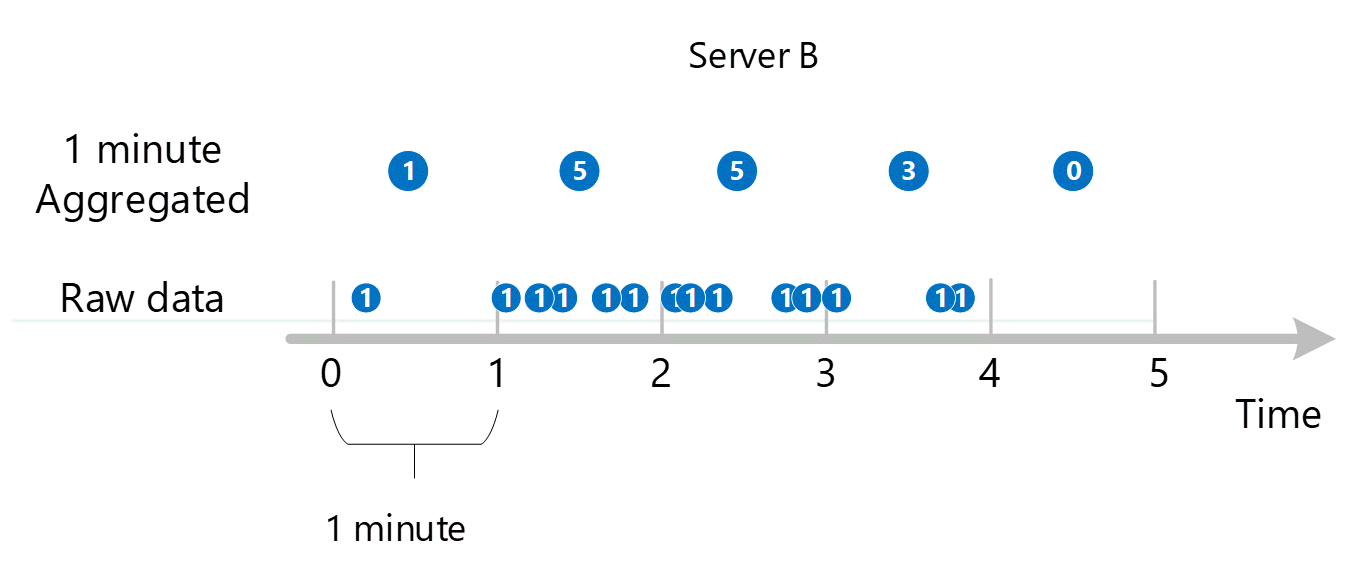
Wynikowe 1-minutowe zagregowane wartości są przechowywane jako nowe wpisy w bazie danych metryk, dzięki czemu można je zebrać na potrzeby późniejszych obliczeń.
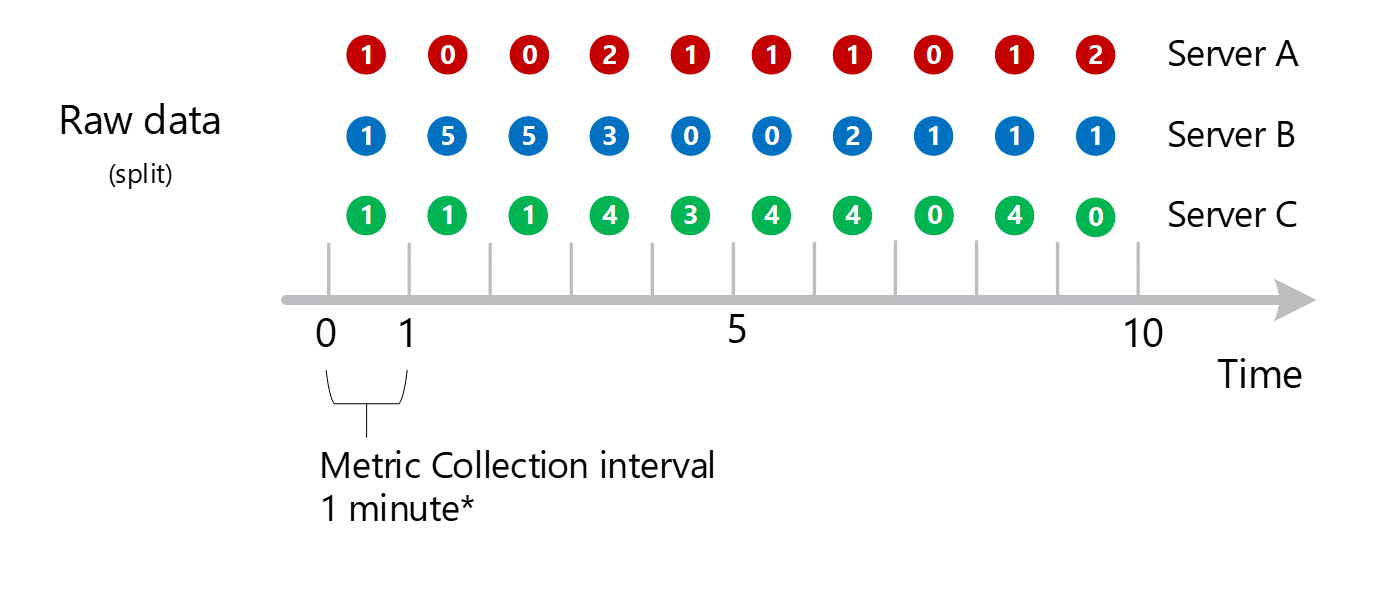
Agregacja wymiarów
Obliczenia 1-minutowe są następnie zagregowane na podstawie wymiarów i ponownie przechowywane jako poszczególne rekordy. W takim przypadku wszystkie dane ze wszystkich poszczególnych serwerów są agregowane do metryki interwału 1-minutowego i przechowywane w bazie danych metryk do użycia w późniejszych agregacjach.
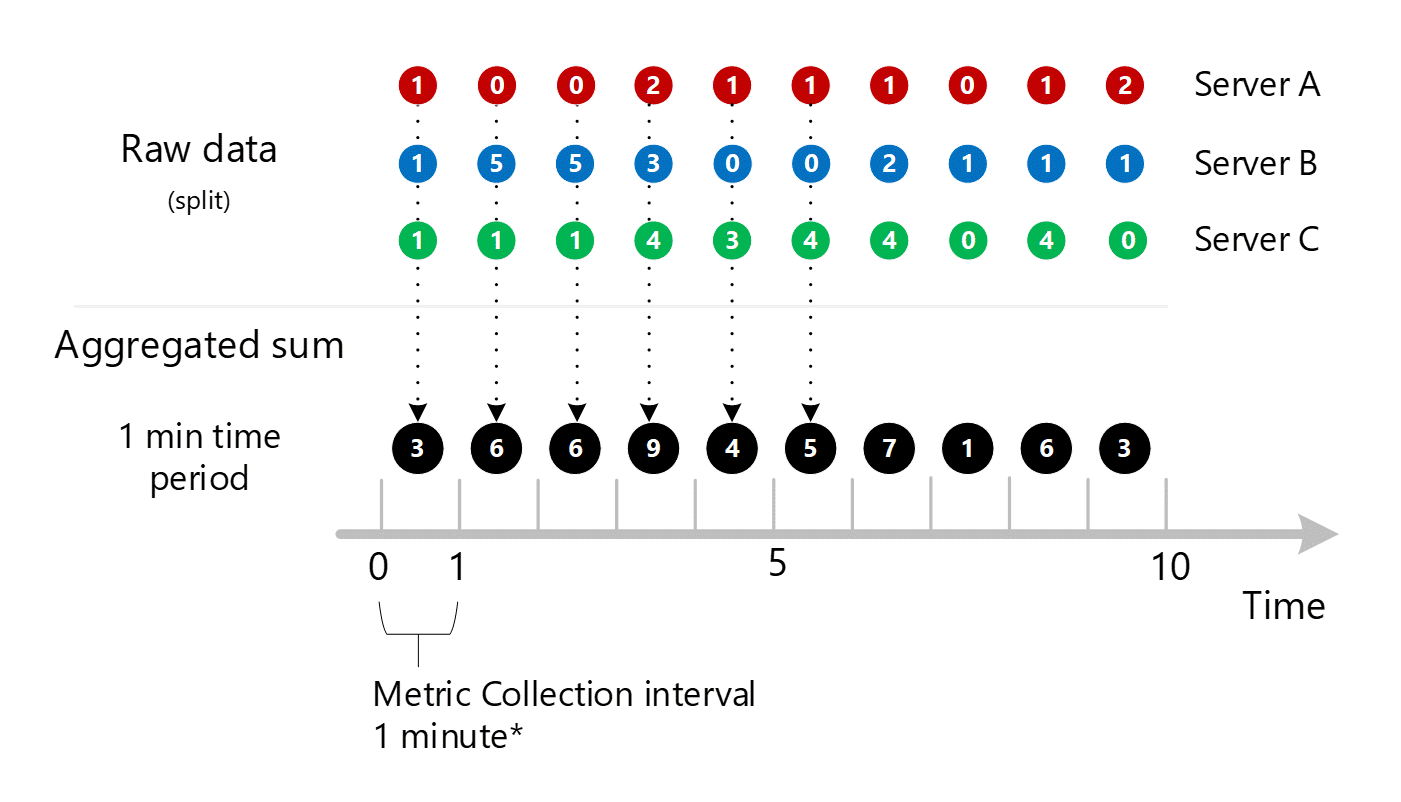
W celu zapewnienia przejrzystości poniższa tabela przedstawia metodę agregacji.
| Okres | Serwer A | Serwer B | Serwer C | Suma (A+B+C) |
|---|---|---|---|---|
| Minuta 1 | 1 | 1 | 1 | 3 |
| Minuta 2 | 0 | 5 | 1 | 6 |
| Minuta 3 | 0 | 5 | 1 | 6 |
| Minuta 4 | 2 | 3 | 4 | 9 |
| Minuta 5 | 1 | 0 | 3 | 4 |
| Minuta 6 | 1 | 0 | 4 | 5 |
| Minuta 7 | 1 | 2 | 4 | 7 |
| Minuta 8 | 0 | 1 | 0 | 1 |
| Minuta 9 | 1 | 1 | 4 | 6 |
| Minuta 10 | 2 | 1 | 0 | 3 |
Pokazano tylko jeden wymiar powyżej, ale ten sam proces agregacji i magazynowania występuje dla wszystkich wymiarów obsługiwanych przez metrykę.
- Zbierz wartości w zagregowanym 1-minutowym zestawie zgodnie z tym wymiarem. Przechowuj te wartości.
- Zwiń wymiar do jednominutowej zagregowanej sumy. Przechowuj te wartości.
Przedstawimy kolejny wymiar błędów HTTP o nazwie NetworkAdapter. Załóżmy, że mieliśmy różną liczbę adapterów na serwer.
- Serwer A ma 1 adapter
- Serwer B ma 2 karty sieciowe
- Serwer C ma 3 karty sieciowe
Zbieramy dane dla następujących transakcji oddzielnie. Będą one oznaczone następującymi znakami:
- Czas
- Wartość
- Serwer, z których pochodzi transakcja
- Adapter, z którego pochodzi transakcja
Każdy z tych strumieni subminutowych zostanie następnie zagregowany do 1-minutowych wartości szeregów czasowych i przechowywany w bazie danych metryk usługi Azure Monitor.
- Serwer A, Adapter 1
- Serwer B, adapter 1
- Serwer B, Adapter 2
- Serwer C, Adapter 1
- Serwer C, Adapter 2
- Serwer C, Adapter 3
Ponadto następujące zwinięte agregacje również będą przechowywane:
- Serwer A, Adapter 1 (ponieważ nie ma nic do zwinięcia, zostanie przechowany ponownie)
- Serwer B, Adapter 1+2
- Serwer C, Adapter 1+2+3
- Wszystkie serwery, wszystkie adaptery
Pokazuje to, że metryki o dużej liczbie wymiarów mają większą liczbę agregacji. Nie ważne jest, aby znać wszystkie permutacje, po prostu zrozumieć rozumowanie. System chce mieć zarówno poszczególne dane, jak i zagregowane dane przechowywane na potrzeby szybkiego pobierania w celu uzyskania dostępu na dowolnym wykresie. System wybiera najbardziej odpowiednią agregację przechowywaną lub bazowe dane pierwotne w zależności od wybranej opcji wyświetlania.
