Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym artykule opisano sposób użycia działania kopiowania w potokach Azure Data Factory i Azure Synapse do kopiowania danych z i do bazy danych SQL Server oraz wykorzystania Przepływ danych do przekształcania danych w bazie danych SQL Server. Aby dowiedzieć się więcej, przeczytaj artykuł wprowadzający dotyczący Azure Data Factory lub Azure Synapse Analytics.
Uwaga
Ten łącznik jest również dostępny w usłudze Data Factory w Microsoft Fabric. Aby uzyskać informacje o konfiguracji i funkcjach specyficznych dla Fabric, zobacz dokumentację łącznika Fabric SQL Server.
Obsługiwane możliwości
Ten łącznik SQL Server jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | środowisko IR |
|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) |
| Mapowanie przepływu danych (źródło/ujście) | (1) |
| Działanie Lookup | (1) (2) |
| Działanie GetMetadata | (1) (2) |
| Działanie skryptu | (1) (2) |
| Działanie procedury składowanej | (1) (2) |
(1) Środowisko uruchomieniowe Azure (2) Środowisko uruchomieniowe lokalnie hostowane
Aby uzyskać listę magazynów danych obsługiwanych jako źródła lub ujścia przez działanie kopiowania, zobacz tabelę Obsługiwane magazyny danych.
W szczególności ten łącznik SQL Server obsługuje:
- SQL Server w wersji 2005 lub nowszej.
- Kopiowanie danych przy użyciu języka SQL lub Windows authentication.
- Jako źródło pobieranie danych przy użyciu zapytania SQL lub procedury składowanej. Możesz również wybrać kopiowanie równoległe ze źródła SQL Server, zobacz sekcję Kopiowanie równoległe z bazy danych SQL dla szczegółów.
- Jako ujście, automatyczne utworzenie tabeli docelowej, jeśli nie istnieje, na podstawie schematu źródłowego; dołączanie danych do tabeli lub wywoływanie procedury składowanej za pomocą niestandardowej logiki podczas kopiowania.
SQL Server Express LocalDB nie jest obsługiwana.
Ważne
Źródło danych musi obsługiwać typ danych NVARCHAR, ponieważ ma wpływ na kodowanie danych, gdy na danych jest stosowane nietypowe kodowanie.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować self-hosted Integration Runtime aby nawiązać z nim połączenie.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji zarządzanego środowiska wykonawczego zintegrowanej sieci wirtualnej w Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania lokalnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Wprowadzenie
Aby wykonać działanie kopiowania za pomocą pipeline'u, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Portal Azure
- SDK platformy .NET
- SDK języka Python
- Azure PowerShell
- API REST
- Szablon menedżera zasobów Azure
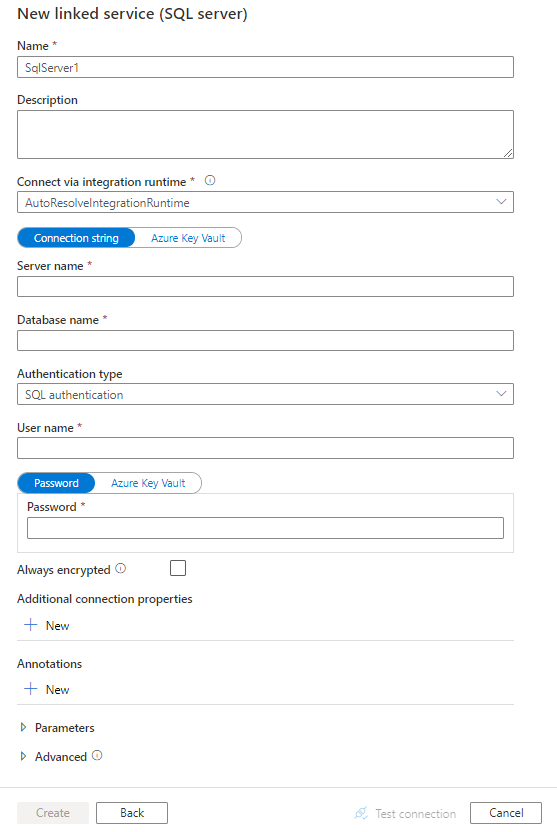
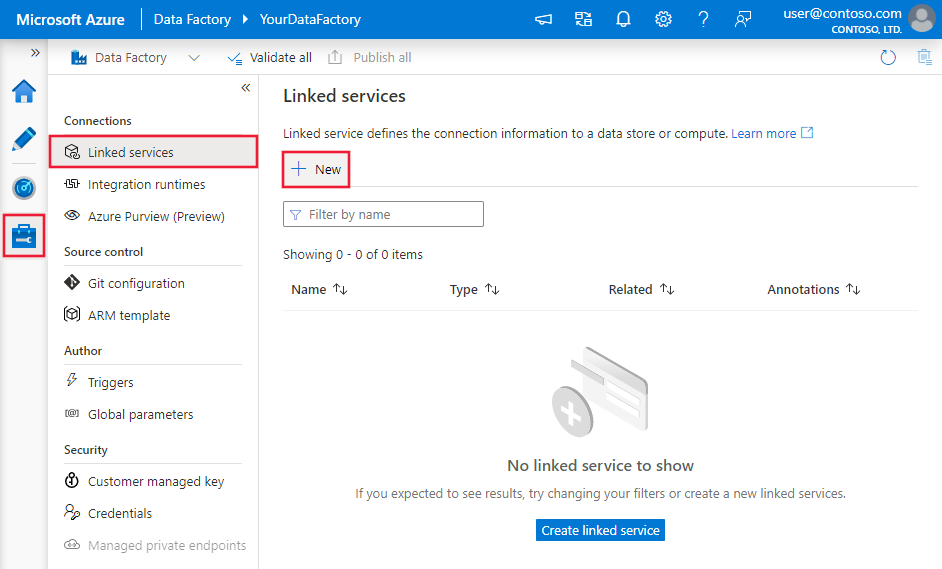
Tworzenie połączonej usługi SQL Server przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę SQL Server w interfejsie użytkownika portalu Azure.
Przejdź do karty Zarządzanie w obszarze roboczym Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj SQL i wybierz łącznik SQL Server.

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania elementów potoku Data Factory i Synapse specyficznych dla łącznika bazy danych SQL Server.
Właściwości połączonej usługi
Wersja SQL Server
Wskazówka
Jeśli wystąpi błąd z kodem błędu "UserErrorFailedToConnectToSqlServer", a komunikat taki jak "Limit sesji dla bazy danych to XXX i został osiągnięty", dodaj Pooling=false do parametry połączenia i spróbuj ponownie.
