Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Ta strona zawiera instrukcje dotyczące zarządzania składnikami operacji usługi Azure IoT przy użyciu manifestów wdrażania platformy Kubernetes, które są w wersji zapoznawczej. Ta funkcja jest udostępniana z kilkoma ograniczeniami i nie powinna być używana w przypadku obciążeń produkcyjnych.
Zapoznaj się z dodatkowymi warunkami użytkowania dla wersji zapoznawczych platformy Microsoft Azure , aby zapoznać się z postanowieniami prawnymi dotyczącymi funkcji platformy Azure, które są w wersji beta, wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej.
Przepływ danych to ścieżka, jaką dane przemierzają od źródła do miejsca docelowego z opcjonalnymi przekształceniami. Przepływ danych można skonfigurować, tworząc niestandardowy zasób przepływu danych lub korzystając z internetowego interfejsu użytkownika środowiska operacji. Przepływ danych składa się z trzech części: źródła, transformacji i miejsca docelowego.

Aby zdefiniować źródło i miejsce docelowe, należy skonfigurować punkty końcowe przepływu danych. Transformacja jest opcjonalna i może obejmować operacje, takie jak wzbogacanie danych, filtrowanie danych i mapowanie danych na inne pole.
Ważne
Każdy przepływ danych musi mieć domyślny
Możesz użyć doświadczenia operacyjnego w Azure IoT Operations, aby utworzyć przepływ danych. Środowisko operacji udostępnia interfejs wizualny do konfigurowania przepływu danych. Możesz również użyć narzędzia Bicep, aby utworzyć przepływ danych przy użyciu pliku Bicep lub użyć rozwiązania Kubernetes do utworzenia przepływu danych przy użyciu pliku YAML.
Kontynuuj czytanie, aby dowiedzieć się, jak skonfigurować źródło, transformację i miejsce docelowe.
Wymagania wstępne
Przepływy danych można wdrażać natychmiast po wystąpieniu operacji usługi Azure IoT przy użyciu domyślnego profilu przepływu danych i punktu końcowego. Można jednak skonfigurować profile i punkty końcowe przepływu danych w celu dostosowania przepływu danych.
Profil przepływu danych
Jeśli nie potrzebujesz różnych ustawień skalowania dla przepływów danych, użyj domyślnego profilu przepływu danych udostępnianego przez operacje usługi Azure IoT. Należy unikać kojarzenia zbyt wielu przepływów danych z jednym profilem przepływu danych. Jeśli masz dużą liczbę przepływów danych, rozłóż je między wiele profilów przepływu danych, aby zmniejszyć ryzyko przekroczenia limitu rozmiaru konfiguracji profilu przepływu danych wynoszącego 70.
Aby dowiedzieć się, jak skonfigurować nowy profil przepływu danych, zobacz Konfigurowanie profilów przepływu danych.
Punkty końcowe przepływu danych
Punkty końcowe przepływu danych są wymagane do skonfigurowania źródła i miejsca docelowego przepływu danych. Aby szybko rozpocząć pracę, możesz użyć domyślnego punktu końcowego przepływu danych dla lokalnego brokera MQTT. Można również tworzyć inne typy punktów końcowych przepływu danych, takich jak Kafka, Event Hubs, OpenTelemetry lub Azure Data Lake Storage. Aby dowiedzieć się, jak skonfigurować każdy typ punktu końcowego przepływu danych, zobacz Konfigurowanie punktów końcowych przepływu danych.
Wprowadzenie
Po spełnieniu wymagań wstępnych możesz rozpocząć tworzenie przepływu danych.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
Aby utworzyć przepływ danych w środowisku operacji, wybierz pozycję Przepływ>danych Utwórz przepływ danych.
Wybierz nazwę zastępczą new-data-flow , aby ustawić właściwości przepływu danych. Wprowadź nazwę przepływu danych i wybierz profil przepływu danych do użycia. Domyślny profil przepływu danych jest domyślnie wybierany. Aby uzyskać więcej informacji na temat profilów przepływu danych, zobacz Konfigurowanie profilu przepływu danych.

Ważne
Profil przepływu danych można wybrać tylko podczas tworzenia przepływu danych. Nie można zmienić profilu przepływu danych po utworzeniu przepływu danych. Jeśli chcesz zmienić profil przepływu danych istniejącego przepływu danych, usuń oryginalny przepływ danych i utwórz nowy przy użyciu nowego profilu przepływu danych.
Skonfiguruj źródłowy, transformacyjny i docelowy punkt końcowy dla przepływu danych, wybierając elementy na diagramie przepływu danych.
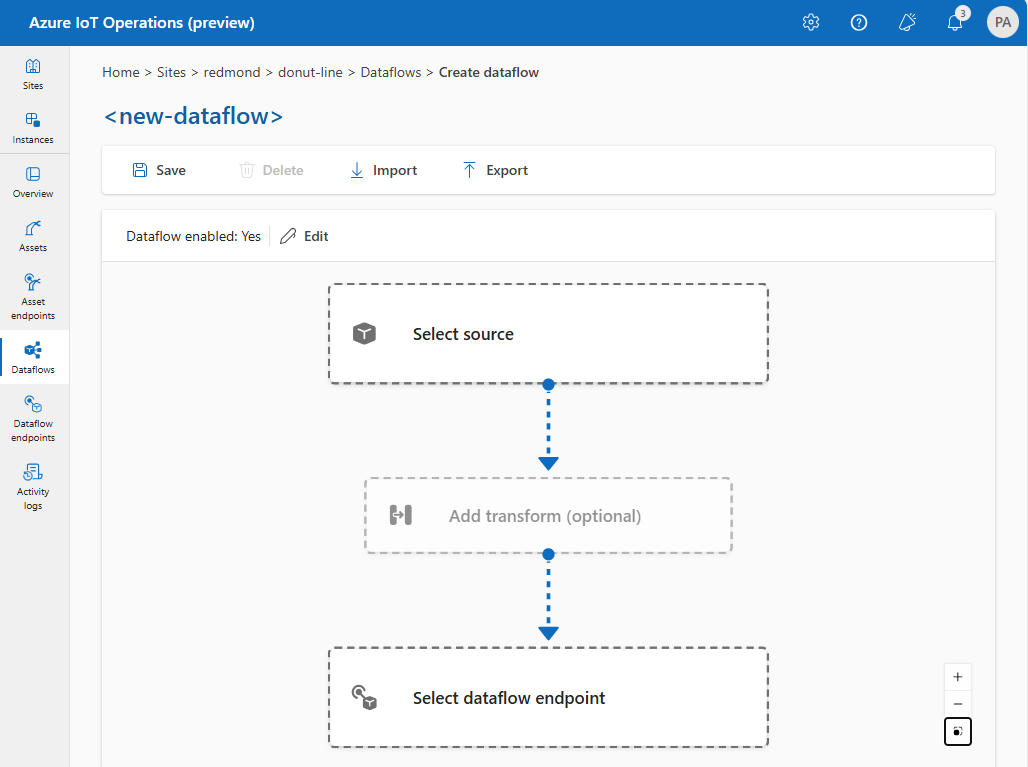
Zapoznaj się z poniższymi sekcjami, aby dowiedzieć się, jak skonfigurować typy operacji przepływu danych.