Agregacja bez wymiarów
Ponieważ ta metryka ma wymiar Serwer, możesz uzyskać dostęp do danych bazowych dla serwera A, B i C powyżej poprzez dzielenie i filtrowanie, jak wyjaśniono wcześniej w tym artykule. Jeśli metryka nie ma Serwera jako jednego z wymiarów, jako klient będziesz mógł uzyskać dostęp tylko do zagregowanych sum 1-minutowych wyświetlanych w czarnym na diagramie. Oznacza to, że wartości 3, 6, 6, 9 itp. System nie wykonywałby również podstawowej pracy w celu agregowania wartości podzielonych, które nigdy nie byłyby używane w Eksploratorze metryk ani wysyłane za pośrednictwem interfejsu API REST metryk.
Wyświetlanie granulacji czasu powyżej 1 minuty
Jeśli poprosisz o metryki z większym stopniem szczegółowości, system używa 1-minutowych sum zagregowanych do obliczania sum dla większych stopni szczegółowości czasu. Poniżej kropkowane linie pokazują metodę sumowania dla ziarnistości czasu 2-minutowej i 5-minutowej. Ponownie pokazujemy tylko typ agregacji SUM dla uproszczenia.
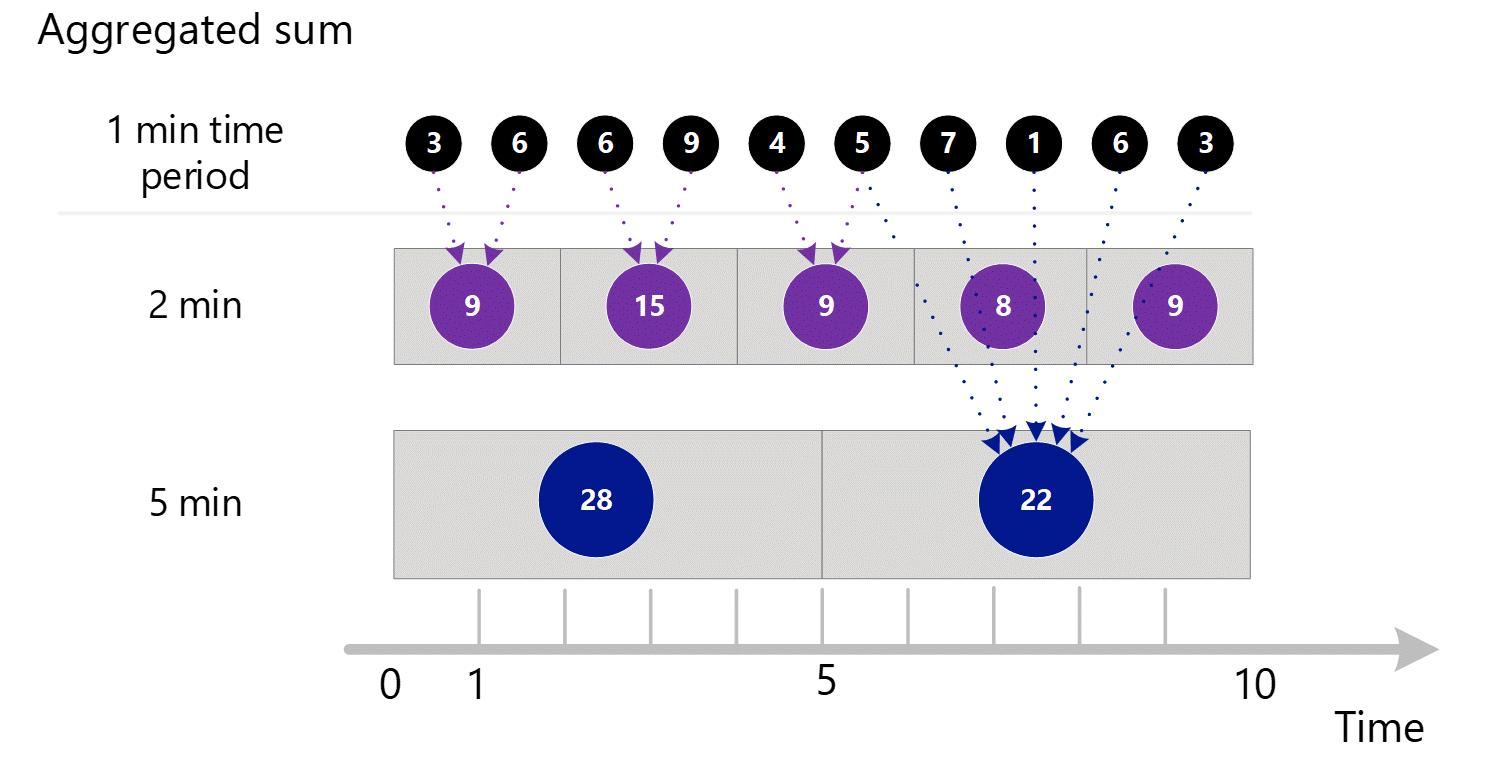
Dla 2-minutowej rozdzielczości czasowej.