Rekomendowana wersja
Te właściwości ogólne są obsługiwane w przypadku połączonej usługi SQL Server w przypadku zastosowania zalecanej wersji:
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type musi być ustawiona na SqlServer. | Tak |
| serwer | Nazwa lub adres sieciowy wystąpienia programu SQL Server, z którym chcesz nawiązać połączenie. | Tak |
| baza danych | Nazwa bazy danych. | Tak |
| typ uwierzytelniania | Typ używany do uwierzytelniania. Dozwolone wartości to |
Tak |
| alwaysEncryptedSettings | Określ informacje, które są potrzebne do włączenia funkcji Always Encrypted, w celu ochrony poufnych danych przechowywanych na serwerze SQL przy użyciu tożsamości zarządzanej lub poświadczenia usługi. Aby uzyskać więcej informacji, zobacz przykład JSON w poniższej tabeli i sekcję Using Always Encrypted (Używanie funkcji Always Encrypted ). Jeśli nie zostanie określone, domyślnie ustawienie "zawsze szyfrowane" jest wyłączone. | Nie. |
| szyfrować | Określ, czy szyfrowanie TLS jest wymagane dla wszystkich danych wysyłanych między klientem a serwerem. Opcje: obowiązkowe (dla wartości true, domyślnie)/opcjonalne (dla wartości false)/ścisłe. | Nie. |
| ZaufajCertyfikatowiSerwera | Określ, czy kanał zostanie zaszyfrowany podczas pomijania łańcucha certyfikatów w celu zweryfikowania zaufania. | Nie. |
| hostNameInCertificate | Nazwa hosta do użycia podczas weryfikowania certyfikatu serwera dla połączenia. Jeśli nie zostanie określona, nazwa serwera jest używana do weryfikacji certyfikatu. | Nie. |
| connectVia | To środowisko uruchomieniowe integracji służy do połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie jest określone, używane jest domyślne Azure Integration Runtime. | Nie. |
Aby uzyskać dodatkowe właściwości połączenia, zobacz poniższą tabelę:
| Właściwości | Opis | Wymagane |
|---|---|---|
| zamiar aplikacji | Typ obciążenia aplikacji podczas nawiązywania połączenia z serwerem. Dozwolone wartości to ReadOnly i ReadWrite. |
Nie. |
| connectTimeout | Czas oczekiwania na połączenie z serwerem (w sekundach) przed zakończeniem próby i wygenerowaniem błędu. | Nie. |
| connectRetryCount | Liczba ponownych połączeń podjęta po zidentyfikowaniu błędu bezczynności połączenia. Wartość powinna być liczbą całkowitą z zakresu od 0 do 255. | Nie. |
| connectRetryInterval | Czas (w sekundach) między każdą ponowną próbą nawiązania połączenia po zidentyfikowaniu błędu bezczynności połączenia. Wartość powinna być liczbą całkowitą z zakresu od 1 do 60. | Nie. |
| loadBalanceTimeout | Minimalny czas (w sekundach), przez jaki połączenie może istnieć w puli połączeń przed jego zamknięciem. | Nie. |
| commandTimeout | Domyślny czas oczekiwania (w sekundach) przed zakończeniem próby wykonania polecenia i wygenerowaniem błędu. | Nie. |
| zintegrowaneBezpieczeństwo | Dozwolone wartości to true lub false. Podczas określania false parametru określ, czy nazwa użytkownika i hasło są określone w połączeniu. Podczas określania true wskazuje, czy bieżące poświadczenia konta Windows są używane do uwierzytelniania. |
Nie. |
| failoverPartner | Nazwa lub adres serwera partnerskiego do nawiązania połączenia, jeśli serwer podstawowy nie działa. | Nie. |
| maksymalnyRozmiarPuli | Maksymalna liczba połączeń dozwolonych w puli połączeń dla określonego połączenia. | Nie. |
| minPoolSize (Minimalny rozmiar puli) | Minimalna liczba połączeń dozwolonych w puli połączeń dla określonego połączenia. | Nie. |
| multipleActiveResultSets | Dozwolone wartości to true lub false. Po określeniu trueparametru aplikacja może obsługiwać wiele aktywnych zestawów wyników (MARS). Po określeniu falseparametru aplikacja musi przetworzyć lub anulować wszystkie zestawy wyników z jednej partii, zanim będzie mogła wykonać inne partie w tym połączeniu. |
Nie. |
| multiSubnetFailover | Dozwolone wartości to true lub false. Jeśli Twoja aplikacja łączy się z AlwaysOn availability group (AG) znajdującą się w różnych podsieciach, ustawienie tej właściwości na true pozwala na szybsze wykrywanie i nawiązywanie połączenia z aktualnie aktywnym serwerem. |
Nie. |
| rozmiar pakietu | Rozmiar pakietów sieciowych w bajtach używanych do komunikacji z instancją serwera. | Nie. |
| Buforowanie | Dozwolone wartości to true lub false. Po określeniu parametru true, połączenie zostanie włączone do puli. Po określeniu falseparametru połączenie zostanie jawnie otwarte przy każdym żądaniu połączenia. |
Nie. |
Uwierzytelnianie SQL
Aby użyć uwierzytelniania SQL, oprócz właściwości ogólnych opisanych w poprzedniej sekcji, określ następujące właściwości:
| Właściwości | Opis | Wymagane |
|---|---|---|
| userName | Nazwa użytkownika, która ma być używana podczas nawiązywania połączenia z serwerem. | Tak |
| hasło | Hasło dla nazwy użytkownika. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać. Możesz też odwołać się do tajemnicy przechowywanej w Azure Key Vault. | Nie. |
Przykład: Używanie uwierzytelniania SQL
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: użyj uwierzytelniania SQL z hasłem w Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: Używanie funkcji Always Encrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwierzytelnianie Windows
Aby użyć Windows authentication, oprócz właściwości ogólnych opisanych w poprzedniej sekcji, określ następujące właściwości:
| Właściwości | Opis | Wymagane |
|---|---|---|
| userName | Określ nazwę użytkownika. Przykładem jest nazwa_domeny\nazwa_użytkownika. | Tak |
| hasło | Ustal hasło dla konta użytkownika, które podałeś jako nazwę użytkownika. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać. Możesz też odwołać się do tajemnicy przechowywanej w Azure Key Vault. | Tak |
Uwaga
Uwierzytelnianie Windows nie jest obsługiwane w przepływie danych.
Przykład: użyj uwierzytelniania Windows
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: Używanie uwierzytelniania Windows z hasłem w Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"annotations": [],
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Uwierzytelnianie przypisanej przez użytkownika tożsamości zarządzanej
Uwaga
Uwierzytelnianie w oparciu o tożsamość zarządzaną przypisaną przez użytkownika ma zastosowanie wyłącznie do SQL Server na maszynach wirtualnych Azure.
Obszar roboczy fabryki danych lub usługi Synapse może być skojarzony z tożsamością zarządzaną przypisaną przez użytkownika, która reprezentuje usługę podczas uwierzytelniania do innych zasobów w Azure. Tej tożsamości zarządzanej można użyć do uwierzytelniania SQL Server na maszynach wirtualnych Azure. Wyznaczona fabryka lub obszar roboczy usługi Synapse mogą uzyskiwać dostęp do danych z lub do Twojej bazy danych oraz kopiować je przy użyciu tej tożsamości.