Źródło
Aby skonfigurować źródło przepływu danych, określ odwołanie do punktu końcowego i listę źródeł danych dla punktu końcowego. Wybierz jedną z następujących opcji jako źródło przepływu danych.
Jeśli domyślny punkt końcowy nie jest używany jako źródło, musi być używany jako miejsce docelowe. Aby dowiedzieć się więcej na temat korzystania z lokalnego punktu końcowego brokera MQTT, zobacz Przepływy danych muszą używać lokalnego punktu końcowego brokera MQTT.
Opcja 1. Użyj domyślnego punktu końcowego brokera komunikatów jako źródła
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W obszarze Szczegóły źródła wybierz pozycję Broker komunikatów.
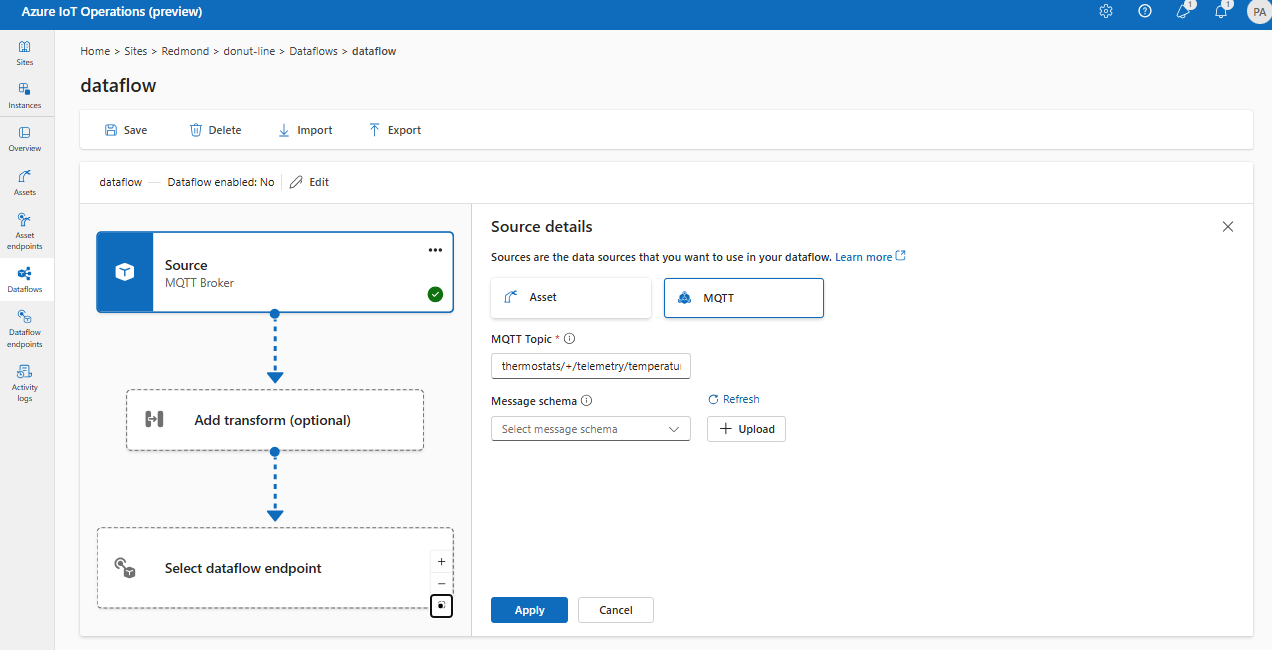
Wprowadź następujące ustawienia dla źródła brokera komunikatów:
Ustawienia Opis Punkt końcowy przepływu danych Wybierz wartość domyślną , aby użyć domyślnego punktu końcowego brokera komunikatów MQTT. Temat Filtr tematu do subskrybowania wiadomości przychodzących. Użyj Temat(y)>Dodaj wiersz, aby dodać wiele tematów. Aby uzyskać więcej informacji na temat tematów, zobacz Konfigurowanie tematów MQTT lub Kafka. Schemat komunikatu Schemat używany do deserializacji przychodzących komunikatów. Zobacz Określanie schematu do deserializacji danych. Wybierz Zastosuj.
Ponieważ dataSources umożliwia określenie tematów MQTT lub Kafka bez modyfikowania konfiguracji punktu końcowego, można ponownie użyć punktu końcowego dla wielu przepływów danych, nawet jeśli tematy są inne. Aby dowiedzieć się więcej, zobacz Konfigurowanie źródeł danych.
Opcja 2. Użyj elementu zawartości jako źródła
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
Można użyć zasobu jako źródła przepływu danych. Używanie zasobu jako źródła jest dostępne tylko w operacyjnym środowisku doświadczalnym.
W obszarze Szczegóły źródła wybierz pozycję Zasób.
Wybierz zasób, którego chcesz użyć jako źródłowego punktu końcowego.
Wybierz pozycję Kontynuuj.
Zostanie wyświetlona lista punktów danych dla wybranego zasobu.

Wybierz pozycję Zastosuj, aby użyć zasobu jako źródłowy punkt końcowy.
W przypadku używania zasobu jako źródła definicja zasobu służy do wnioskowania schematu przepływu danych. Definicja zasobu zawiera schemat punktów danych zasobu. Aby dowiedzieć się więcej, zobacz Zdalne zarządzanie konfiguracjami zasobów.
Po skonfigurowaniu dane z zasobu docierają do przepływu danych za pośrednictwem lokalnego brokera MQTT. Dlatego podczas używania zasobu jako źródła przepływ danych w rzeczywistości wykorzystuje domyślny punkt końcowy lokalnego brokera MQTT jako źródło.
Opcja 3. Użyj niestandardowego punktu końcowego przepływu danych MQTT lub Kafka jako źródła
Jeśli utworzono niestandardowy punkt końcowy przepływu danych MQTT lub Kafka (na przykład do użycia z usługą Event Grid lub Event Hubs), możesz użyć go jako źródła przepływu danych. Pamiętaj, że punkty końcowe typu magazynu, takie jak Data Lake lub Fabric OneLake, nie mogą być używane jako źródło.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W obszarze Szczegóły źródła wybierz pozycję Broker komunikatów.

Wprowadź następujące ustawienia dla źródła brokera komunikatów:
Ustawienia Opis Punkt końcowy przepływu danych Użyj przycisku Wybierz ponownie , aby wybrać niestandardowy punkt końcowy przepływu danych MQTT lub Kafka. Aby uzyskać więcej informacji, zobacz Konfigurowanie punktów końcowych przepływu danych MQTT lub Konfigurowanie punktów końcowych przepływu danych usługi Azure Event Hubs i platformy Kafka. Temat Filtr tematu do subskrybowania wiadomości przychodzących. Użyj Temat(y)>Dodaj wiersz, aby dodać wiele tematów. Aby uzyskać więcej informacji na temat tematów, zobacz Konfigurowanie tematów MQTT lub Kafka. Schemat komunikatu Schemat używany do deserializacji przychodzących komunikatów. Zobacz Określanie schematu do deserializacji danych. Wybierz Zastosuj.
Konfigurowanie źródeł danych (tematy MQTT lub Kafka)
W źródle można określić wiele tematów MQTT lub Kafka bez konieczności modyfikowania konfiguracji punktu końcowego przepływu danych. Ta elastyczność oznacza, że ten sam punkt końcowy może być ponownie używany w wielu przepływach danych, nawet jeśli tematy się różnią. Aby uzyskać więcej informacji, zobacz Ponowne używanie punktów końcowych przepływu danych.
Tematy MQTT
Jeśli źródłem jest punkt końcowy MQTT (uwzględniona usługa Event Grid), możesz użyć filtru tematu MQTT, aby subskrybować komunikaty przychodzące. Filtr tematu może zawierać symbole wieloznaczne, aby subskrybować wiele tematów. Na przykład thermostats/+/sensor/temperature/# subskrybuje wszystkie komunikaty czujnika temperatury z termostatów. Aby skonfigurować filtry tematów MQTT:
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W przepływie danych dotyczących doświadczenia operacyjnego Szczegóły źródła, wybierz Broikera komunikatów, a następnie użyj pola Tematy, by określić filtry tematów MQTT do subskrybowania przychodzących komunikatów. Możesz dodać wiele tematów MQTT, wybierając pozycję Dodaj wiersz i wprowadzając nowy temat.
Subskrypcje udostępnione
Aby użyć subskrypcji udostępnionych ze źródłami brokera komunikatów, możesz określić temat subskrypcji udostępnionej w postaci $shared/<GROUP_NAME>/<TOPIC_FILTER>.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W obszarze Szczegóły przepływu danych środowiska operacji wybierz pozycję Broker komunikatów i użyj pola Temat , aby określić udostępnioną grupę subskrypcji i temat.
Jeśli liczba wystąpień w profilu przepływu danych przekracza jeden, współdzielona subskrypcja jest automatycznie włączana dla wszystkich przepływów danych, które korzystają ze źródła brokera komunikatów. W takim przypadku $shared prefiks jest dodawany, a nazwa udostępnionej grupy subskrypcji jest generowana automatycznie. Jeśli na przykład masz profil przepływu danych z liczbą wystąpień wynoszącą 3, a przepływ danych używa punktu końcowego brokera komunikatów jako źródła skonfigurowanego z tematami topic1 i topic2, są one automatycznie konwertowane na subskrypcje udostępnione jako $shared/<GENERATED_GROUP_NAME>/topic1 i $shared/<GENERATED_GROUP_NAME>/topic2.
Możesz jawnie utworzyć temat o nazwie $shared/mygroup/topic w konfiguracji. Jednak jawne dodanie tematu $shared nie jest zalecane, ponieważ $shared prefiks jest automatycznie dodawany w razie potrzeby. Przepływy danych mogą dokonywać optymalizacji przy użyciu nazwy grupy, jeśli nie jest ona ustawiona. Na przykład $share nie jest ustawiony, a przepływy danych muszą działać wyłącznie na podstawie nazwy tematu.
Ważne
Przepływy danych wymagające wspólnej subskrypcji, gdy liczba instancji przekracza jedną, są ważne w przypadku korzystania z brokera MQTT usługi Event Grid jako źródła, ponieważ nie obsługuje wspólnych subskrypcji. Aby uniknąć brakujących komunikatów, ustaw liczbę wystąpień profilu przepływu danych na jedną podczas korzystania z brokera MQTT usługi Event Grid jako źródła. Dzieje się tak, gdy przepływ danych jest subskrybentem i odbiera komunikaty z chmury.
Tematy dotyczące platformy Kafka
Gdy źródłem jest punkt końcowy platformy Kafka (dołączone do usługi Event Hubs), określ poszczególne tematy platformy Kafka, które mają być subskrybowane dla komunikatów przychodzących. Symbole wieloznaczne nie są obsługiwane, dlatego należy określić każdy temat statycznie.
Uwaga / Notatka
W przypadku korzystania z usługi Event Hubs za pośrednictwem punktu końcowego platformy Kafka każde pojedyncze centrum zdarzeń w przestrzeni nazw jest tematem platformy Kafka. Jeśli na przykład masz przestrzeń nazw usługi Event Hubs z dwoma hubami zdarzeń, thermostats i humidifiers, możesz określić każdy hub zdarzeń jako temat platformy Kafka.
