Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The concept of multi-tenancy in Azure Data Explorer refers to serving different tenants and storing their data in a single cluster.
Important
A multitenant solution can also be architected in Microsoft Fabric's Real-Time Intelligence workload, using KQL databases inside an Eventhouse.
A tenant can represent a customer, a group of users, or any classifications of users where data needs to be segregated along the tenants boundaries. You can also have multilevel multitenancy scenario, such as multiple applications that each have multiple tenants. This article doesn't cover this scenario, but similar principles apply.
An important factor is the way end-users access their tenant data. When end-users access Azure Data Explorer directly, access control must be configured in Azure Data Explorer to isolate the user's view to their own data. When a proxy application accesses their data in Azure Data Explorer, the application can do the isolation.
This article describes some deployment architectures and provides characteristics for each. You can use the characteristics to help you decide which architecture works best for your solution.
Noisy neighbor
In general, sharing a cluster among many tenants, regardless of the architecture used, means different tenants share the cluster's resources. This can lead to the noisy neighbor antipattern.
For instance, if a tenant performs many compute-intensive queries or ingestions, other tenants are likely to be impacted by resource starvation. This can be mitigated by using workload groups. You can also use policies to control caching and overall storage.
Architectures overview
The next sections explore deployment architectures in detail. This section contrasts the architectures to facilitate decision making.
| Architecture | Strengths |
|---|---|
| One tenant per database | - Tenants' isolation: no need for proxy - Can have different policies, such as retention policies, per tenant - Flexibility in schema evolution per tenant - Easy and quick removal of tenant data |
| One table for many tenants | - Efficient data consolidation and extent management - Simplified schema evolution - Best suited for materialized views - Ideal for partitioning |
| One tenant per table in a single database | Not recommended |
Architecture: One tenant per database
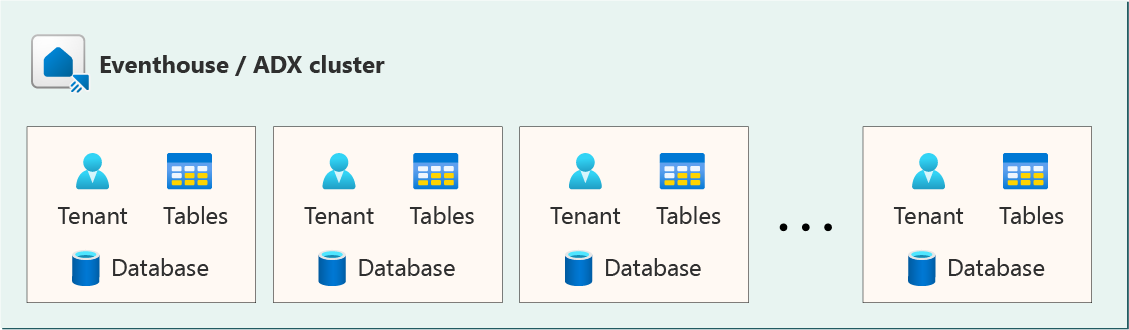
This is a popular and straight forward architecture. Each tenant gets its own database. Each database has the same schema.
The characteristics of this architecture are:
Provisioning a new tenant: Requires creating a new database and deploying schema entities on it.
Removing a tenant: Requires deleting the database. Deleting a database can be done in a few seconds. Consumes little and constant resources that aren't linear with tenant's data volume.
Database schemas updates: Each tenant can be independently updated at different times. Applications that access the databases must be aware of the version of each database they interact with.
Retention and caching policies: Each tenant can have its own unique policies, which enable you to provide custom retention and caching policies to your customers.
Security boundary per tenant:
- For multitenant application (proxy): Configure your application to target the relevant database. Use access restriction on queries to prohibit cross-database queries.
- For users with direct access: Users can be granted access at the database level. Giving users direct access to their database creates a dependency for the implementation details, making it difficult to change the implementation. Therefore, we strongly recommend using the proxy approach for accessing the database.
Aggregating data from multiple tenants at scale: Use the union operator to aggregate data between databases. However, this method can become cumbersome as the number of tenants increases. Even though aggregating data from multiple tenants might be a design goal from the tenant's perspective, it might be of interest for solution owner to aggregate data from all tenants to gather statistics.
Extents fragmentation: Each tenant ingesting a few records per database table leads to the creation of small extents that later need to be merged. This results in higher cost for extent management. Therefore, we strongly recommend using streaming ingestion, such as Event Hubs or Event Grid ingestion. To use streaming ingestion, you must make sure it's enabled on the cluster and table.
Materialized views and partitioning policy. As number of tenants increases, it's important to remember that there are limits to the number of materialized views and partition policies a cluster can run efficiently.
Event Grid and Event Hubs data connections: These data connections are created per database. Therefore, this architecture requires a data connection and Event Grid or Event Hubs instance per tenant, which adds management complexity. Consider using event routing for Event Hubs and Event Grid.
Architecture: One table for many tenants
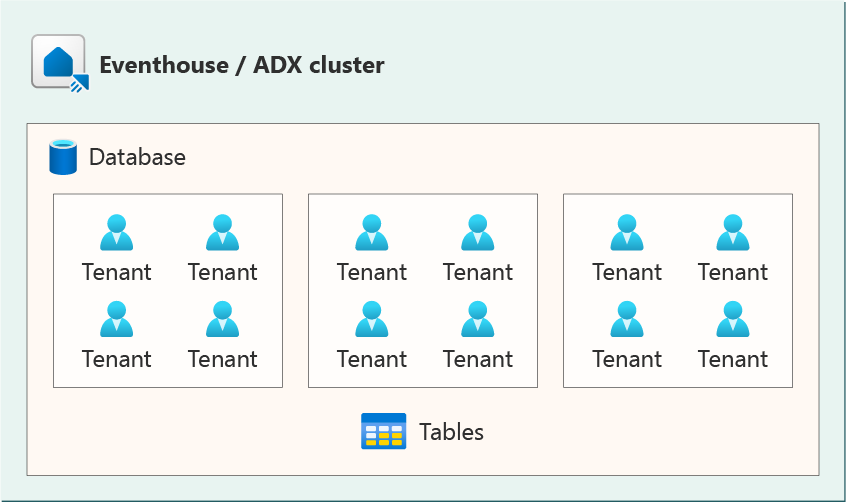
This architecture is more aggressive in its consolidation, using a single database for all tenants. Each table in the database has a Tenant ID column, or equivalent, which allows for filtering for a single tenant's data. You can partition tables by tenant to improve query performance, since most queries are likely to filter by tenant. Where possible, you should consider partition with another column using a compound partition key. For example, you can create a compound partition key concatenating the tenant ID and another columns' values.
The characteristics of this architecture are:
Provisioning a new tenant: Provisioning a new tenant doesn't require any database creation or schema adjustment. The new tenant ID is used in new records.
Removing a tenant: Requires a soft delete or purge of the tenant's data. You can batch multiple purges together, for example, at the end of week to limit the impact on resource consumption.
Database schemas updates: All tenants' schema are upgraded at the same time. Since all tenants share table, changing table schemas changes all tenants at once.
Retention and caching policies: The policies are the same for all tenants since they all share the same table.
Security boundary per tenant:
- For multitenant application (proxy): Use the Restrict statement
- For users with direct access: Use the Row Level Security Policy and familiarize yourself with its limitations. Giving users direct access to their database creates a dependency for the implementation details, making it difficult to change the implementation. Therefore, we strongly recommend using the proxy approach for accessing the database.
Aggregating data from multiple tenants at scale: Users with the sufficient access permissions can run a standard aggregation query on multiple tenants' data.
Extents fragmentation: Since all tenants ingest data into the same table, data can usually be consolidated and efficiently ingested in one, or a few, extents.
Materialized views and partitioning policy: These can be used on multitenant table. You can improve performance by partitioning on the Tenant ID, or equivalent, column. For more information, see Scenarios for partition policies.
Event Grid and Event Hubs data connections: You consolidated data connections since data for all tenants ends up in one table.
Architecture: One tenant per table in a single database
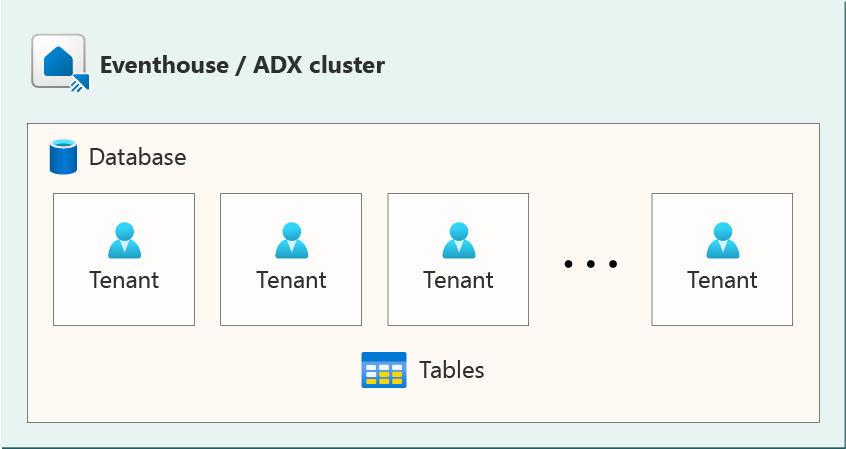
This architecture is a combination of the previous architectures where the data of all tenants ends up in a single database but separate tables. This architecture fails to capture all the advantages of the other architectures.
Although each tenant's data is segregated, they all reside in the same security context of the same database. Like the multi-database architecture, this architecture can lead to extent fragmentation. The table name is different for each tenant and therefore the queries must be customized for each tenant.