Aby użyć uwierzytelniania przy użyciu zarządzanej tożsamości przypisanej przez użytkownika, oprócz opisanych w poprzedniej sekcji właściwości ogólnych, określ następujące właściwości:
| Właściwości | Opis | Wymagane |
|---|---|---|
| dane logowania | Określ tożsamość zarządzaną przypisaną przez użytkownika jako obiekt poświadczeń. | Tak |
Należy również wykonać poniższe kroki:
Przyznaj uprawnienia przypisanej przez użytkownika tożsamości zarządzanej.
Włącz uwierzytelnianie Microsoft Entra na SQL Server na maszynach wirtualnych w Azure.
Utwórz użytkowników bazy danych w trybie izolowanym dla zarządzanej tożsamości przypisanej użytkownikowi. Nawiąż połączenie z bazą danych, do lub z której chcesz skopiować dane, używając takich narzędzi jak SQL Server Management Studio, z tożsamością Microsoft Entra posiadającą co najmniej uprawnienie ALTER ANY USER. Uruchom następujący kod T-SQL:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Utwórz jedną lub wiele tożsamości zarządzanych przypisanych przez użytkownika i przyznaj tożsamości zarządzanej przypisanej przez użytkownika wymagane uprawnienia, tak jak zwykle dla użytkowników SQL i innych. Uruchom następujący kod. Aby uzyskać więcej opcji, zobacz ten dokument.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Przypisz jedną lub wiele tożsamości zarządzanych przez użytkownika do fabryki danych i utwórz poświadczenia dla każdej z tych tożsamości.
Skonfiguruj połączoną usługę SQL Server.
Przykład
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Starsza wersja
Te właściwości ogólne są obsługiwane w przypadku usługi połączenia SQL Server, gdy zastosowana zostanie wersja Legacy:
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type musi być ustawiona na SqlServer. | Tak |
| alwaysEncryptedSettings | Określ informacje, które są potrzebne do włączenia funkcji Always Encrypted, w celu ochrony poufnych danych przechowywanych na serwerze SQL przy użyciu tożsamości zarządzanej lub poświadczenia usługi. Aby uzyskać więcej informacji, zobacz sekcję Using Always Encrypted (Używanie funkcji Always Encrypted ). Jeśli nie zostanie określone, domyślnie ustawienie "zawsze szyfrowane" jest wyłączone. | Nie. |
| connectVia | To środowisko uruchomieniowe integracji służy do połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie jest określone, używane jest domyślne Azure Integration Runtime. | Nie. |
Ten łącznik programu SQL Server obsługuje następujące typy uwierzytelniania. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje.
Uwierzytelnianie SQL dla starszej wersji
Aby użyć uwierzytelniania SQL, oprócz właściwości ogólnych opisanych w poprzedniej sekcji, określ następujące właściwości:
| Właściwości | Opis | Wymagane |
|---|---|---|
| Parametry połączenia | Określ connectionString informacje potrzebne do nawiązania połączenia z bazą danych SQL Server. Określ nazwę logowania jako nazwę użytkownika i upewnij się, że baza danych, z którą chcesz się połączyć, jest mapowana na to logowanie. | Tak |
| hasło | Jeśli chcesz umieścić hasło w Azure Key Vault, pobierz konfigurację password z parametry połączenia. Aby uzyskać więcej informacji, zobacz Przechowywanie poświadczeń w Azure Key Vault. |
Nie. |
Uwierzytelnianie Windows dla starszej wersji
Aby użyć Windows authentication, oprócz właściwości ogólnych opisanych w poprzedniej sekcji, określ następujące właściwości:
| Właściwości | Opis | Wymagane |
|---|---|---|
| Parametry połączenia | Określ connectionString informacje potrzebne do nawiązania połączenia z bazą danych SQL Server. | Tak |
| userName | Określ nazwę użytkownika. Przykładem jest nazwa_domeny\nazwa_użytkownika. | Tak |
| hasło | Ustal hasło dla konta użytkownika, które podałeś jako nazwę użytkownika. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać. Możesz też odwołać się do tajemnicy przechowywanej w Azure Key Vault. | Tak |
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych SQL Server.
Aby skopiować dane z i do bazy danych SQL Server, obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość type zestawu danych musi być ustawiona na SqlServerTable. | Tak |
| schemat | Nazwa schematu. | Nie dla źródła, Tak dla ujścia |
| tabela | Nazwa tabeli/widoku. | Nie dla źródła, Tak dla ujścia |
| tableName | Nazwa tabeli/widoku z schematem bazy danych. Ta właściwość jest obsługiwana w celu zapewnienia kompatybilności z poprzednimi wersjami. W przypadku nowego obciążenia roboczego użyj elementów schema i table. |
Nie dla źródła, Tak dla ujścia |
Przykład
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Właściwości aktywności kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do użycia do definiowania działań, zobacz artykuł Pipelines. Ta sekcja przedstawia listę właściwości obsługiwanych przez źródło i odbiornik SQL Server.
SQL Server jako źródło
Wskazówka
Aby wydajnie ładować dane z serwera SQL przy użyciu partycjonowania danych, dowiedz się więcej na temat kopiowania równoległego z bazy danych SQL.
Aby skopiować dane z SQL Server, ustaw typ źródła w działaniu kopiowania na wartość SqlSource. Następujące właściwości są obsługiwane w sekcji źródłowej działania kopiowania:
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość typu źródła operacji kopiowania musi być ustawiona na SqlSource. | Tak |
| sqlReaderQuery | Użyj niestandardowego zapytania SQL, aby odczytać dane. Może to być na przykład select * from MyTable. |
Nie. |
| sqlReaderStoredProcedureName | Ta właściwość jest nazwą procedury składowanej, która odczytuje dane z tabeli źródłowej. Ostatnia instrukcja SQL musi być instrukcją SELECT w procedurze składowanej. | Nie. |
| parametryProcedurySkładowanej | Te parametry są przeznaczone dla procedury składowanej. Dozwolone wartości to pary nazw lub wartości. Nazwy i wielkość liter parametrów muszą być zgodne z nazwami i wielkością liter parametrów procedury składowanej. |
Nie. |
| poziom izolacji | Określa zachowanie blokowania transakcji dla źródła SQL. Dozwolone wartości to: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Jeśli nie zostanie określony, zostanie użyty domyślny poziom izolacji bazy danych. Aby uzyskać więcej informacji, zapoznaj się z tym dokumentem . | Nie. |
| opcjePodziału | Określa opcje partycjonowania danych używane do ładowania danych z SQL Server. Dozwolone wartości to: Brak (wartość domyślna), PhysicalPartitionsOfTable i DynamicRange. Po włączeniu opcji partycji (czyli nie None), stopień równoległości równoczesnego ładowania danych z SQL Server jest kontrolowany przez ustawienie parallelCopies w działaniu kopiowania. |
Nie. |
| ustawienia partycji | Określ grupę ustawień partycjonowania danych. Zastosuj, gdy opcja partycji nie jest None. |
Nie. |
W obszarze partitionSettings: |
||
| partitionColumnName | Określ nazwę kolumny źródłowej o typie liczby całkowitej lub daty/czasu (int, smallint, bigint, date, smalldatetime, datetime, datetime2, lub datetimeoffset), która będzie używana do partycjonowania zakresu dla kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli zostanie automatycznie wykryty i użyty jako kolumna partycji.Zastosuj, gdy opcja partycji to DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, ustaw ?DfDynamicRangePartitionCondition w klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopiowanie równoległe z bazy danych SQL. |
Nie. |
| partitionUpperBound | Maksymalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną spartycjonowane i skopiowane. Jeśli wartość nie zostanie określona, działanie kopiowania automatycznie ją wykryje. Zastosuj, gdy opcja partycji to DynamicRange. Aby zapoznać się z przykładem, zobacz sekcję Kopiowanie równoległe z bazy danych SQL. |
Nie. |
| dolna granica partycji | Minimalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną spartycjonowane i skopiowane. Jeśli wartość nie zostanie określona, działanie kopiowania automatycznie ją wykryje. Zastosuj, gdy opcja partycji to DynamicRange. Aby zapoznać się z przykładem, zobacz sekcję Kopiowanie równoległe z bazy danych SQL. |
Nie. |
Pamiętaj o następujących kwestiach:
- Jeśli sqlReaderQuery jest określony dla SqlSource działanie kopiowania uruchamia to zapytanie względem źródła SQL Server w celu pobrania danych. Można również określić procedurę składowaną, podając sqlReaderStoredProcedureName i storedProcedureParameters, jeśli procedura składowana przyjmuje parametry.
- W przypadku używania procedury składowanej w źródle do pobierania danych należy pamiętać, że procedura składowana jest zaprojektowana jako zwracanie innego schematu po przekazaniu innej wartości parametru, może wystąpić błąd lub nieoczekiwany wynik podczas importowania schematu z interfejsu użytkownika lub kopiowania danych do bazy danych SQL z automatycznym tworzeniem tabeli.
Przykład: używanie zapytania SQL
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Przykład: użyj procedury składowanej
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definicja procedury składowanej
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL Server jako odbiornik
Wskazówka
Dowiedz się więcej o obsługiwanych zachowaniach zapisu, konfiguracjach i najlepszych praktykach w artykule Najlepsze praktyki ładowania danych do SQL Server.
Aby skopiować dane do SQL Server, ustaw typ ujścia w działaniu kopiowania na SqlSink. Następujące właściwości są obsługiwane w sekcji ujścia działania kopiowania:
| Właściwości | Opis | Wymagane |
|---|---|---|
| typ | Właściwość typu zlecenia kopiowania musi być ustawiona na SqlSink. | Tak |
| preCopyScript | Ta właściwość określa zapytanie SQL dla działania kopiowania do uruchomienia przed zapisaniem danych w SQL Server. Jest wywoływany tylko raz na przebieg kopiowania. Za pomocą tej właściwości można wyczyścić wstępnie załadowane dane. | Nie. |
| opcjaTabeli | Określa, czy automatycznie utworzyć tabelę ujścia, jeśli nie istnieje na podstawie schematu źródłowego. Automatyczne tworzenie tabeli nie jest obsługiwane, gdy ujście określa procedurę składowaną. Dozwolone wartości to: none (wartość domyślna), autoCreate. |
Nie. |
| sqlWriterStoredProcedureName (nazwa procedury składowanej sqlWriter) | Nazwa procedury składowanej, która definiuje sposób stosowania danych źródłowych do tabeli docelowej. Ta procedura składowana jest wywoływana na partię. W przypadku operacji uruchamianych tylko raz, które nie mają nic wspólnego z danymi źródłowymi, na przykład usuń lub skróć, użyj właściwości preCopyScript.Zobacz przykład z wywołania procedury składowanej z ujścia SQL. |
Nie. |
| nazwaParametruTypuTabeliProcedurySkładowanej | Nazwa parametru typu tabeli określona w procedurze składowanej. | Nie. |
| sqlWriterTableType | Nazwa typu tabeli, która ma być używana w procedurze składowanej. Działanie kopiowania danych sprawia, że dane są dostępne w tabeli tymczasowej o tym typie tabeli. Kod procedury składowanej może następnie scalić dane kopiowane z istniejącymi danymi. | Nie. |
| parametryProcedurySkładowanej | Parametry procedury składowanej. Dozwolone wartości to pary nazw i wartości. Nazwy parametrów i wielkość liter w ich nazwach muszą być zgodne z nazwami i wielkością liter parametrów procedury składowanej. |
Nie. |
| writeBatchSize | Liczba wierszy do wstawienia do tabeli SQL na partię. Dozwolone wartości to liczby całkowite dla liczby wierszy. Domyślnie usługa dynamicznie określa odpowiedni rozmiar partii na podstawie rozmiaru wiersza. |
Nie. |
| writeBatchTimeout | Czas oczekiwania na ukończenie operacji wstawiania, operacji upsert i procedury składowanej przed przekroczeniem limitu czasu. Dozwolone wartości są dla przedziału czasu. Przykładem jest "00:30:00" przez 30 minut. Jeśli żadna wartość nie zostanie określona, limit czasu zostanie domyślnie określony na "00:30:00". |
Nie. |
| maksymalnaLiczbaJednoczesnychPołączeń | Górny limit połączeń współbieżnych nawiązanych z magazynem danych podczas przebiegu działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
| WriteBehavior | Określ zachowanie zapisu dla działania kopiowania w celu załadowania danych do bazy danych SQL Server. Dozwolona wartość to Insert i Upsert. Domyślnie usługa używa wstawiania do ładowania danych. |
Nie. |
| upsertSettings | Określ grupę ustawień zachowania zapisu. Zastosuj, gdy opcja WriteBehavior ma wartość Upsert. |
Nie. |
W obszarze upsertSettings: |
||
| useTempDB | Określ, czy chcesz użyć globalnej tabeli tymczasowej, czy tabeli fizycznej jako tabeli tymczasowej dla operacji upsert. Domyślnie usługa używa globalnej tabeli tymczasowej jako tabeli przejściowej. wartość to true. |
Nie. |
| interimSchemaName | Określ schemat tymczasowy do tworzenia tabeli tymczasowej, jeśli jest używana tabela fizyczna. Uwaga: użytkownik musi mieć uprawnienia do tworzenia i usuwania tabeli. Domyślnie tabela tymczasowa będzie współdzielić ten sam schemat co tabela ujścia. Zastosuj, gdy opcja useTempDB to False. |
Nie. |
| klucze | Określ nazwy kolumn dla unikalnej identyfikacji wierszy. Można użyć pojedynczego klucza lub serii kluczy. Jeśli nie zostanie określony, używany jest klucz podstawowy. | Nie. |
Przykład 1. Dołączanie danych
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Przykład 2: Wywoływanie procedury składowanej podczas kopiowania
Dowiedz się więcej na stronie Wywoływanie procedury składowanej z ujścia SQL.
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Przykład 3: Wstawianie lub aktualizowanie danych
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Równoległa kopia z bazy danych SQL
Łącznik SQL Server w działaniu kopiowania zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych. Opcje partycjonowania danych można znaleźć na karcie Źródło działania kopiowania.
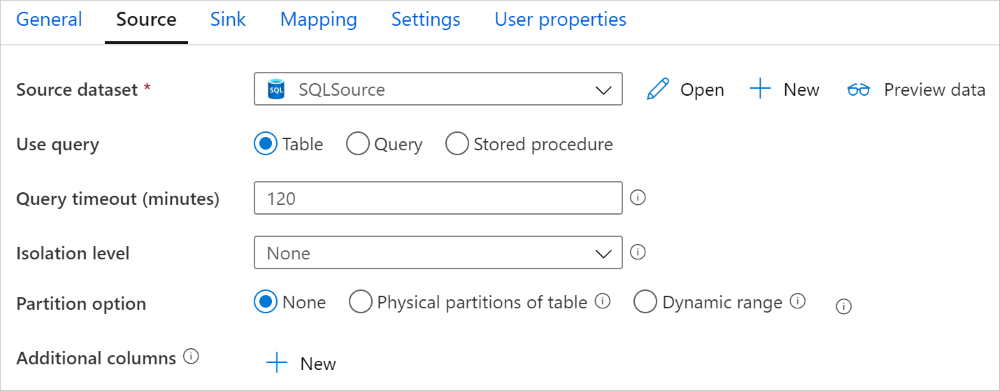
Po włączeniu kopii partycjonowanej działanie kopiowania uruchamia zapytania równoległe względem źródła SQL Server w celu załadowania danych według partycji. Stopień przetwarzania równoległego jest kontrolowany przez ustawienie w ramach działania kopiowania parallelCopies. Jeśli na przykład ustawisz parallelCopies na cztery, usługa współbieżnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z SQL Server.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku ładowania dużej ilości danych z SQL Server. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Pełne ładowanie z dużej tabeli z fizycznymi partycjami. |
Opcja partycji: Fizyczne podziały tabeli. Podczas wykonywania usługa automatycznie wykrywa partycje fizyczne i kopiuje dane według partycji. Aby sprawdzić, czy tabela ma partycję fizyczną, czy nie, możesz odwołać się do tego zapytania. |
| Pełne ładowanie z dużej tabeli, bez partycji fizycznych, z zastosowaniem kolumny liczbowej całkowitej lub datetime do partycjonowania danych. |
Opcje partycji: partycja zakresu dynamicznego. Kolumna partycji (opcjonalnie): określ kolumnę używaną do partycjonowania danych. Jeśli nie zostanie określona, zostanie użyta kolumna klucza podstawowego. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie dotyczy to filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli zostaną podzielone na partycje i skopiowane. Jeśli wartości nie zostaną określone, operacja kopiowania automatycznie wykrywa wartości i może potrwać długo w zależności od wartości MIN i MAX. Zaleca się podanie górnej granicy i dolnej granicy. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona na wartość 20, a górna granica to 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego, bez partycji fizycznych, natomiast z liczbą całkowitą lub kolumną date/datetime na potrzeby partycjonowania danych. |
Opcje partycji: partycja zakresu dynamicznego. Zapytanie: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie jest to przeznaczone do filtrowania wierszy w tabeli, wszystkie wiersze w wyniku zapytania zostaną partycjonowane i skopiowane. Jeśli wartość nie zostanie określona, działanie kopiowania automatycznie ją wykryje. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona jako 20 i górna granica jako 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. Poniżej przedstawiono więcej przykładowych zapytań dla różnych scenariuszy: 1. Wykonaj zapytanie względem całej tabeli: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Kwerenda z tabeli z zaznaczeniem kolumny i dodatkowymi filtrami klauzuli where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Kwerenda z podzapytaniami: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Kwerenda z partycją w zapytaniu podrzędnym: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Najlepsze rozwiązania dotyczące ładowania danych z opcją partycji:
- Wybierz charakterystyczną kolumnę jako kolumnę partycji (np. klucz podstawowy lub unikatowy klucz), aby uniknąć niesymetryczności danych.
- Jeśli tabela ma wbudowaną partycję, użyj opcji partycji "Partycje fizyczne tabeli", aby uzyskać lepszą wydajność.
- Jeśli używasz Azure Integration Runtime do kopiowania danych, możesz ustawić większe "Data Integration Units (DIU)" (>4), aby wykorzystać więcej zasobów obliczeniowych. Sprawdź odpowiednie scenariusze tam.
- "Stopień równoległości kopiowania" określa liczby partycji; ustawienie tej liczby zbyt wysoko może czasami obniżyć wydajność. Zaleca się ustawienie tej liczby jako (DIU lub liczba węzłów IR hostowanych lokalnie) * (od 2 do 4)."
Przykład: pełne ładowanie z dużej tabeli z partycjami fizycznymi
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Przykład: zapytanie z dynamicznym podziałem na zakresy
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Przykładowe zapytanie do sprawdzania partycji fizycznej
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Jeśli tabela ma partycję fizyczną, zostanie wyświetlona wartość "HasPartition" jako "tak", jak pokazano poniżej.

Najlepsze rozwiązanie dotyczące ładowania danych do SQL Server
Podczas kopiowania danych do SQL Server może być wymagane inne zachowanie zapisu:
- Dołącz: Moje dane źródłowe mają tylko nowe rekordy.
- Upsert: Moje dane źródłowe mają zarówno wstawki, jak i aktualizacje.
- Zastąp: Chcę ponownie załadować całą tabelę wymiarów za każdym razem.
- Pisanie za pomocą logiki niestandardowej: potrzebuję dodatkowego przetwarzania przed ostatecznym wstawieniem do tabeli docelowej.
Zapoznaj się z odpowiednimi sekcjami, aby dowiedzieć się, jak skonfigurować i najlepsze rozwiązania.
Dołączanie danych
Dołączanie danych jest domyślnym zachowaniem tego łącznika ujścia SQL Server. Usługa wykonuje operację wstawiania zbiorczego, aby efektywnie zapisywać dane w tabeli. Źródło i ujście można skonfigurować odpowiednio w działaniu kopiowania.
Wykonywanie operacji upsert dla danych
działanie Kopiuj obsługuje teraz natywne ładowanie danych do tymczasowej tabeli bazy danych i aktualizuje dane w tabeli docelowej, jeśli klucz istnieje, lub wstawia nowe dane w przeciwnym wypadku. Aby dowiedzieć się więcej na temat ustawień upsert w działaniach kopiowania, zobacz SQL Server jako ujście.
Zastąp całą tabelę
Właściwość preCopyScript można skonfigurować w ujściu działania kopiowania. W takim przypadku dla każdego uruchomionego działania kopiowania usługa uruchamia skrypt jako pierwszy. Następnie uruchamia kopię, aby wstawić dane. Aby na przykład zastąpić całą tabelę najnowszymi danymi, określ skrypt, aby najpierw usunąć wszystkie rekordy przed zbiorczym załadowaniem nowych danych ze źródła.
Zapisywanie danych przy użyciu logiki niestandardowej
Kroki, które należy podjąć, aby zapisywać dane za pomocą logiki niestandardowej, są podobne do tych opisanych w sekcji Upsert data. Jeśli musisz zastosować dodatkowe przetwarzanie przed ostatecznym wstawieniem danych źródłowych do tabeli docelowej, możesz załadować dane do tabeli przejściowej, a następnie wywołać działanie procedury składowanej lub wywołać procedurę składowaną jako część ujścia działania kopiowania, aby przetworzyć dane.
Wywoływanie procedury składowanej z ujścia SQL
Podczas kopiowania danych do bazy danych SQL Server można również skonfigurować i wywołać procedurę składowaną określoną przez użytkownika z dodatkowymi parametrami w każdej partii tabeli źródłowej. Funkcja procedury składowanej korzysta z parametrów tabelarycznych. Należy pamiętać, że usługa automatycznie opakowuje procedurę przechowywaną we własnej transakcji, więc każda transakcja utworzona wewnątrz procedury przechowywanej stanie się transakcją zagnieżdżoną i może wpływać na obsługę wyjątków.
Procedurę składowaną można użyć, gdy wbudowane mechanizmy kopiowania nie obsługują tego celu. Przykładem jest zastosowanie dodatkowego przetwarzania przed ostatecznym wstawieniem danych źródłowych do tabeli docelowej. Niektóre dodatkowe przykłady przetwarzania to, gdy chcesz scalić kolumny, wyszukać dodatkowe wartości i wstawić je do więcej niż jednej tabeli.
W poniższym przykładzie pokazano, jak za pomocą procedury składowanej wykonać operację upsert w tabeli w bazie danych SQL Server. Załóżmy, że dane wejściowe i docelowa tabela Marketing mają trzy kolumny: ProfileID, State i Category. Wykonaj upsert w oparciu o kolumnę ProfileID i zastosuj go tylko do określonej kategorii o nazwie "ProductA".
W bazie danych zdefiniuj typ tabeli o takiej samej nazwie jak sqlWriterTableType. Schemat typu tabeli jest taki sam jak schemat zwracany przez dane wejściowe.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )W bazie danych zdefiniuj procedurę składowaną o takiej samej nazwie jak sqlWriterStoredProcedureName. Obsługuje dane wejściowe z określonego źródła i scala je z tabelą wyjściową. Nazwa parametru typu tabeli w procedurze składowanej jest taka sama jak nazwa_tabeli zdefiniowana w zestawie danych.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDZdefiniuj sekcję ujścia SQL w działaniu kopiowania w następujący sposób:
"sink": { "type": "SqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Właściwości odwzorowania przepływu danych
Podczas przekształcania danych w przepływie mapowania danych można odczytywać i zapisywać w tabelach z bazy danych SQL Server. Aby uzyskać więcej informacji, zobacz przekształcanie źródła i przekształcanie ujścia w przepływach danych mapowania.
Uwaga
Aby uzyskać dostęp do lokalnego SQL Server, musisz użyć Azure Data Factory lub obszaru roboczego Synapse Managed Virtual Network z wykorzystaniem prywatnego punktu końcowego. Zapoznaj się z tym samouczkiem , aby uzyskać szczegółowe instrukcje.
Przekształcanie źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło SQL Server. Te właściwości można edytować na karcie Opcje źródła.
| Nazwa/nazwisko | Opis | Wymagane | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Tabela | Jeśli wybierzesz opcję Tabela jako dane wejściowe, przepływ danych pobierze wszystkie dane z tabeli określonej w zestawie danych. | Nie. | - | - |
| Zapytanie | Jeśli wybierzesz pozycję Zapytanie jako dane wejściowe, określ zapytanie SQL, aby pobrać dane ze źródła, które zastępuje dowolną tabelę, którą określisz w zestawie danych. Korzystanie z zapytań to doskonały sposób na zmniejszenie liczby wierszy na potrzeby testowania lub wyszukiwania. Klauzula Order By nie jest obsługiwana, ale można ustawić pełną instrukcję SELECT FROM. Można również użyć funkcji tabeli zdefiniowanych przez użytkownika. select * from udfGetData() jest funkcją UDF w SQL, która zwraca tabelę, której można użyć w przepływie danych. Przykład zapytania: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Nie. | String | kwerenda |
| Rozmiar partii | Określ rozmiar partii do dzielenia dużych danych na odczyty. | Nie. | Integer | batchSize |
| Poziom izolacji | Wybierz jeden z następujących poziomów izolacji: - Odczyt zatwierdzony - Odczyt niezatwierdzony (ustawienie domyślne) - Powtarzalny odczyt -Serializowalny - Brak (ignoruj poziom izolacji) |
Nie. | READ_COMMITTED READ_UNCOMMITTED ODCZYT POWTARZALNY SERIALIZOWALNY BRAK |
poziom izolacji |
| Włącz wyodrębnianie przyrostowe | Użyj tego ustawienia, aby poinformować usługę ADF o przetwarzaniu tylko tych wierszy, które uległy zmianie od czasu ostatniego wykonania potoku danych. | Nie. | - | - |
| Kolumna daty przyrostowej | W przypadku korzystania z funkcji wyodrębniania inkrementalnego należy wybrać kolumnę daty/godziny, aby używać jej jako znacznika w tabeli źródłowej. | Nie. | - | - |
| Włączanie natywnego przechwytywania danych zmian (wersja zapoznawcza) | Użyj tej opcji, aby poinformować usługę ADF o przetwarzaniu tylko danych różnicowych przechwyconych przez technologię przechwytywania zmian SQL od czasu ostatniego wykonania potoku. Dzięki tej opcji dane różnicowe, w tym wstawianie wierszy, aktualizowanie i usuwanie, zostaną załadowane automatycznie bez konieczności wprowadzania przyrostowej kolumny dat. Przed użyciem tej opcji w usłudze ADF należy włączyć rejestrowanie zmian danych na serwerze SQL. Aby uzyskać więcej informacji na temat tej opcji w usłudze ADF, zobacz przechwytywanie danych zmian natywnych. | Nie. | - | - |
| Rozpocznij czytanie od początku | Ustawienie tej opcji z włączonym wyodrębnianiem przyrostowym spowoduje, że usługa ADF odczyta wszystkie wiersze podczas pierwszego uruchomienia potoku z wyodrębnianiem przyrostowym. | Nie. | - | - |
Wskazówka
Wspólne wyrażenie tabeli (CTE) w SQL nie jest obsługiwane w trybie zapytania przepływu danych mapowania, ponieważ ten tryb wymaga, aby zapytania mogły być używane w klauzuli FROM zapytania SQL, ale CTE nie może być używane w ten sposób. Aby użyć CTE, należy utworzyć procedurę składowaną, korzystając z następującego zapytania:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Następnie użyj trybu procedury składowanej w transformacji źródłowej przepływu danych mapowania i ustaw @query jak przykład with CTE as (select 'test' as a) select * from CTE. Następnie można użyć CTEs zgodnie z oczekiwaniami.
przykład skryptu źródłowego SQL Server
Jeśli używasz SQL Server jako typu źródła, skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSource
Przekształcenie ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez ujście SQL Server. Te właściwości można edytować na karcie Opcje ujścia.
| Nazwa/nazwisko | Opis | Wymagane | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Metoda aktualizacji | Określ, jakie operacje są dozwolone w miejscu docelowym bazy danych. Ustawieniem domyślnym jest zezwalanie tylko na wstawianie. Aby zaktualizować, dodać lub zaktualizować lub usunąć wiersze, wymagane jest zastosowanie Alter row transformation do tagowania tych wierszy dla odpowiednich działań. |
Tak |
true lub false |
możliwe do usunięcia wstawialny możliwe do aktualizacji dodawalno-aktualizowalne |
| Kolumny kluczy | W przypadku aktualizacji, operacji upserts i delete należy ustawić kolumny kluczy, aby określić, który wiersz ma zostać zmieniony. Nazwa kolumny wybranej jako klucz będzie używana w ramach kolejnej aktualizacji, upsert, delete. W związku z tym należy wybrać kolumnę, która istnieje w mapowaniu ujścia. |
Nie. | Tablica | klucze |
| Pomiń zapisywanie kolumn kluczy | Jeśli nie chcesz zapisywać wartości w kolumnie klucza, wybierz pozycję "Pomiń pisanie kolumn kluczy". | Nie. |
true lub false |
skipKeyWrites |
| Akcja tabeli | Określa, czy należy ponownie utworzyć lub usunąć wszystkie wiersze z tabeli docelowej przed zapisem. - Brak: żadna akcja nie zostanie wykonana w tabeli. - Zrekonstruuj: tabela zostanie usunięta i utworzona ponownie. Wymagane w przypadku dynamicznego tworzenia nowej tabeli. - Truncate: Wszystkie wiersze z tabeli docelowej zostaną usunięte. |
Nie. |
true lub false |
odtworzyć obcinać |
| Rozmiar partii | Określ liczbę wierszy zapisywanych w każdej partii. Większe rozmiary partii zwiększają kompresję i optymalizację pamięci, ale istnieje ryzyko wystąpienia błędów pamięci podczas buforowania danych. | Nie. | Integer | batchSize |
| Skrypty SQL przed i po | Określ wielowierszowe skrypty SQL, które będą wykonywane przed (wstępne przetwarzanie) i po (przetwarzanie końcowe), gdy dane są zapisywane w docelowej bazie danych. | Nie. | String | preSQLs postSQLs |
Wskazówka
- Zaleca się podzielenie pojedynczych skryptów wsadowych z wieloma poleceniami na wiele partii.
- W ramach partii można uruchamiać tylko instrukcje języka DDL (Data Definition Language) i Języka manipulowania danymi (DML), które zwracają prostą liczbę aktualizacji. Dowiedz się więcej na temat wykonywania operacji wsadowych
przykładowy skrypt ujścia SQL Server
W przypadku użycia SQL Server jako typu ujścia skojarzony skrypt przepływu danych to:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSink
Mapowanie typów danych dla SQL Server
Podczas kopiowania danych z SQL Server i do niego, używane są następujące mapowania z typów danych SQL Server do tymczasowych typów danych w Azure Data Factory. Potoki usługi Synapse, które implementują usługę Data Factory, używają tych samych mapowań. Aby dowiedzieć się, jak operacja kopiowania mapuje schemat źródłowy i typ danych na miejsce docelowe, zobacz Mapowanie schematu i typu danych.
| typ danych SQL Server | Typ danych tymczasowych usługi Data Factory |
|---|---|
| bigint | Int64 |
| binarny | Byte[] |
| bit | logiczny |
| char | Ciąg, Znak[] |
| data | DateTime |
| Data i czas | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Liczba dziesiętna | Liczba dziesiętna |
| Atrybut FILESTREAM (typ varbinary(max)) | Byte[] |
| float | Podwójna precyzja |
| obraz | Byte[] |
| int | Int32 |
| pieniądze | Liczba dziesiętna |
| nchar | Ciąg, Znak[] |
| ntekst | Ciąg, Znak[] |
| liczbowe | Liczba dziesiętna |
| nvarchar | Ciąg, Znak[] |
| rzeczywiste | Pojedynczy |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| smallint | Int16 |
| smallmoney | Liczba dziesiętna |
| sql_variant | Objekt |
| SMS | Ciąg, Znak[] |
| czas | przedział_czasu |
| sygnatura czasowa | Byte[] |
| tinyint | Int16 |
| unikalny identyfikator | Identyfikator GUID |
| varbinary | Byte[] |
| varchar | Ciąg, Znak[] |
| xml | String |
Uwaga
W przypadku typów danych mapujących na tymczasowy typ dziesiętny, obecnie funkcja działanie Kopiuj obsługuje precyzję do 28. Jeśli masz dane, które wymagają precyzji większej niż 28, rozważ przekonwertowanie na ciąg w zapytaniu SQL.
Podczas kopiowania danych z SQL Server przy użyciu Azure Data Factory typ danych bit jest mapowany na tymczasowy typ danych Boolean. Jeśli masz dane, które muszą być przechowywane jako typ danych bitowych, użyj zapytań z funkcją T-SQL CAST lub KONWERTUJ.
Właściwości czynności wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie wyszukiwania.
Właściwości działania GetMetadata
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie GetMetadata
Korzystanie z funkcji Always Encrypted
Podczas kopiowania danych z/do SQL Server za pomocą Always Encrypted wykonaj następujące kroki:
Zapisz klucz główny kolumny (CMK) w usłudze Azure Key Vault. Dowiedz się więcej na temat Jak skonfigurować funkcję Always Encrypted przy użyciu Azure Key Vault
Upewnij się, że udzielono dostępu do magazynu kluczy, w którym jest przechowywany klucz główny kolumny (CMK ). Zapoznaj się z tym artykułem , aby uzyskać wymagane uprawnienia.
Utwórz połączoną usługę w celu nawiązania połączenia z bazą danych SQL i włącz funkcję "Always Encrypted" przy użyciu tożsamości zarządzanej lub jednostki usługi.
Uwaga
SQL Server Always Encrypted obsługuje poniższe scenariusze:
- Magazyny danych źródła lub ujścia używają tożsamości zarządzanej lub jednostki usługi jako typu uwierzytelniania dostawcy kluczy.
- Magazyny danych źródła i ujścia używają tożsamości zarządzanej jako rodzaju uwierzytelniania dostawcy kluczy.
- Magazyny danych źródła i ujścia używają tej samej jednostki głównej usługi jako typu uwierzytelnienia dostawcy kluczy.
Uwaga
Obecnie SQL Server Always Encrypted jest obsługiwany tylko w przypadku transformacji źródła w mapowaniach przepływów danych.
Natywne przechwytywanie zmian danych
Azure Data Factory może obsługiwać natywne funkcje przechwytywania danych zmian dla SQL Server, Azure SQL DB i Azure SQL MI. Zmienione dane, w tym wstawianie wierszy, aktualizowanie i usuwanie w magazynach SQL, można automatycznie wykrywać i wyodrębniać przez przepływ danych mapowania usługi ADF. Dzięki bezkodowemu doświadczeniu w mapowaniu przepływu danych, użytkownicy mogą łatwo zrealizować scenariusz replikacji danych z magazynów SQL, dodając bazę danych jako magazyn docelowy. Co więcej, użytkownicy mogą również tworzyć dowolną logikę przekształcania danych między operacjami, aby osiągnąć przyrostowy scenariusz ETL z repozytoriów SQL.
Upewnij się, że nazwy pipeline'u i działań pozostają niezmienione, aby punkty kontrolne mogły być rejestrowane przez usługę ADF w celu automatycznego pobierania zmienionych danych z ostatniego uruchomienia. Jeśli zmienisz nazwę pipeline'u lub nazwę działania, punkt kontrolny zostanie zresetowany, co oznacza, że będziesz musiał rozpocząć od początku lub uwzględnić zmiany od momentu kolejne uruchomienie. Jeśli chcesz zmienić nazwę kolejki lub nazwę działania, ale chcesz zachować punkt kontrolny, aby automatycznie uzyskiwać dane zmienione podczas ostatniego uruchomienia, użyj własnego klucza punktu kontrolnego w działaniu przepływu danych, aby to osiągnąć.
Podczas debugowania potoku ta funkcja działa tak samo. Pamiętaj, że punkt kontrolny zostanie zresetowany podczas odświeżania przeglądarki podczas uruchamiania debugowania. Po zadowoleniu z wyniku pipeline z działania debugowania, możesz przystąpić do opublikowania i uruchomienia pipeline. W chwili, gdy pierwszy raz uruchamiasz opublikowany potok, automatycznie zaczyna się od początku lub wprowadza zmiany od tej chwili.
W sekcji monitorowania zawsze masz możliwość ponownego uruchomienia potoku. Podczas wykonywania tych czynności zmienione dane są zawsze przechwytywane z poprzedniego punktu kontrolnego wybranego przebiegu potoku.
Przykład 1:
Jeśli bezpośrednio połączysz przekształcenie źródłowe, odwołując się do zestawu danych z włączoną funkcją SQL CDC, z przekształceniem docelowym, które odnosi się do bazy danych w przepływie danych mapowanych, zmiany wprowadzone w źródle SQL zostaną automatycznie zastosowane do docelowej bazy danych, w ten sposób łatwo uzyskasz scenariusz replikacji danych między bazami danych. Możesz użyć metody update w transformacji wyjściowej, aby wybrać, czy chcesz zezwolić na wstawianie, zezwolić na aktualizację lub zezwolić na usuwanie w docelowej bazie danych. Przykładowy skrypt w mapowaniu przepływu danych jest następujący.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Przykład 2:
Jeśli chcesz włączyć scenariusz ETL zamiast replikacji danych między bazami danych za pomocą SQL CDC, możesz użyć wyrażeń isInsert(1), isUpdate(1) i isDelete(1) w przepływie danych w mapowaniu, aby odróżnić wiersze z różnymi typami operacji. Poniżej przedstawiono jeden z przykładowych skryptów do mapowania przepływu danych, który wyprowadza jedną kolumnę z wartością: 1 - aby wskazać wstawione wiersze, 2 - aby wskazać zaktualizowane wiersze, i 3 - aby wskazać usunięte wiersze dla dalszych przekształceń w procesie przetwarzania danych różnicowych.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Znane ograniczenie:
- Tylko zmiany netto z systemu CDC SQL zostaną załadowane przez system ADF za pośrednictwem cdc.fn_cdc_get_net_changes_.
Rozwiązywanie problemów z połączeniem
Skonfiguruj wystąpienie SQL Server do akceptowania połączeń zdalnych. Uruchom SQL Server Management Studio kliknij prawym przyciskiem myszy server i wybierz Właściwości. Wybierz pozycję Połączenia z listy, a następnie zaznacz pole wyboru Zezwalaj na połączenia zdalne z tym serwerem .
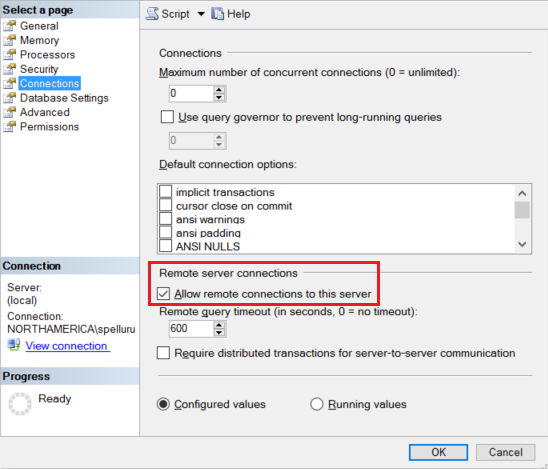
Aby uzyskać szczegółowe instrukcje, zobacz Konfigurowanie opcji konfiguracji serwera dostępu zdalnego.
Uruchom SQL Server Configuration Manager. Rozwiń węzeł Konfiguracja sieci SQL Servera dla żądanego wystąpienia i wybierz Protokoły dla MSSQLSERVER. Protokoły są wyświetlane w okienku po prawej stronie. Włącz protokół TCP/IP, klikając prawym przyciskiem myszy tcp /IP i wybierając pozycję Włącz.
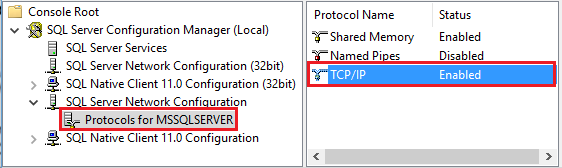
Aby uzyskać więcej informacji i alternatywne sposoby włączania protokołu TCP/IP, zobacz Włączanie lub wyłączanie protokołu sieciowego serwera.
W tym samym oknie kliknij dwukrotnie TCP/IP, aby uruchomić okno Właściwości TCP/IP.
Przejdź do karty IP Addresses. Przewiń w dół, aby zobaczyć sekcję IPAll. Zanotuj port TCP. Wartość domyślna to 1433.
Utwórz na maszynie zasadę zapory Windows, aby zezwolić na ruch przychodzący przez ten port.
Sprawdź połączenie: Aby nawiązać połączenie z SQL Server przy użyciu w pełni kwalifikowanej nazwy, użyj SQL Server Management Studio na innym komputerze. Może to być na przykład
"<machine>.<domain>.corp.<company>.com,1433".
Uaktualnianie wersji SQL Server
Aby uaktualnić wersję SQL Server, na stronie Edytuj połączoną usługę wybierz Recommended w obszarze Version i skonfiguruj połączoną usługę, odwołując się do właściwości usługi Linked dla zalecanej wersji.
Różnice między zalecaną i starszą wersją
W poniższej tabeli przedstawiono różnice między SQL Server przy użyciu zalecanej i starszej wersji.
| Rekomendowana wersja | Starsza wersja |
|---|---|
Obsługuj TLS 1.3 za pośrednictwem encrypt jako strict. |
Protokół TLS 1.3 nie jest obsługiwany. |
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz Obsługiwane magazyny danych.