Bezpieczne zarządzanie środowiskiem Python w usłudze Azure HDInsight za pomocą akcji skryptu
Usługa HDInsight ma dwie wbudowane instalacje języka Python w klastrze Spark: Anaconda Python 2.7 i Python 3.5. Klienci mogą wymagać dostosowania środowiska języka Python, takiego jak instalowanie zewnętrznych pakietów języka Python. W tym miejscu przedstawiono najlepsze rozwiązanie w zakresie bezpiecznego zarządzania środowiskami języka Python dla klastrów Apache Spark w usłudze HDInsight.
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight. Jeśli nie masz jeszcze klastra Spark w usłudze HDInsight, możesz uruchomić akcje skryptu podczas tworzenia klastra. Zapoznaj się z dokumentacją dotyczącą używania niestandardowych akcji skryptu.
Usługa Microsoft Azure HDInsight korzysta ze środowiska technologii open source utworzonych wokół platformy Apache Hadoop. Platforma Microsoft Azure zapewnia ogólny poziom obsługi technologii open source. Aby uzyskać więcej informacji, zobacz witrynę internetową Azure Support FAQ (Często zadawane pytania dotyczące pomocy technicznej platformy Azure). Usługa HDInsight zapewnia dodatkowy poziom obsługi wbudowanych składników.
Istnieją dwa typy składników typu open source, które są dostępne w usłudze HDInsight:
| Składnik | opis |
|---|---|
| Wbudowana | Te składniki są wstępnie zainstalowane w klastrach usługi HDInsight i zapewniają podstawowe funkcje klastra. Na przykład usługa Apache Hadoop YARN Resource Manager, język zapytań Apache Hive (HiveQL) i biblioteka Mahout należą do tej kategorii. Pełna lista składników klastra jest dostępna w artykule Co nowego w wersjach klastra Apache Hadoop udostępnianych przez usługę HDInsight. |
| Niestandardowy | Jako użytkownik klastra możesz zainstalować lub użyć w obciążeniu dowolnego składnika dostępnego w społeczności lub utworzonego przez Ciebie. |
Ważne
Składniki dostarczane z klastrem usługi HDInsight są w pełni obsługiwane. pomoc techniczna firmy Microsoft pomaga odizolować i rozwiązać problemy związane z tymi składnikami.
Składniki niestandardowe otrzymują rozsądną komercyjnie pomoc techniczną, aby ułatwić dalsze rozwiązywanie problemu. Pomoc techniczna firmy Microsoft może być w stanie rozwiązać ten problem LUB może poprosić Cię o angażowanie dostępnych kanałów dla technologii open source, w których znaleziono głęboką wiedzę dotyczącą tej technologii. Na przykład istnieje wiele witryn społeczności, których można używać, takich jak: strona pytań i odpowiedzi firmy Microsoft dla usługi HDInsight, https://stackoverflow.com. Ponadto projekty Apache mają witryny projektów w witrynach https://apache.org.
Klastry HDInsight Spark mają zainstalowaną platformę Anaconda. Istnieją dwie instalacje języka Python w klastrze: Anaconda Python 2.7 i Python 3.5. W poniższej tabeli przedstawiono domyślne ustawienia języka Python dla platform Spark, Livy i Jupyter.
| Ustawienie | Python 2.7 | Python 3.5 |
|---|---|---|
| Ścieżka | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Wersja platformy Spark | Wartość domyślna ustawiona na 2.7 | Może zmienić konfigurację na 3.5 |
| Wersja usługi Livy | Wartość domyślna ustawiona na 2.7 | Może zmienić konfigurację na 3.5 |
| Jupyter | Jądro PySpark | Jądro PySpark3 |
W przypadku wersji Spark 3.1.2 jądro Apache PySpark zostanie usunięte, a nowe środowisko języka Python 3.8 jest zainstalowane w systemie /usr/bin/miniforge/envs/py38/bin, który jest używany przez jądro PySpark3. Zmienne PYSPARK_PYTHON środowiskowe i PYSPARK3_PYTHON są aktualizowane przy użyciu następujących elementów:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
Klaster usługi HDInsight zależy od wbudowanego środowiska języka Python, zarówno python 2.7, jak i Python 3.5. Bezpośrednie instalowanie pakietów niestandardowych w tych domyślnych środowiskach wbudowanych może spowodować nieoczekiwane zmiany wersji biblioteki. I przerwij klaster dalej. Aby bezpiecznie zainstalować niestandardowe zewnętrzne pakiety języka Python dla aplikacji Platformy Spark, wykonaj kroki.
