Partycjonowanie w usłudze Azure Cosmos DB dla bazy danych Apache Cassandra
DOTYCZY: ![]() Kasandra
Kasandra
W tym artykule opisano sposób działania partycjonowania w usłudze Azure Cosmos DB dla bazy danych Apache Cassandra.
Interfejs API dla rozwiązania Cassandra używa partycjonowania do skalowania poszczególnych tabel w przestrzeni kluczy w celu spełnienia wymagań dotyczących wydajności aplikacji. Partycje są tworzone na podstawie wartości klucza partycji skojarzonego z każdym rekordem w tabeli. Wszystkie rekordy w partycji mają tę samą wartość klucza partycji. Usługa Azure Cosmos DB w sposób przezroczysty i automatycznie zarządza umieszczaniem partycji w zasobach fizycznych, aby efektywnie zaspokoić potrzeby dotyczące skalowalności i wydajności tabeli. Wraz ze wzrostem przepływności i wymagań dotyczących magazynu aplikacji usługa Azure Cosmos DB przenosi i równoważy dane na większej liczbie maszyn fizycznych.
Z perspektywy dewelopera partycjonowanie działa w taki sam sposób, jak w przypadku usługi Azure Cosmos DB dla systemu Apache Cassandra, co w natywnej bazie danych Apache Cassandra. Istnieją jednak pewne różnice w tle.
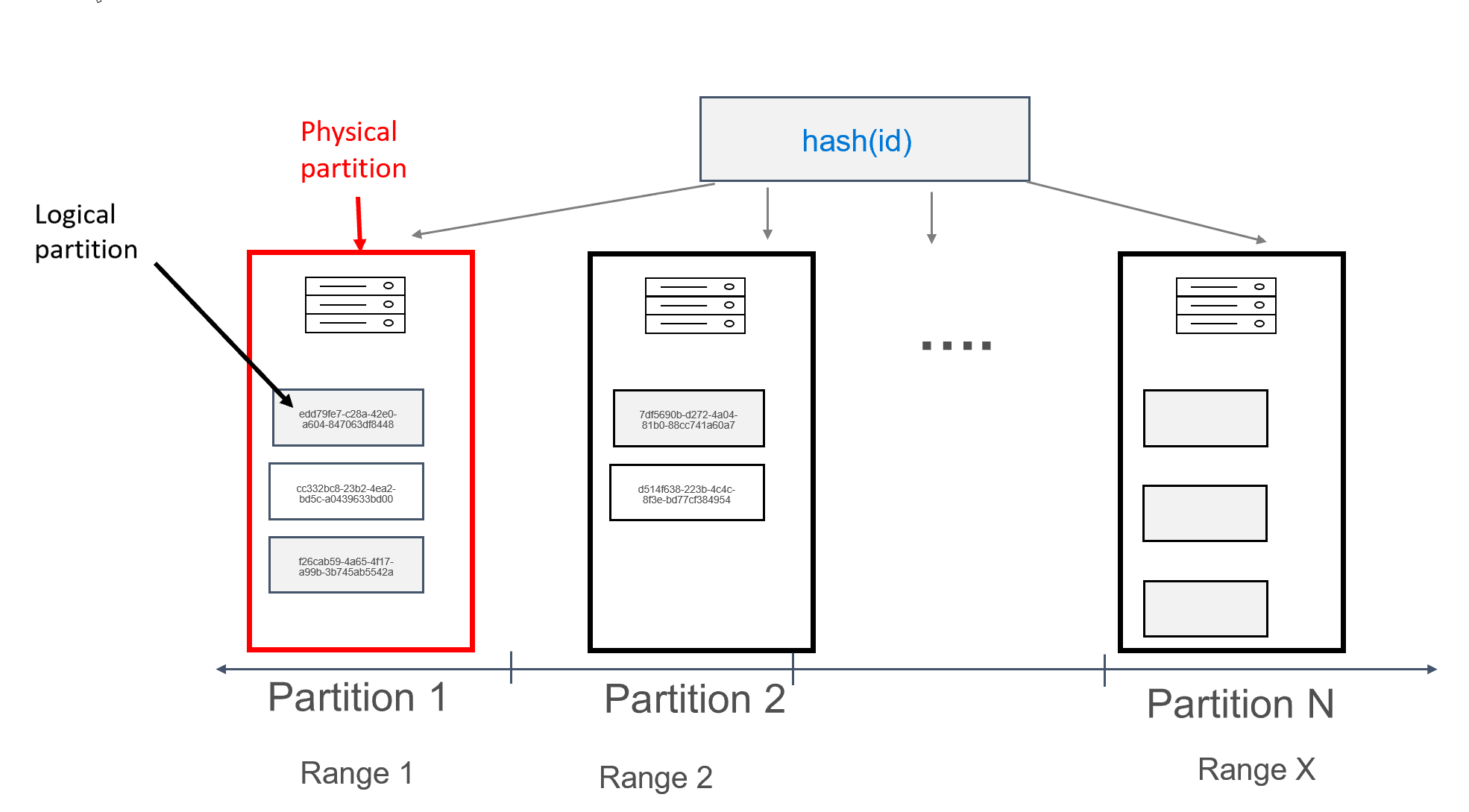
W usłudze Azure Cosmos DB każda maszyna, na której są przechowywane partycje, jest sama określana jako partycja fizyczna. Partycja fizyczna jest wyrównywana do maszyny wirtualnej; dedykowana jednostka obliczeniowa lub zestaw zasobów fizycznych. Każda partycja przechowywana w tej jednostce obliczeniowej jest nazywana partycją logiczną w usłudze Azure Cosmos DB. Jeśli znasz już usługę Apache Cassandra, możesz myśleć o partycjach logicznych w taki sam sposób, jak w przypadku zwykłych partycji w systemie Cassandra.
Apache Cassandra zaleca limit 100 MB na rozmiar danych, które mogą być przechowywane w partycji. Interfejs API dla bazy danych Cassandra dla usługi Azure Cosmos DB umożliwia maksymalnie 20 GB na partycję logiczną i do 30 GB danych na partycję fizyczną. W usłudze Azure Cosmos DB, w przeciwieństwie do bazy danych Apache Cassandra, pojemność obliczeniowa dostępna w partycji fizycznej jest wyrażana przy użyciu jednej metryki nazywanej jednostkami żądań, co pozwala myśleć o obciążeniu pod względem żądań (odczytów lub zapisów) na sekundę, a nie rdzeni, pamięci lub liczby operacji we/wy na sekundę. Może to sprawić, że planowanie pojemności będzie bardziej proste, gdy zrozumiesz koszt każdego żądania. Każda partycja fizyczna może mieć do 10000 jednostek RU zasobów obliczeniowych dostępnych. Aby dowiedzieć się więcej na temat opcji skalowalności, przeczytaj nasz artykuł dotyczący elastycznej skali w interfejsie API dla rozwiązania Cassandra.
W usłudze Azure Cosmos DB każda partycja fizyczna składa się z zestawu replik, nazywanych również zestawami replik, z co najmniej 4 replikami na partycję. Jest to w przeciwieństwie do bazy danych Apache Cassandra, gdzie ustawienie współczynnika replikacji 1 jest możliwe. Jednak prowadzi to do niskiej dostępności, jeśli tylko węzeł z danymi ulegnie awarii. W interfejsie API dla bazy danych Cassandra zawsze występuje współczynnik replikacji 4 (kworum 3). Usługa Azure Cosmos DB automatycznie zarządza zestawami replik, a te muszą być obsługiwane przy użyciu różnych narzędzi w systemie Apache Cassandra.
Apache Cassandra ma pojęcie tokenów, które są skrótami kluczy partycji. Tokeny są oparte na szmur3 64 bajtowy skrót, z wartościami od -2^63 do -2^63 - 1. Ten zakres jest często określany jako "pierścień tokenu" w systemie Apache Cassandra. Pierścień tokenu jest dystrybuowany do zakresów tokenów, a te zakresy są podzielone między węzły obecne w natywnym klastrze Apache Cassandra. Partycjonowanie dla usługi Azure Cosmos DB jest implementowane w podobny sposób, z wyjątkiem innego algorytmu skrótu i ma większy wewnętrzny pierścień tokenu. Jednak zewnętrznie uwidaczniamy ten sam zakres tokenów co apache Cassandra, tj. -2^63 do -2^63 - 1.