| Okres | Sumy |
|---|---|
| Minuta 1 i 2 | (3 + 6) = 9 |
| Minuta 3 i 4 | (6 + 9) = 15 |
| Minuta 4 i 5 | (4 + 5) = 9 |
| Minuta 6 i 7 | (7 + 1) = 8 |
| Minuta 8 i 9 | (6 + 3) = 9 |
Dla 5-minutowej granularności czasu.
| Okres | Sumy |
|---|---|
| Minuta od 1 do 5 | 3 + 6 + 6 + 9 + 4 = 28 |
| Minuta od 6 do 10 | 5 + 7 + 1 + 6 + 3 = 22 |
System używa przechowywanych zagregowanych danych, które zapewniają najlepszą wydajność.
Poniżej znajduje się szerszy diagram dla wspomnianego wcześniej procesu agregacji trwającego minutę, a niektóre strzałki zostały pominięte, aby poprawić czytelność.
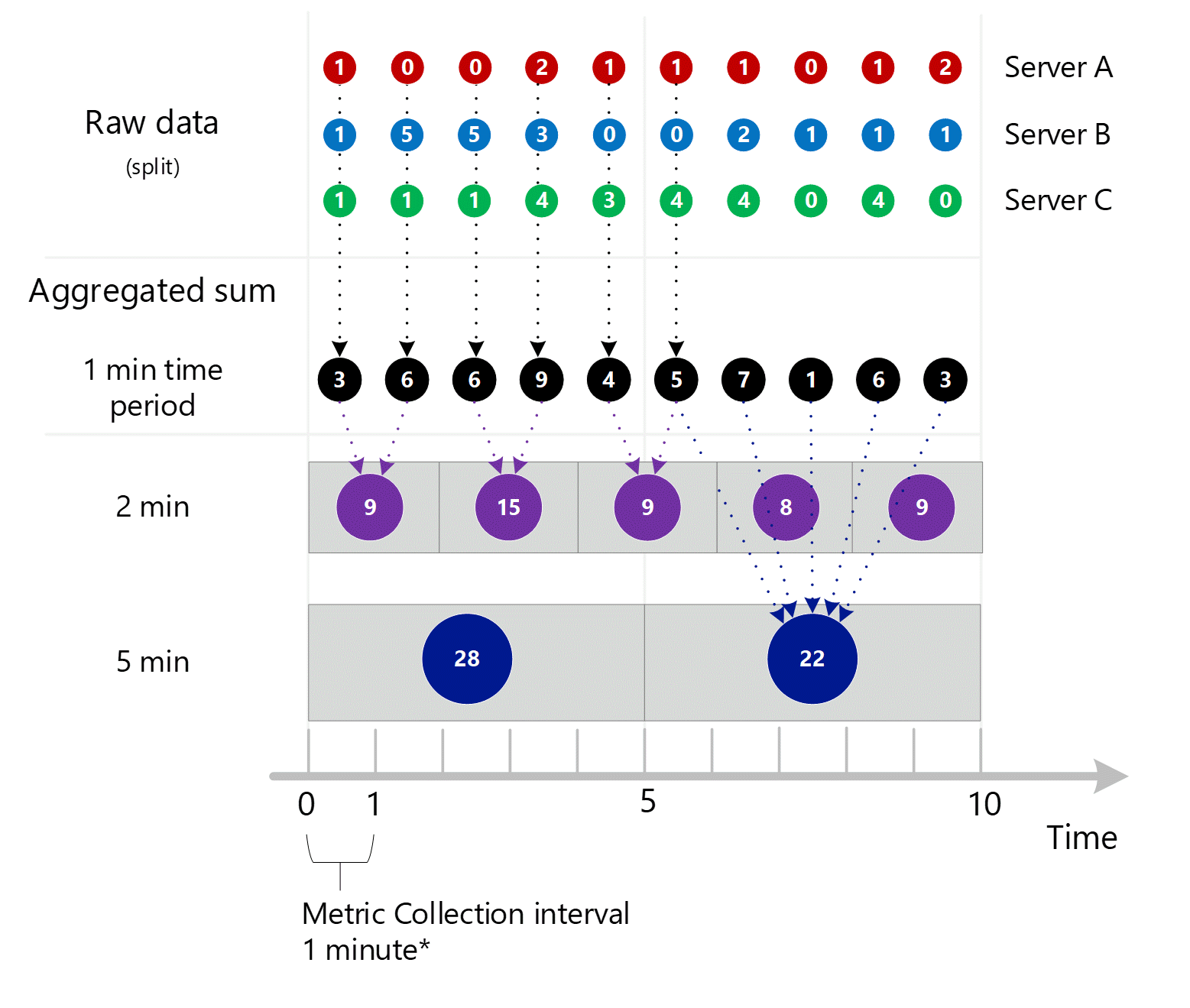
Bardziej złożony przykład
Poniżej przedstawiono większy przykład użycia wartości fikcyjnej metryki o nazwie Czas odpowiedzi HTTP w milisekundach. W tym miejscu wprowadzamy inne poziomy złożoności.
- Pokażemy agregację dla wartości Sum, Count, Min i Max oraz obliczenia dla wartości Average.
- Pokazujemy wartości NULL i ich wpływ na obliczenia.
Rozważmy poniższy przykład. Pola i strzałki pokazują przykłady sposobu agregowania i obliczania wartości.
Ten sam 1-minutowy proces wstępnej agregacji, jak opisano w poprzedniej sekcji, występuje w przypadku sumy, liczby, minimum i maksimum. Jednak średnia nie jest wstępnie agregowana. Jest on obliczany ponownie przy użyciu zagregowanych danych, aby uniknąć błędów obliczeń.