Aby skonfigurować tematy platformy Kafka:
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W obszarze Szczegóły źródła przepływu danych środowiska operacji wybierz pozycję Broker komunikatów, a następnie użyj pola Temat , aby określić filtr tematu platformy Kafka, aby zasubskrybować komunikaty przychodzące.
Uwaga / Notatka
W środowisku operacji można określić tylko jeden filtr tematu. Aby użyć wielu filtrów tematów, użyj Bicep lub Kubernetes.
Określanie schematu źródłowego
W przypadku używania MQTT lub Kafka jako źródła można określić schemat umożliwiający wyświetlenie listy punktów danych w internetowym interfejsie użytkownika środowiska operacji. Używanie schematu do deserializacji i weryfikowania przychodzących komunikatów nie jest obecnie obsługiwane.
Jeśli źródło jest zasobem, schemat jest automatycznie wnioskowany z definicji zasobu.
Wskazówka
Aby wygenerować schemat na podstawie przykładowego pliku danych, użyj pomocnika generacji schematu.
Aby skonfigurować schemat używany do deserializacji przychodzących komunikatów ze źródła:
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W przepływie danych środowiska operacyjnego Szczegóły źródła wybierz Broker komunikatów i użyj pola Schemat komunikatu, aby określić schemat. Możesz użyć przycisku Przekaż , aby najpierw przekazać plik schematu. Aby dowiedzieć się więcej, zobacz Omówienie schematów komunikatów.
Aby dowiedzieć się więcej, zobacz Omówienie schematów komunikatów.
Żądanie trwałości dysku
Żądanie trwałości dysku umożliwia przepływom danych zachowanie stanu po ponownym uruchomieniu. Po włączeniu tej funkcji graf odzyskuje stan przetwarzania, jeśli połączony broker zostanie uruchomiony ponownie. Ta funkcja jest przydatna w scenariuszach przetwarzania stanowego, w których utrata danych pośrednich jest problemem. Po włączeniu trwałości żądania na dysku, broker zapisuje dane MQTT, takie jak komunikaty w kolejce subskrybentów, na dysk. Takie podejście zapewnia, że źródło danych przepływu danych nie traci danych podczas przestojów zasilania ani ponownego uruchamiania brokera. Broker utrzymuje optymalną wydajność, ponieważ trwałość jest skonfigurowana dla przepływu danych, więc tylko przepływy danych, które wymagają trwałości, używają tej funkcji.
Wykres przepływu danych żąda tej trwałości podczas subskrypcji przy użyciu właściwości użytkownika MQTTv5. Ta funkcja działa tylko wtedy, gdy:
- Przepływ danych używa brokera lub zasobu MQTT jako źródła
- Broker MQTT ma włączoną trwałość w trybie dynamicznym ustawionym na
Enableddla typu danych, takich jak kolejki subskrybentów.
Ta konfiguracja umożliwia klientom MQTT, takim jak przepływy danych, żądają trwałości dysku dla swoich subskrypcji przy użyciu właściwości użytkownika MQTTv5. Aby uzyskać szczegółowe informacje na temat konfiguracji trwałości brokera MQTT, zobacz Konfigurowanie trwałości brokera MQTT.
Ustawienie akceptuje Enabled wartość lub Disabled.
Disabled jest wartością domyślną.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
Podczas tworzenia lub edytowania przepływu danych wybierz pozycję Edytuj, a następnie wybierz pozycję Tak obok pozycji Zażądaj trwałości danych.
Przekształcenie
Operacja przekształcania umożliwia przekształcenie danych ze źródła przed wysłaniem ich do miejsca docelowego. Przekształcenia są opcjonalne. Jeśli nie musisz wprowadzać zmian w danych, nie uwzględniaj operacji przekształcania w konfiguracji przepływu danych. Wiele przekształceń jest połączonych w łańcuch i realizowanych etapami, niezależnie od kolejności, w jakiej są określone w konfiguracji. Kolejność etapów jest zawsze:
- Wzbogacanie: dodaj dodatkowe dane do danych źródłowych, biorąc pod uwagę zestaw danych i warunek, które mają być zgodne.
- Filtr: filtruj dane na podstawie warunku.
- Mapowanie, obliczanie, zmienianie nazwy lub dodawanie nowej właściwości: przenoszenie danych z jednego pola do innego z opcjonalną konwersją.
Ta sekcja stanowi wprowadzenie do przekształceń przepływu danych. Aby uzyskać bardziej szczegółowe informacje, zobacz Mapuj dane przy użyciu przepływów danych, Konwertowanie danych przy użyciu konwersji przepływu danych i Wzbogacanie danych przy użyciu przepływów danych.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W środowisku operacji wybierz pozycję Przepływ> danychDodaj przekształcenie (opcjonalnie)..
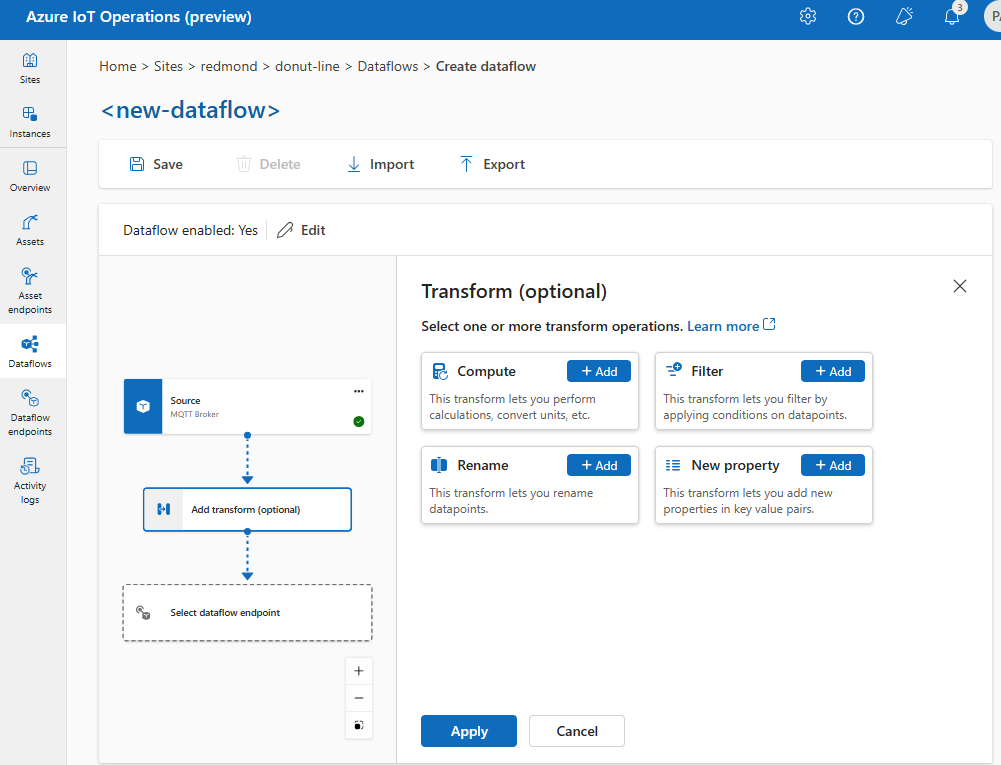
Wzbogacanie: dodawanie danych referencyjnych
Aby wzbogacić dane, najpierw dodaj zestaw danych referencyjnych w magazynie stanu operacji usługi Azure IoT. Zestaw danych służy do dodawania dodatkowych danych do danych źródłowych na podstawie warunku. Warunek jest określany jako pole w danych źródłowych, które pasuje do pola w zestawie danych.
Przykładowe dane można załadować do magazynu stanów przy użyciu interfejsu wiersza polecenia magazynu stanów. Nazwy kluczy w magazynie stanów odpowiadają zestawowi danych w konfiguracji przepływu danych.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
Obecnie etap Wzbogacanie nie jest obsługiwany w środowisku operacji.
Jeśli zestaw danych zawiera rekord z polem asset , podobnie jak:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Dane ze źródła, w którym pole deviceId odpowiada thermostat1, mają pola location i manufacturer dostępne w etapach filtrowania i mapowania.
Aby uzyskać więcej informacji na temat składni warunku, zobacz Wzbogacanie danych przy użyciu przepływów danych i Konwertowanie danych przy użyciu przepływów danych.
Filtr: filtrowanie danych na podstawie warunku
Aby filtrować dane według warunku, możesz użyć etapu filter . Warunek jest określony jako pole w danych źródłowych, które pasuje do wartości.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W obszarze Przekształć (opcjonalnie) wybierz pozycję Filtr>Dodaj.

Wprowadź wymagane ustawienia.
Ustawienia Opis Warunek filtru Warunek filtrowania danych na podstawie pola w danych źródłowych. Opis Podaj opis warunku filtru. W polu warunek filtru wprowadź
@lub wybierz Ctrl + Spacja , aby wybrać punkty danych z listy rozwijanej.Właściwości metadanych MQTT można wprowadzić przy użyciu formatu
@$metadata.user_properties.<property>lub@$metadata.topic. Możesz również wprowadzić nagłówki $metadata przy użyciu formatu@$metadata.<header>. Składnia jest wymagana$metadatatylko dla właściwości MQTT, które są częścią nagłówka komunikatu. Aby uzyskać więcej informacji, zobacz tematy dotyczące pól.Warunek może używać pól w danych źródłowych. Można na przykład użyć warunku filtru, takiego jak
@temperature > 20, aby filtrować dane mniejsze lub równe 20 na podstawie pola temperatury.Wybierz Zastosuj.
Mapa: Przenoszenie danych z jednego pola do innego
Aby zamapować dane na inne pole z opcjonalną konwersją, możesz użyć map operacji . Konwersja jest określana jako formuła, która używa pól w danych źródłowych.
W środowisku operacji mapowanie jest obecnie obsługiwane przy użyciu przekształceń Compute, Rename oraz nowa właściwość.
Compute
Możesz użyć przekształcenia Oblicz, aby zastosować formułę do danych źródłowych. Ta operacja służy do stosowania formuły do danych źródłowych i przechowywania pola wyników.
W obszarze Przekształć (opcjonalnie) wybierz pozycję Dodaj obliczenia>.
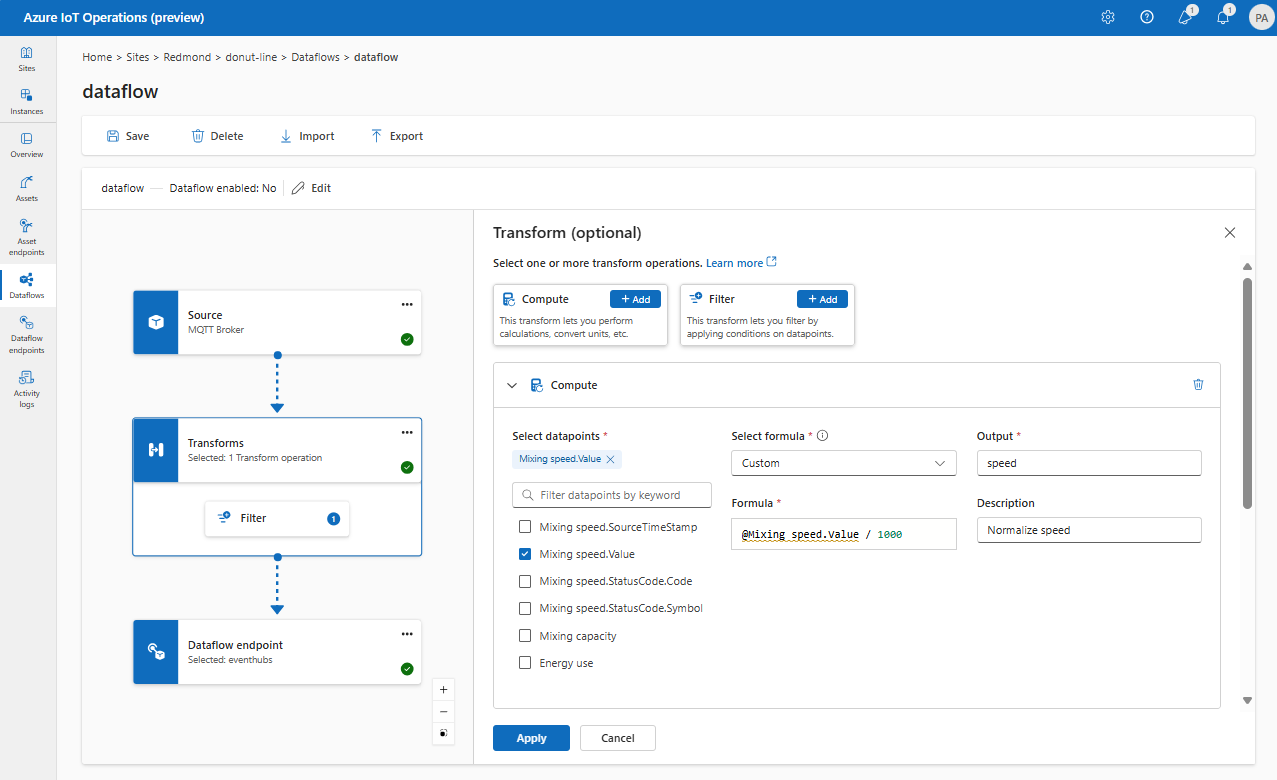
Wprowadź wymagane ustawienia.
Ustawienia Opis Wybieranie formuły Wybierz istniejącą formułę z listy rozwijanej lub wybierz pozycję Niestandardowe , aby ręcznie wprowadzić formułę. Wynik Określ nazwę wyświetlaną dla wyniku. Formuła Wprowadź formułę, która ma zostać zastosowana do danych źródłowych. Opis Podaj opis przekształcenia. Ostatnia znana wartość Opcjonalnie użyj ostatniej znanej wartości, jeśli bieżąca wartość jest niedostępna. Formułę można wprowadzić lub edytować w polu Formuła . Formuła może używać pól w danych źródłowych. Wprowadź
@lub wybierz Ctrl + Spacja , aby wybrać punkty danych z listy rozwijanej. W przypadku wbudowanych formuł wybierz<dataflow>symbol zastępczy, aby wyświetlić listę dostępnych punktów danych.Właściwości metadanych MQTT można wprowadzić przy użyciu formatu
@$metadata.user_properties.<property>lub@$metadata.topic. Możesz również wprowadzić nagłówki $metadata przy użyciu formatu@$metadata.<header>. Składnia jest wymagana$metadatatylko dla właściwości MQTT, które są częścią nagłówka komunikatu. Aby uzyskać więcej informacji, zobacz tematy dotyczące pól.Formuła może używać pól w danych źródłowych. Możesz na przykład użyć
temperaturepola w danych źródłowych, aby przekonwertować temperaturę na stopnie Celsjusza i zapisać je w polu wyjściowymtemperatureCelsius.Wybierz Zastosuj.
Zmień nazwę
Nazwę punktu danych można zmienić przy użyciu przekształcenia Zmień nazwę . Ta operacja służy do zmieniania nazwy punktu danych w danych źródłowych na nową nazwę. Nowa nazwa może być używana w kolejnych etapach przepływu danych.
W obszarze Przekształć (opcjonalnie)wybierz pozycję Zmień nazwę>dodaj.

Wprowadź wymagane ustawienia.
Ustawienia Opis Punkt danych Wybierz punkt danych z listy rozwijanej lub wprowadź nagłówek $metadata. Nowa nazwa punktu danych Wprowadź nową nazwę punktu danych. Opis Podaj opis przekształcenia. Właściwości metadanych MQTT można wprowadzić przy użyciu formatu
@$metadata.user_properties.<property>lub@$metadata.topic. Możesz również wprowadzić nagłówki $metadata przy użyciu formatu@$metadata.<header>. Składnia jest wymagana$metadatatylko dla właściwości MQTT, które są częścią nagłówka komunikatu. Aby uzyskać więcej informacji, zobacz tematy dotyczące pól.Wybierz Zastosuj.
Nowa właściwość
Możesz dodać nową właściwość do danych źródłowych przy użyciu przekształcenia nowej właściwości . Ta operacja służy do dodawania nowej właściwości do danych źródłowych. Nowa właściwość może być używana w kolejnych etapach przepływu danych.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W obszarze Przekształć (opcjonalnie)wybierz pozycję Nowa właściwość>Dodaj.

Wprowadź wymagane ustawienia.
Ustawienia Opis Klucz właściwości Wprowadź klucz nowej właściwości. Wartość właściwości Wprowadź wartość nowej właściwości. Opis Podaj opis nowej właściwości. Wybierz Zastosuj.
Aby dowiedzieć się więcej, zobacz Mapuj dane przy użyciu przepływów danych i Konwertuj dane przy użyciu przepływów danych.
Usuń
Domyślnie wszystkie punkty danych są uwzględniane w schemacie danych wyjściowych. Możesz usunąć dowolny punkt danych z miejsca docelowego, korzystając z przekształcenia Usuń.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W obszarze Przekształć (opcjonalnie) wybierz pozycję Usuń.
Wybierz punkt danych, który ma być usunięty ze schematu wyjściowego.

Wybierz Zastosuj.
Aby dowiedzieć się więcej, zobacz Mapuj dane przy użyciu przepływów danych i Konwertuj dane przy użyciu przepływów danych.
Serializowanie danych zgodnie ze schematem
Jeśli chcesz serializować dane przed wysłaniem ich do miejsca docelowego, musisz określić format schematu i serializacji. W przeciwnym razie dane są serializowane w formacie JSON, a typy są wnioskowane. Punkty końcowe danych, takie jak Microsoft Fabric lub Azure Data Lake, wymagają schematu w celu zapewnienia spójności danych. Obsługiwane formaty serializacji to Parquet i Delta.
Wskazówka
Aby wygenerować schemat na podstawie przykładowego pliku danych, użyj pomocnika generacji schematu.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
Dla doświadczenia operacyjnego należy określić schemat i format serializacji w szczegółach punktu końcowego przepływu danych. Punkty końcowe, które obsługują formaty serializacji, to Microsoft Fabric OneLake, Azure Data Lake Storage Gen 2, Azure Data Explorer i magazyn lokalny. Na przykład aby serializować dane w formacie delta, należy przekazać schemat do rejestru schematów i odwołać się do niego w konfiguracji docelowego punktu końcowego przepływu danych.

Aby uzyskać więcej informacji na temat rejestru schematów, zobacz Omówienie schematów komunikatów.
Destynacja
Aby skonfigurować miejsce docelowe przepływu danych, określ odwołanie do punktu końcowego i miejsce docelowe danych. Możesz określić listę miejsc docelowych danych dla punktu końcowego.
Aby wysłać dane do miejsca docelowego innego niż lokalny broker MQTT, utwórz punkt końcowy przepływu danych. Aby dowiedzieć się, jak to zrobić, zobacz Konfigurowanie punktów końcowych przepływu danych. Jeśli miejsce docelowe nie jest lokalnym brokerem MQTT, musi być używane jako źródło. Aby dowiedzieć się więcej na temat korzystania z lokalnego punktu końcowego brokera MQTT, zobacz Przepływy danych muszą używać lokalnego punktu końcowego brokera MQTT.
Ważne
Punkty końcowe pamięci masowej wymagają schematu do serializacji. Aby używać przepływu danych z usługą Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer lub Local Storage, należy określić odwołanie do schematu.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
Wybierz punkt końcowy przepływu danych, który ma być używany jako miejsce docelowe.
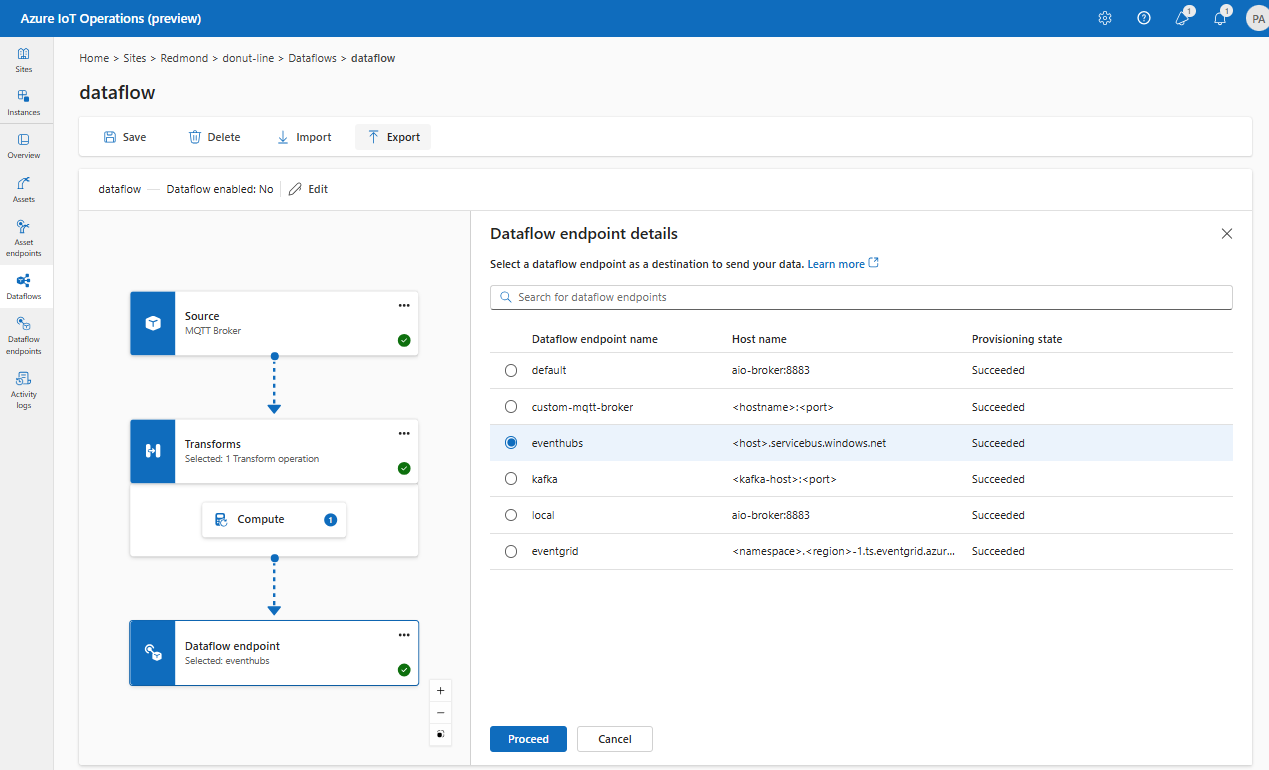
Punkty końcowe pamięci masowej wymagają schematu do serializacji. Jeśli wybierzesz punkt końcowy docelowy usługi Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer lub Lokalny magazyn, musisz określić odwołanie do schematu. Na przykład aby serializować dane do punktu końcowego usługi Microsoft Fabric w formacie delta, należy przekazać schemat do rejestru schematów i odwołać się do niego w konfiguracji docelowego punktu końcowego przepływu danych.

Wybierz pozycję Kontynuuj , aby skonfigurować miejsce docelowe.
Wprowadź wymagane ustawienia dla miejsca docelowego, w tym temat lub tabelę do wysłania danych. Aby uzyskać więcej informacji, zobacz Konfigurowanie miejsca docelowego danych (tematu, kontenera lub tabeli).
Konfigurowanie miejsca docelowego danych (temat, kontener lub tabela)
Podobnie jak w przypadku źródeł danych, przeznaczenie danych jest koncepcją używaną do zapewnienia, że punkty końcowe przepływu danych mogą być wielokrotnie wykorzystywane w różnych przepływach danych. Zasadniczo reprezentuje podkatalog w konfiguracji punktu końcowego przepływu danych. Jeśli na przykład punkt końcowy przepływu danych jest punktem końcowym magazynu, miejsce docelowe danych to tabela na koncie magazynu. Jeśli punkt końcowy przepływu danych jest punktem końcowym platformy Kafka, miejsce docelowe danych to temat platformy Kafka.
| Typ punktu końcowego | Znaczenie miejsca docelowego danych | Opis |
|---|---|---|
| MQTT (lub Event Grid) | Temat | Temat MQTT, w którym są wysyłane dane. Obsługuje zarówno tematy statyczne, jak i dynamiczne tłumaczenie tematów przy użyciu zmiennych, takich jak ${inputTopic} i ${inputTopic.index}. Aby uzyskać więcej informacji, zobacz Tematy dotyczące dynamicznego miejsca docelowego. |
| Kafka (lub Event Hubs) | Temat | Temat Kafka, do którego są wysyłane dane. Obsługiwane są tylko tematy statyczne, bez użycia znaków wieloznacznych. Jeśli punkt końcowy jest przestrzenią nazw usługi Event Hubs, docelowa lokalizacja danych jest to pojedyncze centrum zdarzeń w ramach tej przestrzeni nazw. |
| Azure Data Lake Storage | Pojemnik | Kontener na koncie magazynowym. To nie stół. |
| Microsoft Fabric OneLake | Tabela lub folder | Odpowiada skonfigurowanemu typowi ścieżki dla punktu końcowego. |
| Azure Data Explorer | Tabela | Tabela w bazie danych usługi Azure Data Explorer. |
| Magazyn lokalny | Folder | Nazwa folderu lub katalogu w instalacji woluminu trwałego magazynu lokalnego. W przypadku korzystania z usługi Azure Container Storage, którą można włączać dzięki woluminom usługi Azure Arc Cloud Ingest Edge, musi to być zgodne z parametrem spec.path utworzonego podwoluminu. |
| OpenTelemetry | Temat | Temat OpenTelemetry, w którym są wysyłane dane. Obsługiwane są tylko tematy statyczne. |
Aby skonfigurować miejsce docelowe danych:
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
W przypadku korzystania ze środowiska operacji pole miejsca docelowego danych jest automatycznie interpretowane na podstawie typu punktu końcowego. Jeśli na przykład punkt końcowy przepływu danych jest punktem końcowym magazynu, na stronie szczegółów docelowych zostanie wyświetlony monit o wprowadzenie nazwy kontenera. Jeśli punkt końcowy przepływu danych jest punktem końcowym MQTT, strona szczegółów miejsca docelowego wyświetli monit o wprowadzenie tematu itd.

Tematy dotyczące dynamicznego miejsca docelowego
W przypadku punktów końcowych MQTT można użyć dynamicznych zmiennych tematu dataDestination w polu do kierowania komunikatów na podstawie struktury tematu źródłowego. Dostępne są następujące zmienne:
-
${inputTopic}- Pełny oryginalny temat wejściowy -
${inputTopic.index}- Segment tematu wejściowego (indeks zaczyna się od 1)
Na przykład processed/factory/${inputTopic.2} kieruje komunikaty z factory/1/data do processed/factory/1. Segmenty tematów są indeksowane od 1, a ukośniki wiodące/końcowe są ignorowane.
Jeśli nie można rozpoznać zmiennej tematu (na przykład jeśli ${inputTopic.5} temat wejściowy zawiera tylko trzy segmenty), komunikat zostanie porzucony i zostanie zarejestrowane ostrzeżenie. Symbole wieloznaczne (# i +) nie są dozwolone w tematach docelowych.
Uwaga / Notatka
Znaki $, {i } są prawidłowe w nazwach tematów MQTT, więc temat podobny factory/$inputTopic.2 do tego jest akceptowalny, ale niepoprawny, jeśli zamierzasz użyć dynamicznej zmiennej tematu.
Przykład
W poniższym przykładzie przedstawiono konfigurację przepływu danych, która używa punktu końcowego MQTT dla źródła i miejsca docelowego. Źródło filtruje dane z tematu MQTT azure-iot-operations/data/thermostat. Przekształcenie konwertuje temperaturę na Fahrenheit i filtruje dane, w których temperatura pomnożona przez wilgotność jest mniejsza niż 100000. Miejsce docelowe wysyła dane do tematu factoryMQTT .
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)

Aby wyświetlić więcej przykładów konfiguracji przepływu danych, znajdziesz je w Interfejsie API REST platformy Azure — przepływ danych i Szybki start Bicep.
Sprawdzanie, czy przepływ danych działa
Skorzystaj z samouczka: most dwukierunkowy MQTT do usługi Azure Event Grid, aby sprawdzić, czy przepływ danych działa.
Eksportowanie konfiguracji przepływu danych
Aby wyeksportować konfigurację przepływu danych, możesz użyć środowiska operacji lub wyeksportować niestandardowy zasób przepływu danych.
- Środowisko operacji
- Interfejs wiersza polecenia platformy Azure
- Biceps
- Kubernetes (wersja zapoznawcza)
Wybierz przepływ danych, który chcesz wyeksportować, i wybierz pozycję Eksportuj na pasku narzędzi.
Właściwa konfiguracja przepływu danych
Aby upewnić się, że przepływ danych działa zgodnie z oczekiwaniami, sprawdź następujące kwestie:
- Domyślny punkt końcowy przepływu danych MQTT musi być używany jako źródło lub miejsce docelowe.
- Profil przepływu danych istnieje i jest przywołyny w konfiguracji przepływu danych.
- Źródło to punkt końcowy MQTT, punkt końcowy platformy Kafka lub zasób. Punktów końcowych typu magazynu nie można używać jako źródła.
- W przypadku używania usługi Event Grid jako źródła liczba wystąpień profilu przepływu danych jest ustawiona na 1, ponieważ broker MQTT usługi Event Grid nie obsługuje subskrypcji udostępnionych.
- W przypadku używania usługi Event Hubs jako źródła, każdy hub zdarzeń w przestrzeni nazwowej jest osobnym tematem Kafka i musi być określony jako źródło danych.
- Przekształcenie, jeśli jest używane, jest skonfigurowane z właściwą składnią, w tym prawidłowe ucieczki znaków specjalnych.
- Podczas używania punktów końcowych typu magazynu jako miejsca docelowego określa się schemat.
- W przypadku korzystania z dynamicznych tematów docelowych dla punktów końcowych MQTT upewnij się, że zmienne tematu odwołują się do prawidłowych segmentów.