Tworzenie środowiska wirtualnego języka Python przy użyciu środowiska conda. Środowisko wirtualne zapewnia izolowane miejsce dla projektów bez przerywania pracy innych. Podczas tworzenia środowiska wirtualnego języka Python możesz określić wersję języka Python, której chcesz użyć. Nadal musisz utworzyć środowisko wirtualne, mimo że chcesz używać języków Python 2.7 i 3.5. To wymaganie polega na upewnieniu się, że domyślne środowisko klastra nie jest przerywane. Uruchom akcje skryptu w klastrze dla wszystkich węzłów z następującym skryptem, aby utworzyć środowisko wirtualne języka Python.
--prefixokreśla ścieżkę, w której znajduje się środowisko wirtualne conda. Istnieje kilka konfiguracji, które należy zmienić dalej w oparciu o ścieżkę określoną tutaj. W tym przykładzie używamy narzędzia py35new, ponieważ klaster ma już istniejące środowisko wirtualne o nazwie py35.python=określa wersję języka Python dla środowiska wirtualnego. W tym przykładzie używamy wersji 3.5, takiej samej jak w przypadku klastra wbudowanego w jeden. Możesz również użyć innych wersji języka Python do utworzenia środowiska wirtualnego.anacondaokreśla package_spec jako anaconda do instalowania pakietów Anaconda w środowisku wirtualnym.
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yesW razie potrzeby zainstaluj zewnętrzne pakiety języka Python w utworzonym środowisku wirtualnym. Uruchom akcje skryptu w klastrze dla wszystkich węzłów z następującym skryptem, aby zainstalować zewnętrzne pakiety języka Python. Musisz mieć uprawnienia sudo tutaj, aby zapisywać pliki w folderze środowiska wirtualnego.
Przeszukaj indeks pakietu, aby uzyskać pełną listę dostępnych pakietów. Możesz również uzyskać listę dostępnych pakietów z innych źródeł. Można na przykład zainstalować pakiety udostępnione za pośrednictwem narzędzia conda-forge.
Użyj następującego polecenia, jeśli chcesz zainstalować bibliotekę z najnowszą wersją:
Użyj kanału conda:
seabornto nazwa pakietu, którą chcesz zainstalować.-n py35newokreśl nazwę środowiska wirtualnego, które właśnie zostanie utworzone. Pamiętaj, aby zmienić nazwę odpowiednio na podstawie tworzenia środowiska wirtualnego.
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesMożesz też użyć repozytorium PyPi, zmienić
seabornipy35newodpowiednio:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
Użyj następującego polecenia, jeśli chcesz zainstalować bibliotekę z określoną wersją:
Użyj kanału conda:
numpy=1.16.1to nazwa pakietu i wersja, którą chcesz zainstalować.-n py35newokreśl nazwę środowiska wirtualnego, które właśnie zostanie utworzone. Pamiętaj, aby zmienić nazwę odpowiednio na podstawie tworzenia środowiska wirtualnego.
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesMożesz też użyć repozytorium PyPi, zmienić
numpy==1.16.1ipy35newodpowiednio:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
Jeśli nie znasz nazwy środowiska wirtualnego, możesz uruchomić protokół SSH w węźle głównym klastra i uruchomić
/usr/bin/anaconda/bin/conda info -epolecenie , aby wyświetlić wszystkie środowiska wirtualne.Zmień konfiguracje platformy Spark i usługi Livy i wskaż utworzone środowisko wirtualne.
Otwórz interfejs użytkownika systemu Ambari, przejdź do strony Spark 2, karty Konfiguracje.