Rozważ minutę 6 w przypadku agregacji 1-minutowej, jak wyróżniono powyżej. Ten moment to punkt, w którym serwer B przeszedł w tryb offline i przestał raportować dane, być może z powodu ponownego uruchomienia.
Od minuty 6 powyżej obliczane typy agregacji 1-minutowe to:
| Typ agregacji | Wartość | Notatki |
|---|---|---|
| Suma | 53+20=73 | |
| Liczba | 2 | Pokazuje efekt NULL. Wartość byłaby 3, gdyby serwer był w trybie online. |
| Minimalna wartość | 20 | |
| Maksimum | 53 | |
| Średnia | 73 / 2 | Zawsze suma podzielona przez liczbę. Nigdy nie jest przechowywany i zawsze ponownie obliczany dla każdego stopnia szczegółowości przy użyciu zagregowanych liczb dla tego stopnia szczegółowości. Zwróć uwagę na ponowne obliczenie dla 5- i 10-minutowej granularności czasu, jak pokazano powyżej. |
Kolor czerwony tekstu wskazuje wartości, które mogą być traktowane jako poza normalnym zakresem i pokazuje, jak się propagują (lub nie), gdy wzrasta szczegółowość czasowa. Zwróć uwagę, że wartości Min i Max wskazują, że występują anomalie bazowe, podczas gdy wartości Średnia i Suma tracą te informacje w miarę upływu stopnia szczegółowości czasu.
Można również zauważyć, że wartości NULL dają lepszy wynik przy obliczaniu średniej, niż gdyby zamiast tego użyto zer.
Uwaga / Notatka
Chociaż w tym przykładzie nie jest tak, Count jest równe Sum w przypadkach, gdy metryka jest zawsze rejestrowana z wartością 1. Jest to typowe, gdy metryka śledzi wystąpienie zdarzenia transakcyjnego — na przykład liczbę błędów HTTP wymienionych w poprzednim przykładzie w tym artykule.