Wszystkie tabele w interfejsie API dla bazy danych Cassandra muszą mieć zdefiniowaną definicję primary key . Poniżej przedstawiono składnię klucza podstawowego:
column_name cql_type_definition PRIMARY KEY
Załóżmy, że chcemy utworzyć tabelę użytkowników, która przechowuje komunikaty dla różnych użytkowników:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
W tym projekcie zdefiniowaliśmy id pole jako klucz podstawowy. Klucz podstawowy pełni rolę identyfikatora rekordu w tabeli i jest również używany jako klucz partycji w usłudze Azure Cosmos DB. Jeśli klucz podstawowy jest zdefiniowany w opisany wcześniej sposób, w każdej partycji będzie znajdować się tylko jeden rekord. Spowoduje to idealnie poziomą i skalowalną dystrybucję podczas zapisywania danych w bazie danych i jest idealnym rozwiązaniem w przypadku przypadków użycia wyszukiwania klucz-wartość. Aplikacja powinna podać klucz podstawowy za każdym razem, gdy odczytuje dane z tabeli, aby zmaksymalizować wydajność odczytu.
Apache Cassandra ma również pojęcie .compound keys Związek primary key składa się z więcej niż jednej kolumny; pierwsza kolumna to partition key, a wszystkie dodatkowe kolumny to clustering keys. Składnia elementu jest compound primary key pokazana poniżej:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Załóżmy, że chcemy zmienić powyższy projekt i umożliwić wydajne pobieranie komunikatów dla danego użytkownika:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
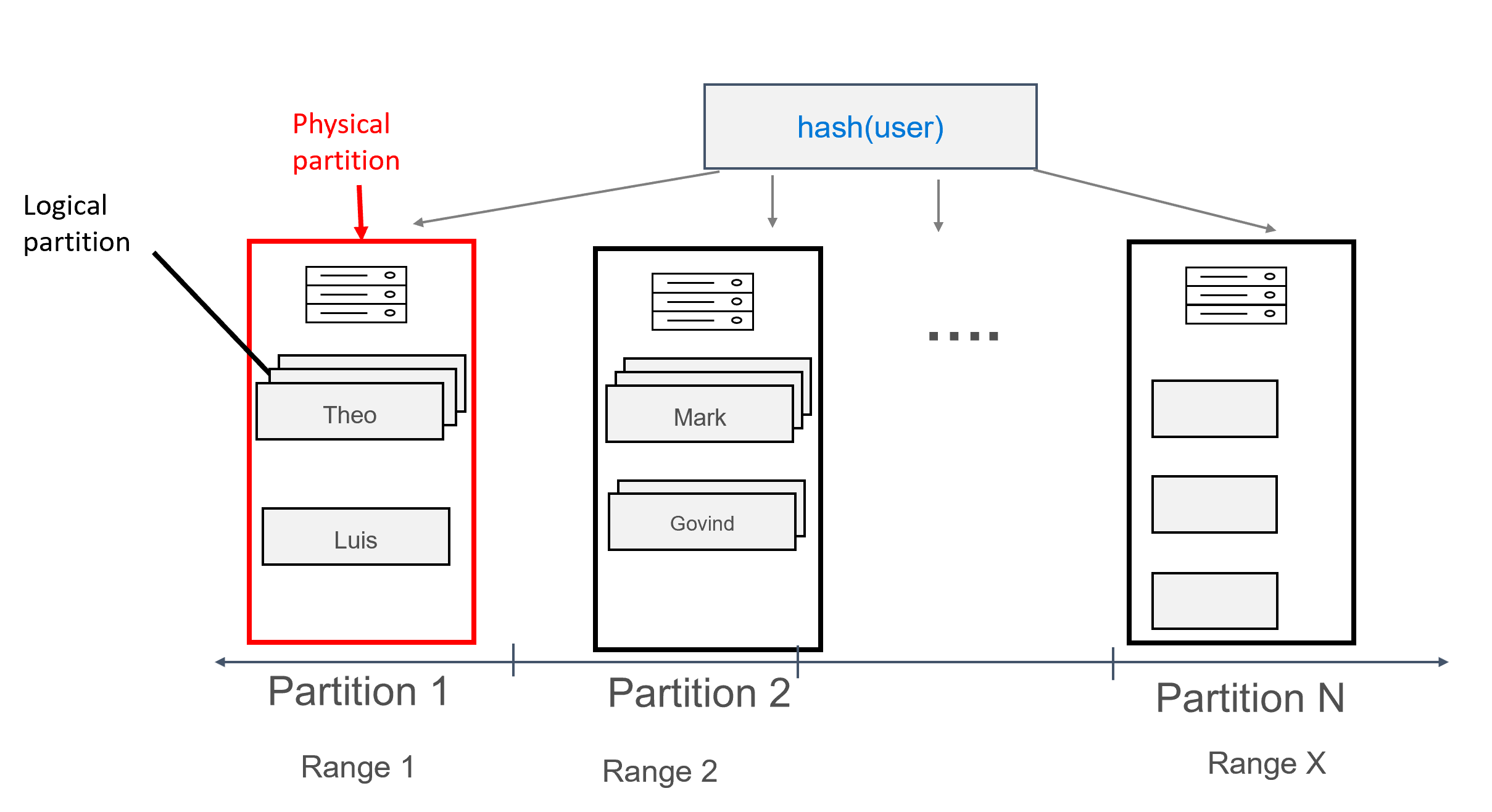
W tym projekcie definiujemy user teraz jako klucz partycji i id jako klucz klastrowania. Można zdefiniować dowolną liczbę kluczy klastrowania, ale każda wartość (lub kombinacja wartości) dla klucza klastrowania musi być unikatowa, aby spowodować dodanie wielu rekordów do tej samej partycji, na przykład:
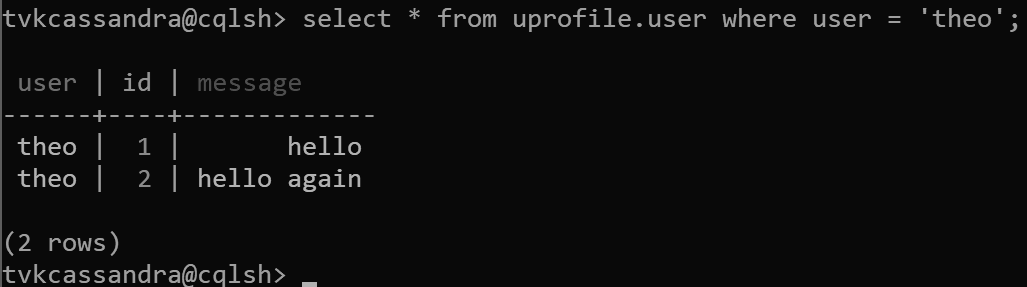
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Gdy dane są zwracane, są sortowane według klucza klastrowania zgodnie z oczekiwaniami w usłudze Apache Cassandra:
Ostrzeżenie
Podczas wykonywania zapytań dotyczących danych w tabeli zawierającej złożony klucz podstawowy, jeśli chcesz filtrować klucz partycji i inne pola nieindeksowane oprócz klucza klastrowania, upewnij się, że jawnie dodano indeks pomocniczy w kluczu partycji:
CREATE INDEX ON uprofile.user (user);
Usługa Azure Cosmos DB dla systemu Apache Cassandra domyślnie nie stosuje indeksów do kluczy partycji, a indeks w tym scenariuszu może znacznie poprawić wydajność zapytań. Aby uzyskać więcej informacji, zapoznaj się z naszym artykułem dotyczącym indeksowania pomocniczego .
Dzięki modelowaniu danych można przypisać wiele rekordów do każdej partycji pogrupowanej według użytkownika. W związku z tym możemy wydać zapytanie, które jest efektywnie kierowane przez partition key element (w tym przypadku user), aby pobrać wszystkie komunikaty dla danego użytkownika.
Klucze partycji złożonej działają zasadniczo tak samo jak klucze złożone, z tą różnicą, że można określić wiele kolumn jako klucz partycji złożonej. Poniżej przedstawiono składnię kluczy partycji złożonych:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Na przykład możesz mieć następujące elementy, w których unikatowa kombinacja firstname i lastname tworzy klucz partycji i id jest kluczem klastrowania:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
- Dowiedz się więcej o partycjonowaniu i skalowaniu w poziomie w usłudze Azure Cosmos DB.
- Dowiedz się więcej o aprowizowanej przepływności w usłudze Azure Cosmos DB.
- Dowiedz się więcej o dystrybucji globalnej w usłudze Azure Cosmos DB.