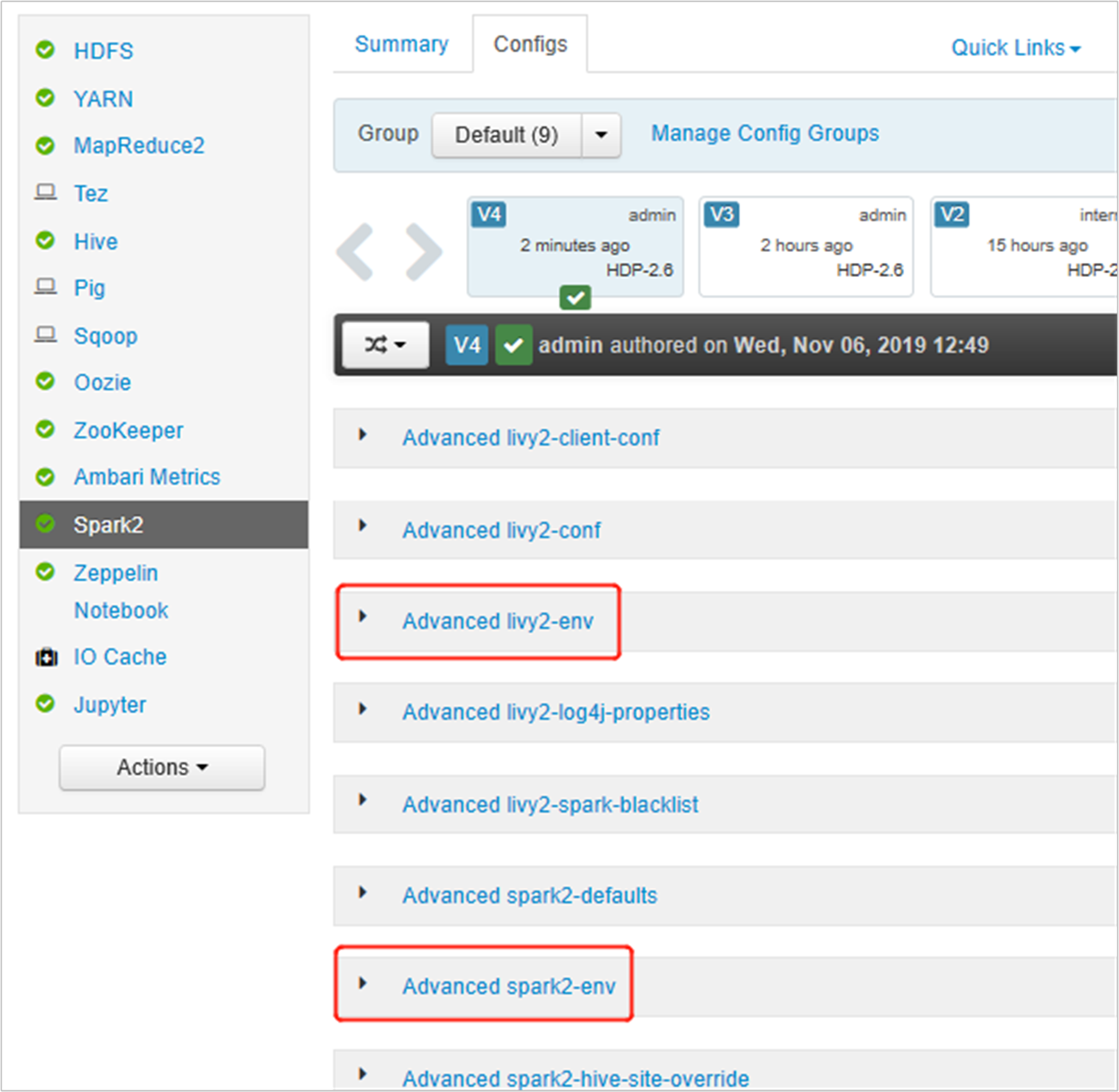
Rozwiń węzeł Advanced livy2-env, dodaj następujące instrukcje u dołu. Jeśli środowisko wirtualne zainstalowano z innym prefiksem, zmień odpowiednio ścieżkę.
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python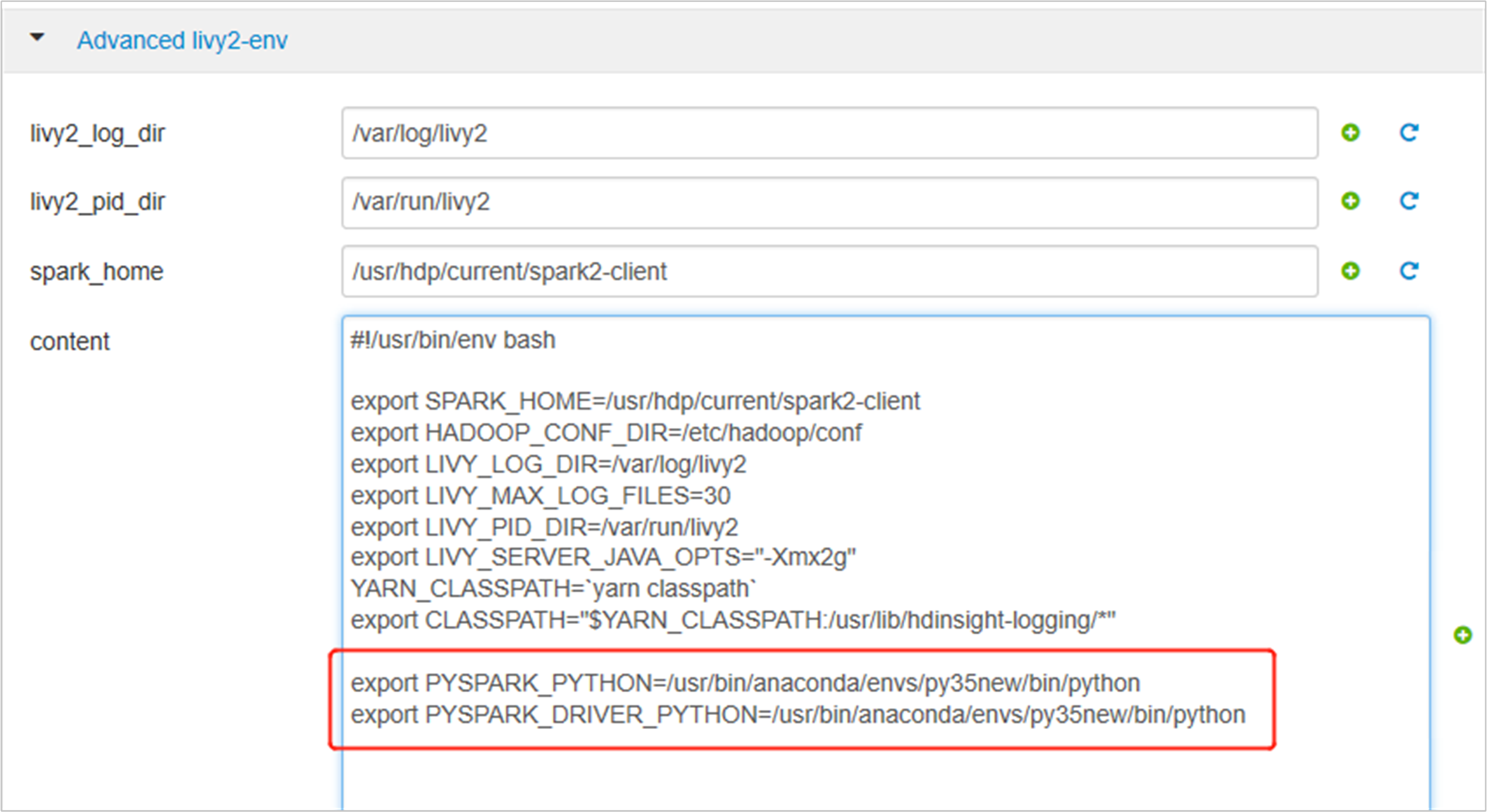
Rozwiń węzeł Zaawansowane spark2-env, zastąp istniejącą instrukcję export PYSPARK_PYTHON u dołu. Jeśli środowisko wirtualne zainstalowano z innym prefiksem, zmień odpowiednio ścieżkę.
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}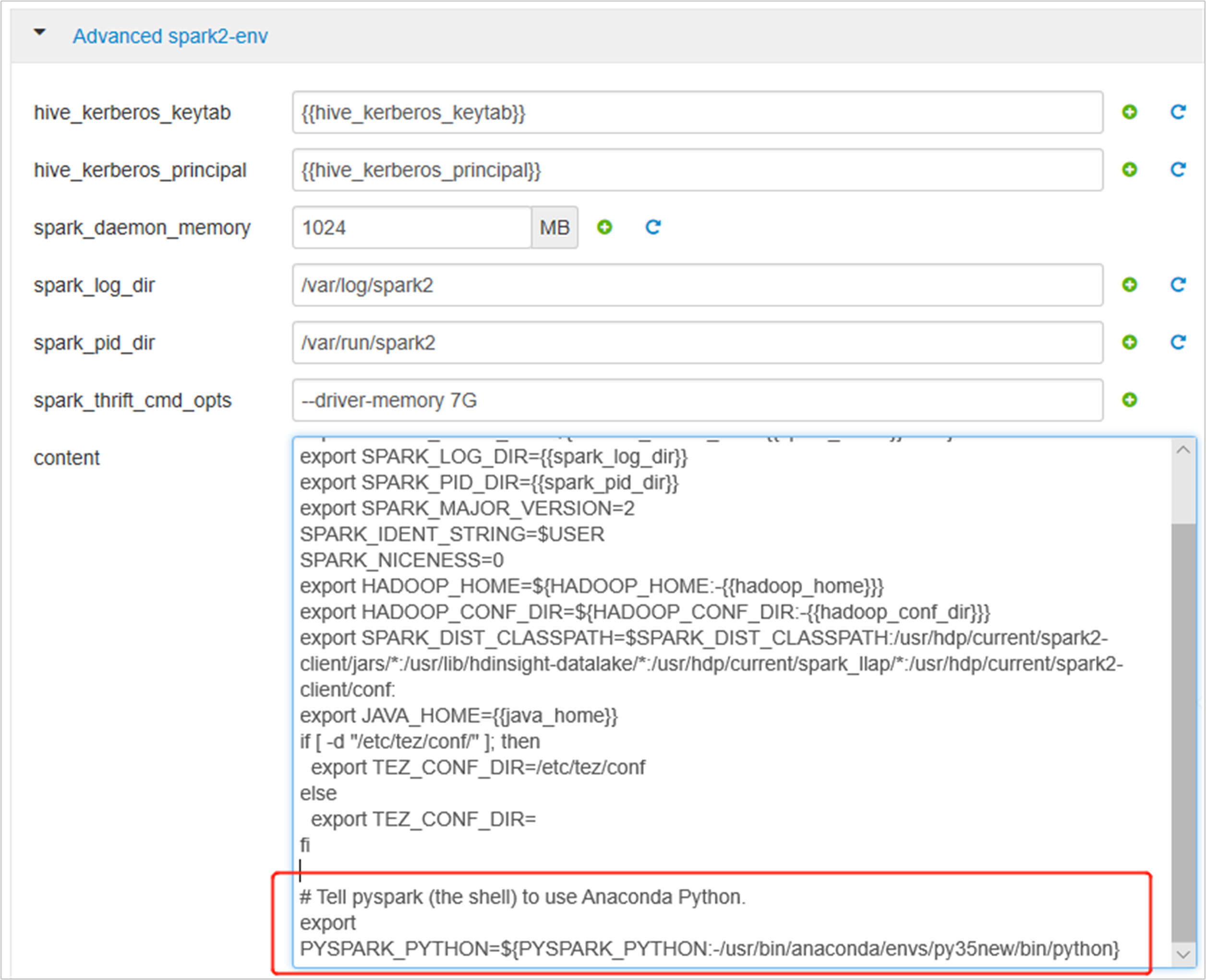
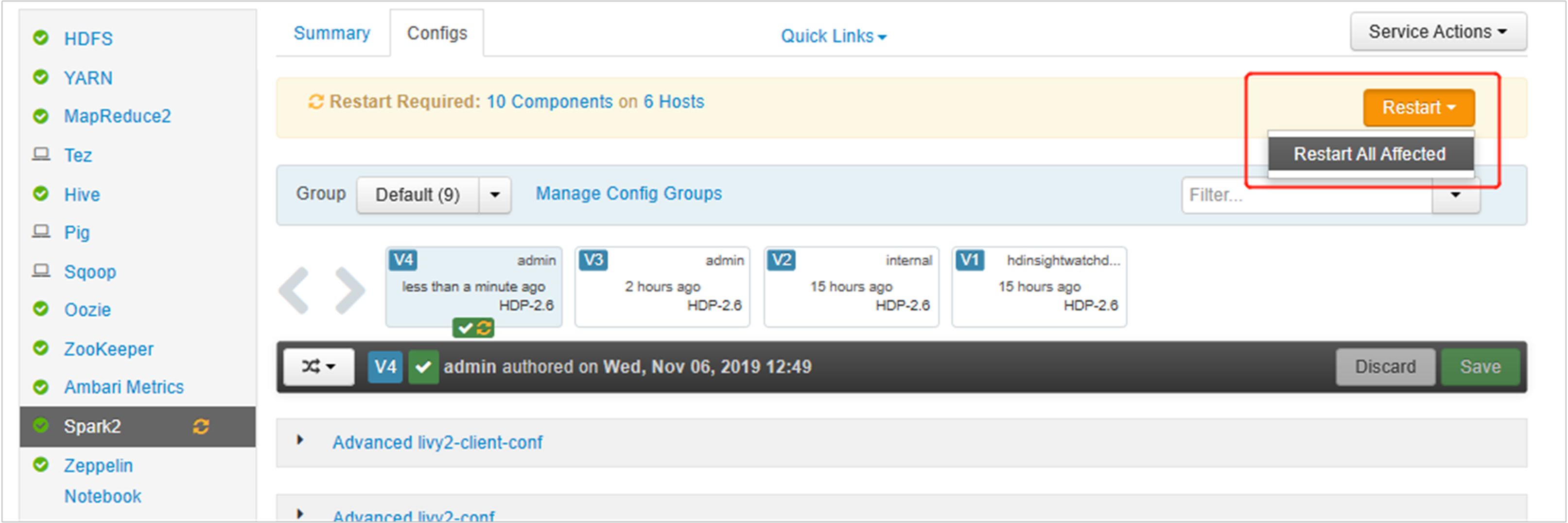
Zapisz zmiany i uruchom ponownie objęte usługi. Te zmiany wymagają ponownego uruchomienia usługi Spark 2. Interfejs użytkownika systemu Ambari wyświetli monit o wymagane przypomnienie o ponownym uruchomieniu, kliknij przycisk Uruchom ponownie, aby ponownie uruchomić wszystkie objęte usługi.
Ustaw dwie właściwości na sesję platformy Spark, aby upewnić się, że zadanie wskazuje zaktualizowaną konfigurację platformy Spark:
spark.yarn.appMasterEnv.PYSPARK_PYTHONispark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON.Za pomocą terminalu lub notesu
spark.conf.setużyj funkcji .spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")Jeśli używasz metody
livy, dodaj następujące właściwości do treści żądania:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
Jeśli chcesz użyć nowego utworzonego środowiska wirtualnego w programie Jupyter. Zmień konfiguracje programu Jupyter i uruchom ponownie program Jupyter. Uruchom akcje skryptu na wszystkich węzłach nagłówka z następującą instrukcją, aby wskazać program Jupyter do nowego utworzonego środowiska wirtualnego. Pamiętaj, aby zmodyfikować ścieżkę do prefiksu określonego dla środowiska wirtualnego. Po uruchomieniu tej akcji skryptu uruchom ponownie usługę Jupyter za pomocą interfejsu użytkownika systemu Ambari, aby udostępnić tę zmianę.
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonMożesz dwukrotnie potwierdzić środowisko języka Python w notesie Jupyter Notebook, uruchamiając kod: