توضح هذه المقالة كيفية استخدام نشاط النسخ فيAzure Data Factory أو تدفقات تحليلات Synapse لنسخ البيانات من Spark. تعتمد هذه المقالة على مقالة نظرة عامة على نشاط النسخ التي تقدم نظرة عامة على نشاط النسخ.
① وقت تشغيل تكامل Azure ② وقت تشغيل التكامل المستضاف ذاتيًا
للحصول على قائمة بمخازن البيانات المدعومة كمصادر/متلقيات بواسطة نشاط النسخ، راجع جدول مخازن البيانات المدعومة.
توفر الخدمة برنامج تشغيل مضمناً لتمكين الاتصال، وبالتالي لا تحتاج إلى تثبيت أي برنامج تشغيل يدوياً باستخدام هذا الموصل.
المتطلبات الأساسية
إذا كان مخزن البيانات الخاص بك موجوداً داخل شبكة محلية، أو شبكة Azure ظاهرية، أو Amazon Virtual Private Cloud، فأنت بحاجة إلى تكوين وقت تشغيل تكامل مستضاف ذاتياً للاتصال به.
إذا كان مخزن البيانات الخاص بك عبارة عن خدمة بيانات سحابية مُدارة، يمكنك استخدام Azure Integration Runtime. إذا كان الوصول مقتصراً على عناوين IP التي تمت الموافقة عليها في قواعد جدار الحماية، يمكنك إضافة عناوين IP لـ Azure Integration Runtime إلى قائمة السماح.
يمكنك أيضاً استخدام ميزة وقت تشغيل تكامل الشبكة الظاهرية المُدارة في Azure Data Factory للوصول إلى الشبكة المحلية دون تثبيت وقت تشغيل تكامل مستضاف ذاتياً وتكوينه.
يحدد ما إذا كانت الاتصالات بالخادم مشفرة باستخدام TLS. القيمة الافتراضية هي false.
لا
trustedCertPath
المسار الكامل لملف .pem الذي يحتوي على شهادات CA موثوق بها للتحقق من الملقم عند الاتصال عبر TLS. يمكن تعيين هذه الخاصية فقط عند استخدام TLS على وقت تشغيل التكامل المستضاف ذاتيًا. القيمة الافتراضية هي ملف cacerts.pem المثبت مع وقت تشغيل التكامل.
لا
useSystemTrustStore
تحديد ما إذا كنت تريد استخدام شهادة CA من مخزن الثقة بالنظام أو من ملف PEM محدد. القيمة الافتراضية هي false.
لا
allowHostNameCNMismatch
تحدد ما إذا كنت تريد طلب اسم شهادة TLS / SSL الصادرة عن CA لمطابقة اسم مضيف الملقم عند الاتصال عبر TLS. القيمة الافتراضية هي false.
لا
allowSelfSignedServerCert
يحدد ما إذا كان سيتم السماح بشهادات موقعة ذاتياً من الخادم. القيمة الافتراضية هي false.
لا
connectVia
Integration Runtime الذي سيتم استخدامه للاتصال بمخزن البيانات. تعرف على المزيد من قسم المتطلبات الأساسية. إذا لم يتم تحديده، فإنه يستخدم Azure Integration Runtime الافتراضي.
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف مجموعات البيانات، راجع مقالة مجموعات البيانات. يوفر هذا القسم قائمة بالخصائص التي تدعمها مجموعة بيانات Spark.
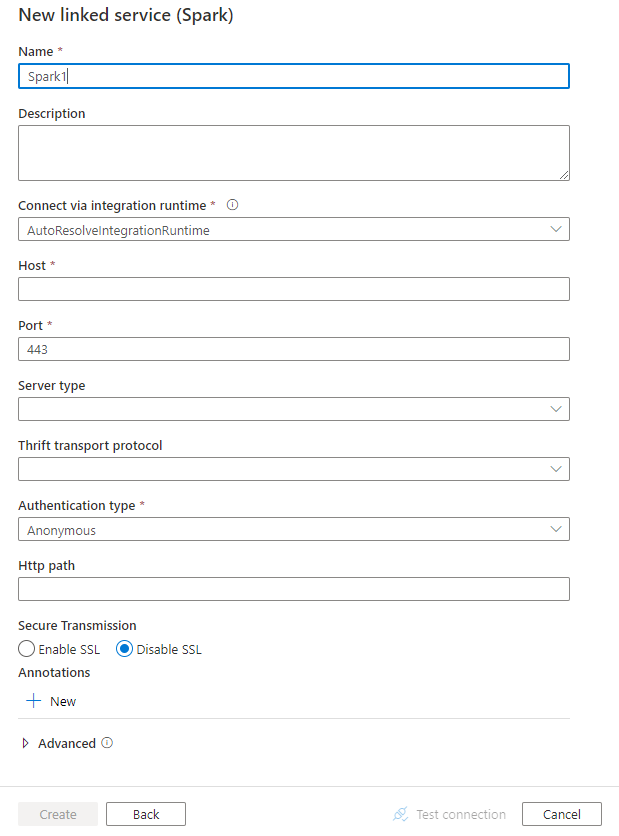
لنسخ البيانات من Spark، قم بتعيين خاصية نوع مجموعة البيانات إلى SparkObject. تدعم الخصائص التالية:
الخاصية
الوصف
مطلوب
النوع
يجب تعيين خاصية نوع مجموعة البيانات إلى: SparkObject
نعم
Schema
اسم المخطط.
لا (إذا تم تحديد "الاستعلام" في مصدر النشاط)
طاولتنا
ضع اسمًا للجدول.
لا (إذا تم تحديد "الاستعلام" في مصدر النشاط)
اسم الجدول
اسم الجدول مع المخطط. هذه الخاصية مدعومة للتوافق مع الإصدارات السابقة. استخدم schema وtable لأحمال العمل الجديدة.
تعرف على كيفية تحويل البيانات من خلال تشغيل برامج Spark من Azure Data Factory أو البنية الأساسية لبرنامج ربط العمليات التجارية لـ Synapse باستخدام نشاط Spark.
تعرف على كيفية استخدام المسارات والأنشطة في Azure Data Factory وAzure Synapse Analytics لإنشاء مهام سير عمل تعتمد على البيانات لسيناريوهات نقل البيانات ومعالجتها.
 Azure Data Factory
Azure Data Factory