Vektorlagring i Azure AI Search
Azure AI Search tillhandahåller vektorlagring och konfigurationer för vektorsökning och hybridsökning. Stöd implementeras på fältnivå, vilket innebär att du kan kombinera vektor- och icke-vektorfält i samma sökkorus.
Vektorer lagras i ett sökindex. Använd rest-API:et Skapa index eller en motsvarande Azure SDK-metod för att skapa vektorarkivet.
Överväganden för vektorlagring omfattar följande punkter:
- Utforma ett schema som passar ditt användningsfall baserat på det avsedda vektorhämtningsmönstret.
- Beräkna indexstorleken och kontrollera söktjänstens kapacitet.
- Hantera ett vektorlager
- Skydda ett vektorlager
I Azure AI Search finns det två mönster för att arbeta med sökresultat.
Generativ sökning. Språkmodeller formulerar ett svar på användarens fråga med hjälp av data från Azure AI Search. Det här mönstret innehåller ett orkestreringslager för att samordna frågor och underhålla kontexten. I det här mönstret matas sökresultaten in i promptflöden som tas emot av chattmodeller som GPT och Text-Davinci. Den här metoden baseras på RAG-arkitekturen (Retrieval augmented generation), där sökindexet tillhandahåller grunddata.
Klassisk sökning med hjälp av ett sökfält, frågeindatasträng och renderade resultat. Sökmotorn accepterar och kör vektorfrågan, formulerar ett svar och du renderar dessa resultat i en klientapp. I Azure AI Search returneras resultaten i en utplattad raduppsättning och du kan välja vilka fält som ska innehålla sökresultat. Eftersom det inte finns någon chattmodell förväntas du fylla i vektorarkivet (sökindex) med icke-bevektorinnehåll som är läsbart i ditt svar. Även om sökmotorn matchar vektorer bör du använda icke-bevektorvärden för att fylla i sökresultaten. Vektorfrågor och hybridfrågor omfattar de typer av frågebegäranden som du kan formulera för klassiska sökscenarier.
Indexschemat bör återspegla ditt primära användningsfall. I följande avsnitt beskrivs skillnaderna i fältsammansättning för lösningar som skapats för generativ AI eller klassisk sökning.
Ett indexschema för ett vektorlager kräver ett namn, ett nyckelfält (sträng), ett eller flera vektorfält och en vektorkonfiguration. Icke-bevektorfält rekommenderas för hybridfrågor eller för att returnera ordagrant mänskligt läsbart innehåll som inte behöver gå igenom en språkmodell. Anvisningar om vektorkonfiguration finns i Skapa ett vektorlager.
Vektorfält särskiljs av deras datatyp och vektorspecifika egenskaper. Så här ser ett vektorfält ut i en fältsamling:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Vektorfält har specifika datatyper. Collection(Edm.Single) För närvarande är det vanligaste, men att använda smala datatyper kan spara på lagringen.
Vektorfält måste vara sökbara och hämtningsbara, men de kan inte vara filterbara, fasettbara eller sorterbara, eller ha analysverktyg, normaliserare eller synonymmappningstilldelningar.
Vektorfält måste ha dimensions angetts till antalet inbäddningar som genereras av inbäddningsmodellen. Text-embedding-ada-002 genererar till exempel 1 536 inbäddningar för varje textsegment.
Vektorfält indexeras med hjälp av algoritmer som anges av en vektorsökningsprofil, som definieras någon annanstans i indexet och därför inte visas i exemplet. Mer information finns i konfiguration av vektorsökning.
Vektorlager kräver fler fält förutom vektorfält. Ett nyckelfält ("id" i det här exemplet) är till exempel ett indexkrav.
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Andra fält, till exempel fältet "content" , anger den mänskliga läsbara motsvarigheten till "content_vector" fältet. Om du använder språkmodeller uteslutande för svarsformulering kan du utelämna icke-bevektorinnehållsfält, men lösningar som skickar sökresultat direkt till klientappar bör ha icke-bevektorinnehåll.
Metadatafält är användbara för filter, särskilt om metadata innehåller ursprungsinformation om källdokumentet. Du kan inte filtrera på ett vektorfält direkt, men du kan ange förfilter- eller postfilterlägen för att filtrera före eller efter körning av vektorfrågor.
Vi rekommenderar guiden Importera och vektorisera data för utvärderings- och koncepttestning. Guiden genererar exempelschemat i det här avsnittet.
Det här schemats bias är att sökdokument bygger på datasegment. Om en språkmodell formulerar svaret, vilket är typiskt för RAG-appar, vill du ha ett schema som är utformat kring datasegment.
Datasegmentering är nödvändigt för att hålla sig inom indatagränserna för språkmodeller, men det förbättrar också precisionen i likhetssökningen när frågor kan matchas mot mindre delar av innehåll som hämtas från flera överordnade dokument. Om du använder semantisk ranker har semantisk rankning även tokengränser, som är enklare att uppfylla om datasegmentering ingår i din metod.
I följande exempel finns det ett segment-ID, segment, rubrik och vektorfält för varje sökdokument. ChunkID och överordnat ID fylls i av guiden med bas 64-kodning av blobmetadata (sökväg). Segment och rubrik härleds från blobinnehåll och blobnamn. Endast vektorfältet genereras helt. Det är den vektoriserade versionen av segmentfältet. Inbäddningar genereras genom att anropa en Inbäddningsmodell för Azure OpenAI som du anger.
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Om du utformar lagring för generativ sökning kan du skapa separata index för det statiska innehåll som du indexerade och vektoriserade och ett andra index för konversationer som kan användas i promptflöden. Följande index skapas från acceleratorn chat-with-your-data-solution-accelerator.
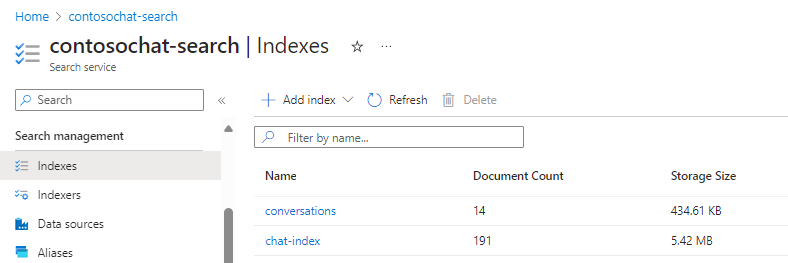
Fält från chattindexet som stöder generativ sökupplevelse:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Fält från konversationsindexet som stöder orkestrerings- och chatthistorik:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
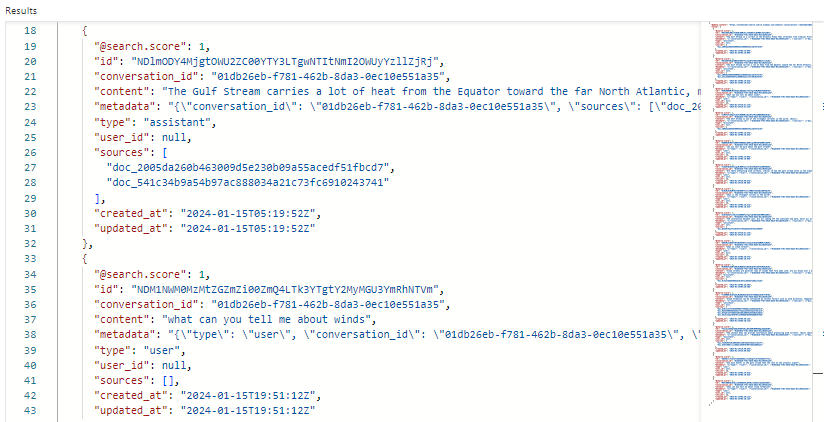
Här är en skärmbild som visar sökresultat i Sökutforskaren för konversationsindexet. Sökpoängen är 1,00 eftersom sökningen var okvalificerad. Observera de fält som finns för orkestrering och promptflöden. Ett konversations-ID identifierar en specifik chatt. "type" anger om innehållet kommer från användaren eller assistenten. Datum används för att åldra ut chattar från historiken.
I Azure AI Search är den fysiska strukturen för ett index till stor del en intern implementering. Du kan komma åt dess schema, läsa in och fråga dess innehåll, övervaka dess storlek och hantera kapacitet, men själva klustren (inverterade index och vektorindex) och andra filer och mappar hanteras internt av Microsoft.
Indexets storlek och ämne bestäms av:
- Kvantitet och sammansättning av dina dokument
- Attribut för enskilda fält. Det krävs till exempel mer lagringsutrymme för filterbara fält.
- Indexkonfiguration, inklusive vektorkonfiguration som anger hur de interna navigeringsstrukturerna skapas baserat på om du väljer HNSW eller fullständig KNN för likhetssökning.
Azure AI Search begränsar vektorlagring, vilket hjälper till att upprätthålla ett balanserat och stabilt system för alla arbetsbelastningar. För att hjälpa dig att hålla dig under gränserna spåras vektoranvändningen och rapporteras separat i Azure Portal och programmatiskt via tjänst- och indexstatistik.
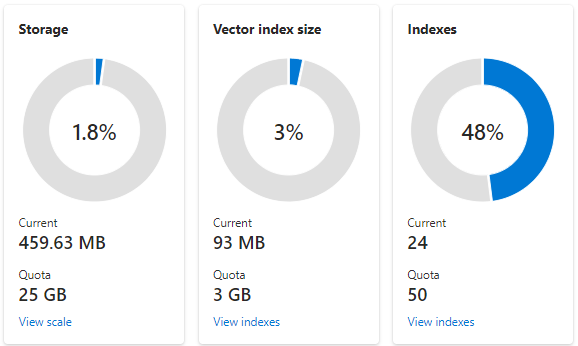
Följande skärmbild visar en S1-tjänst som konfigurerats med en partition och en replik. Den här tjänsten har 24 små index, med ett vektorfält i genomsnitt, där varje fält består av 1 536 inbäddningar. Den andra panelen visar kvoten och användningen för vektorindex. Ett vektorindex är en intern datastruktur som skapats för varje vektorfält. Därför är lagring för vektorindex alltid en bråkdel av den lagring som används av indexet överlag. Andra icke-bevektorfält och datastrukturer förbrukar resten.
Vektorindexgränser och uppskattningar beskrivs i en annan artikel, men två punkter att betona i förväg är att maximal lagring varierar beroende på tjänstnivå och även när söktjänsten skapades. Nyare tjänster på samma nivå har betydligt mer kapacitet för vektorindex. Av dessa skäl vidtar du följande åtgärder:
Kontrollera distributionsdatumet för söktjänsten. Om den skapades före den 3 april 2024 bör du överväga att skapa en ny söktjänst för större kapacitet.
Välj en skalbar nivå om du förväntar dig variationer i kraven på vektorlagring. Basic-nivån är fast vid en partition i äldre söktjänster. Överväg Standard 1 (S1) och senare för mer flexibilitet och snabbare prestanda, eller skapa en ny söktjänst som använder högre gränser och fler partitioner på varje nillabel nivå.
I det här avsnittet beskrivs vektorkörningsåtgärder, inklusive anslutning till och skydd av ett enda index.
Anteckning
När du hanterar ett index bör du vara medveten om att det inte finns något portal- eller API-stöd för att flytta eller kopiera ett index. I stället pekar kunderna vanligtvis sin programdistributionslösning på en annan söktjänst (om de använder samma indexnamn) eller ändrar namnet för att skapa en kopia på den aktuella söktjänsten och skapar den sedan.
Ett index är omedelbart tillgängligt för frågor så snart det första dokumentet indexeras, men kommer inte att fungera fullt ut förrän alla dokument har indexerats. Internt distribueras ett index mellan partitioner och körs på repliker. Det fysiska indexet hanteras internt. Det logiska indexet hanteras av dig.
Ett index är kontinuerligt tillgängligt, utan möjlighet att pausa eller ta det offline. Eftersom det är utformat för kontinuerlig drift sker alla uppdateringar av innehållet eller tillägg till själva indexet i realtid. Därför kan frågor tillfälligt returnera ofullständiga resultat om en begäran sammanfaller med en dokumentuppdatering.
Observera att frågekontinuitet finns för dokumentåtgärder (uppdatering eller borttagning) och för ändringar som inte påverkar den befintliga strukturen och integriteten för det aktuella indexet (till exempel att lägga till nya fält). Om du behöver göra strukturella uppdateringar (ändra befintliga fält) hanteras de vanligtvis med hjälp av ett drop-and-rebuild-arbetsflöde i en utvecklingsmiljö eller genom att skapa en ny version av indexet för produktionstjänsten.
För att undvika att index återskapas väljer vissa kunder som gör små ändringar att "version" ett fält genom att skapa ett nytt som samexisterar tillsammans med en tidigare version. Med tiden leder detta till överblivet innehåll i form av föråldrade fält eller föråldrade anpassade analysverktygsdefinitioner, särskilt i ett produktionsindex som är dyrt att replikera. Du kan åtgärda dessa problem vid planerade uppdateringar av indexet som en del av indexets livscykelhantering.
Alla vektorindexerings- och frågebegäranden riktar sig mot ett index. Slutpunkter är vanligtvis en av följande:
| Slutpunkt | Anslutning och åtkomstkontroll |
|---|---|
<your-service>.search.windows.net/indexes |
Riktar sig till indexsamlingen. Används när du skapar, listar eller tar bort ett index. Administratörsrättigheter krävs för dessa åtgärder, tillgängliga via administratörs-API-nycklar eller en sökdeltagareroll. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Riktar in sig på dokumentsamlingen för ett enda index. Används när du kör frågor mot ett index eller en datauppdatering. För frågor är läsbehörigheter tillräckliga och tillgängliga via fråge-API-nycklar eller en dataläsarroll. För datauppdatering krävs administratörsbehörighet. |
Kontrollera att du har behörigheter eller en API-åtkomstnyckel. Om du inte kör frågor mot ett befintligt index behöver du administratörsrättigheter eller en rolltilldelning för deltagare för att hantera och visa innehåll i en söktjänst.
Börja med Azure Portal. Den person som skapade söktjänsten kan visa och hantera söktjänsten, inklusive att ge åtkomst till andra via sidan Åtkomstkontroll (IAM).
Gå vidare till andra klienter för programmatisk åtkomst. Vi rekommenderar snabbstarter och exempel för de första stegen:
Azure AI Search implementerar datakryptering, privata anslutningar för scenarier utan Internet och rolltilldelningar för säker åtkomst via Microsoft Entra-ID. Alla säkerhetsfunktioner för företag beskrivs i Säkerhet i Azure AI Search.
Azure tillhandahåller en övervakningsplattform som innehåller diagnostikloggning och aviseringar. Vi rekommenderar följande metodtips: