Oktatás
Modul
Use Power Query to load data in Dataverse - Training
Learn how to synchronize data from different sources to a Microsoft Dataverse table using Power Query and create dataflows in Power Apps.
Ezt a böngészőt már nem támogatjuk.
Frissítsen a Microsoft Edge-re, hogy kihasználhassa a legújabb funkciókat, a biztonsági frissítéseket és a technikai támogatást.
| Elem | Leírás |
|---|---|
| Kiadási állapot | Általános rendelkezésre állás |
| Termékek | Excel Power BI (Szemantikai modellek) Power BI (Adatfolyamok) Háló (Adatfolyam Gen2) Power Apps (Adatfolyamok) Dynamics 365 Customer Insights Analysis Services |
| Függvényreferenciák dokumentációja | File.Contents Lines.FromBinary Csv.Document |
Megjegyzés
Egyes képességek egy termékben lehetnek jelen, másokat azonban az üzembehelyezési ütemezések és a gazdagépspecifikus képességek miatt.
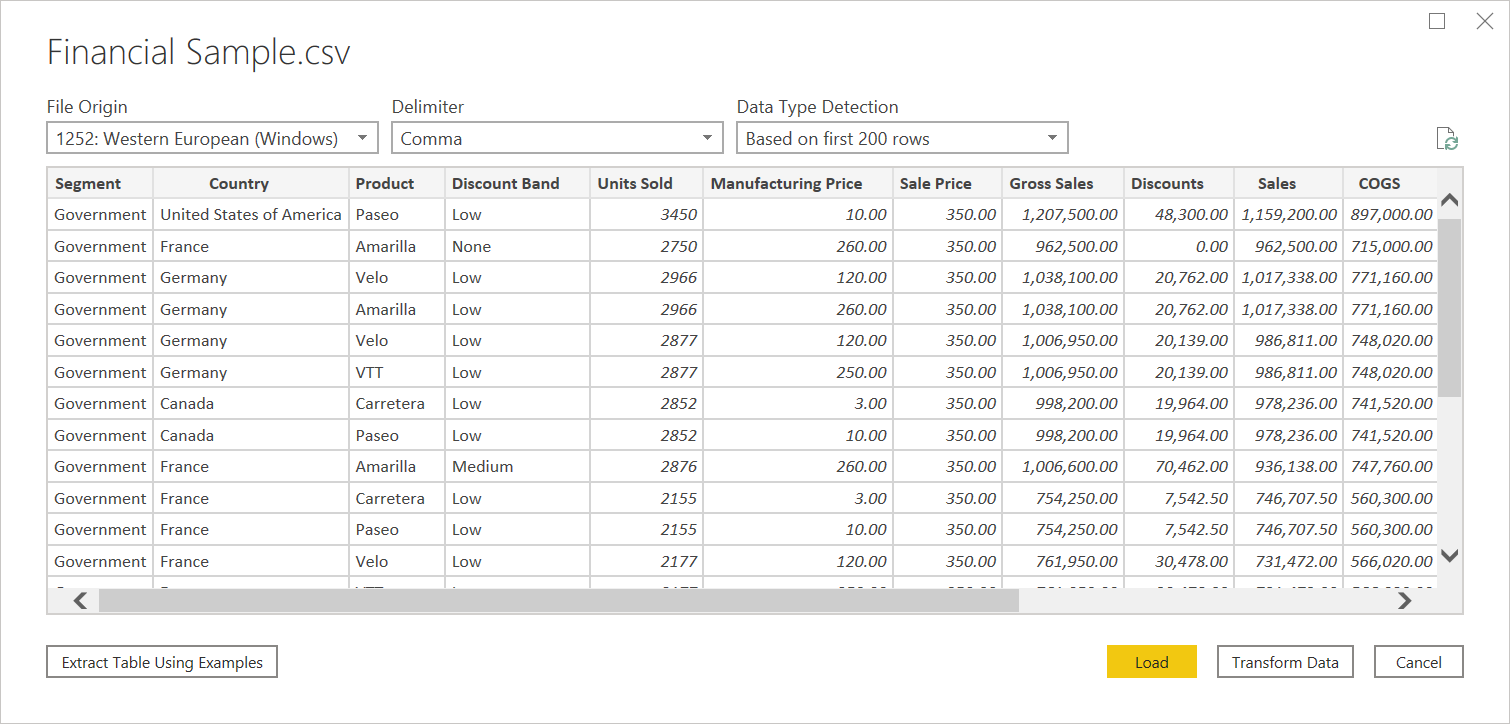
Helyi szöveg vagy CSV-fájl betöltése:
Válassza a Szöveg/CSV lehetőséget az Adatok lekérése területen. Ez a művelet elindít egy helyi fájlböngészőt, ahol kiválaszthatja a szövegfájlt.

Az Open (Megnyitás) kiválasztásával nyissa meg a fájlt.
A Kezelőben átalakíthatja a Power Query-szerkesztő adatait az Adatok átalakítása lehetőség kiválasztásával, vagy betöltheti az adatokat a Betöltés lehetőség kiválasztásával.
Helyi szöveg vagy CSV-fájl betöltése:
Az Adatforrások lapon válassza a Szöveg/CSV lehetőséget.
A Csatlakozás ion beállításai között adja meg a kívánt helyi szöveg vagy CSV-fájl elérési útját.
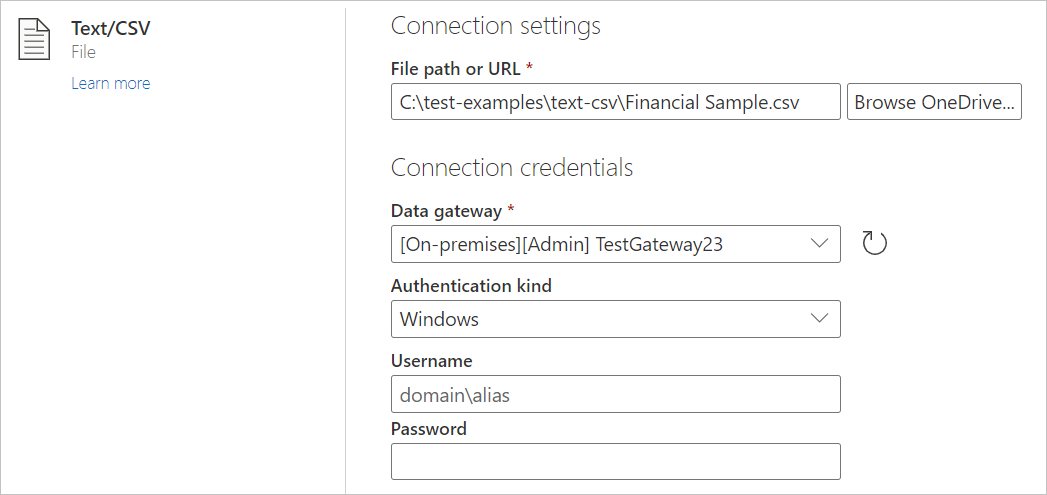
Válasszon ki egy helyszíni adatátjárót a Data Gatewayből.
Adjon meg egy felhasználónevet és a jelszót.
Válassza a Tovább lehetőséget.
A Kezelőben válassza az Adatok átalakítása lehetőséget az adatok átalakításának megkezdéséhez a Power Query-szerkesztő.
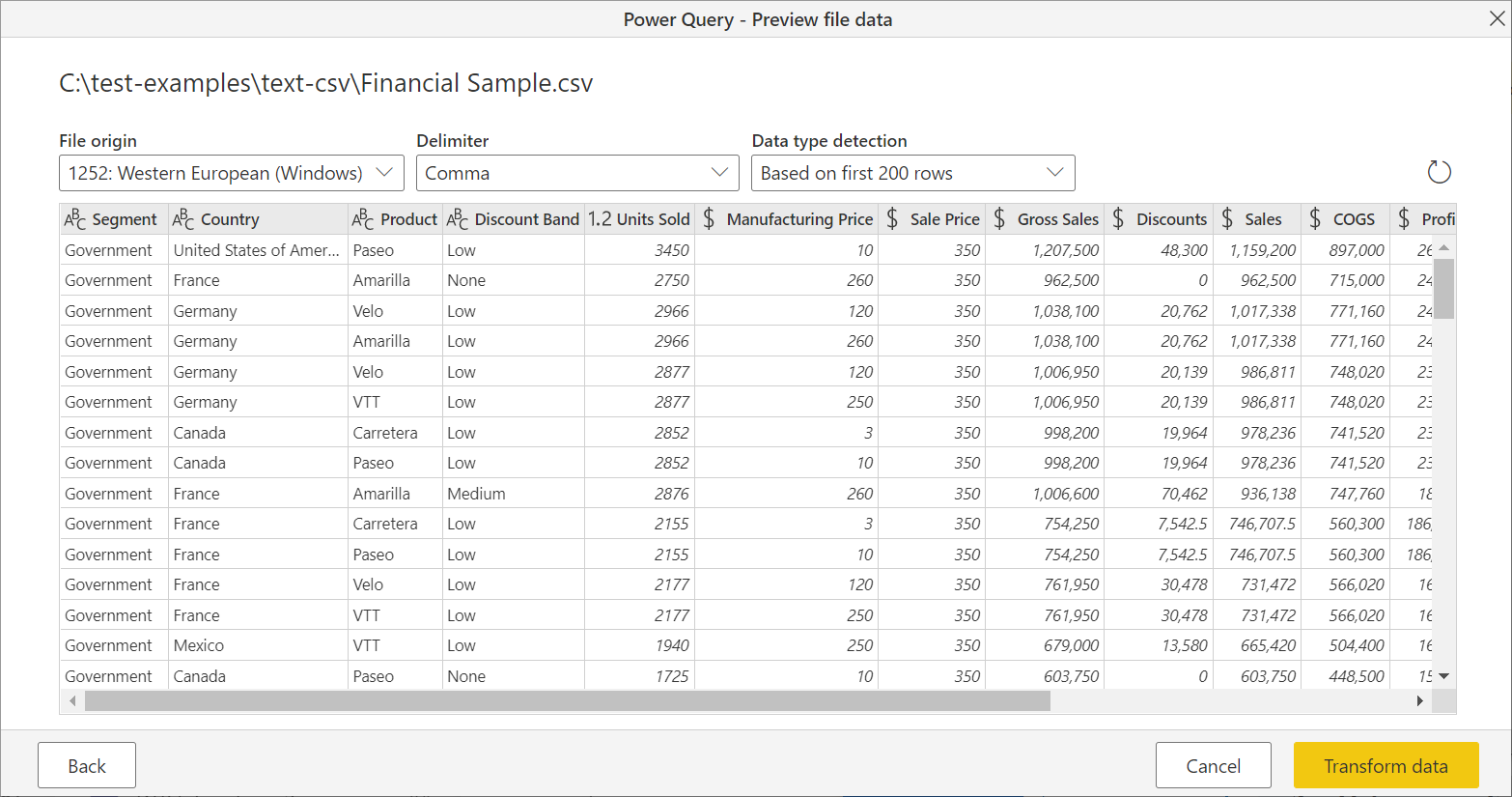
Ha szöveget vagy CSV-fájlt szeretne betölteni a weből, jelölje ki a webes összekötőt, adja meg a fájl webcímét, és kövesse a hitelesítő adatokra vonatkozó utasításokat.
A Power Query strukturált fájlként kezeli a CSV-ket, vesszővel elválasztóként – egy szövegfájl különleges eseteként. Ha szövegfájlt választ, a Power Query automatikusan megkísérli megállapítani, hogy van-e elválasztott elválasztójele, és hogy mi az a határoló. Ha elválasztójelet tud kikövetkeztetni, automatikusan strukturált adatforrásként fogja kezelni.
Ha a szövegfájl nem rendelkezik struktúrával, egyetlen oszlopot fog kapni, amely soronként egy új sort tartalmaz, amely a forrásszövegben van kódolva. Strukturálatlan szöveg mintájaként a következő tartalommal rendelkező jegyzettömbfájlt tekintheti meg:
Hello world.
This is sample data.
Amikor betölti, megjelenik egy navigációs képernyő, amely az egyes sorokat a saját sorába tölti be.
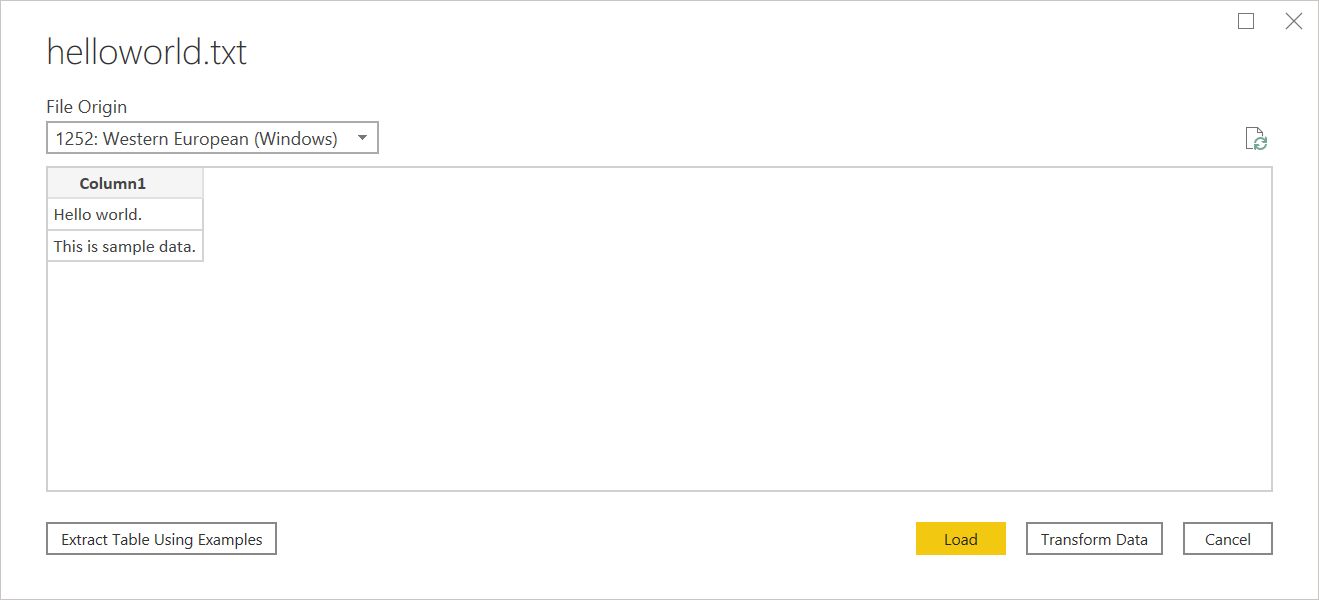
Ezen a párbeszédpanelen csak egy dolgot konfigurálhat, amely a Fájl eredete legördülő lista kiválasztása. Ezzel a legördülő listával kiválaszthatja , hogy melyik karakterkészletet használta a fájl létrehozásához. A karakterkészlet jelenleg nincs kikövetkeztetve, és az UTF-8 csak akkor lesz kikövetkeztetve, ha az UTF-8 anyagjegyzékkel kezdődik.

A CSV a fájl eredetén kívül az elválasztó és az adattípus-észlelés kezelését is támogatja.
Az elérhető elválasztójelek közé tartozik a kettőspont, a vessző, az egyenlőségjel, a pontosvessző, a szóköz, a tab, az egyéni elválasztó (amely bármilyen sztring lehet) és egy rögzített szélesség (a szöveg felosztása bizonyos karakterek számával).

Az utolsó legördülő menüben kiválaszthatja, hogyan szeretné kezelni az adattípus-észlelést. Ez az első 200 sor alapján, a teljes adatkészleten elvégezhető, vagy dönthet úgy, hogy nem végzi el az automatikus adattípus-észlelést, és ehelyett az összes oszlopot alapértelmezés szerint "Szöveg" értékre állítja. Figyelmeztetés: ha a teljes adatkészleten hajtja végre, előfordulhat, hogy az adatok kezdeti betöltése a szerkesztőben lassabb lesz.

Mivel a következtetés helytelen lehet, a betöltés előtt érdemes duplán ellenőrizni a beállításokat.
Ha a Power Query észleli a szövegfájl struktúráját, elválasztó elválasztott értékfájlként fogja kezelni a szövegfájlt, és ugyanazokat a lehetőségeket adja meg, mint a CSV megnyitásakor – ami lényegében csak egy fájl, amely a határoló típusát jelző kiterjesztéssel rendelkezik.
Ha például a következő példát szövegfájlként menti, az strukturálatlan szöveg helyett tabulátorként jelenik meg.
Column 1 Column 2 Column 3
This is a string. 1 ABC123
This is also a string. 2 DEF456
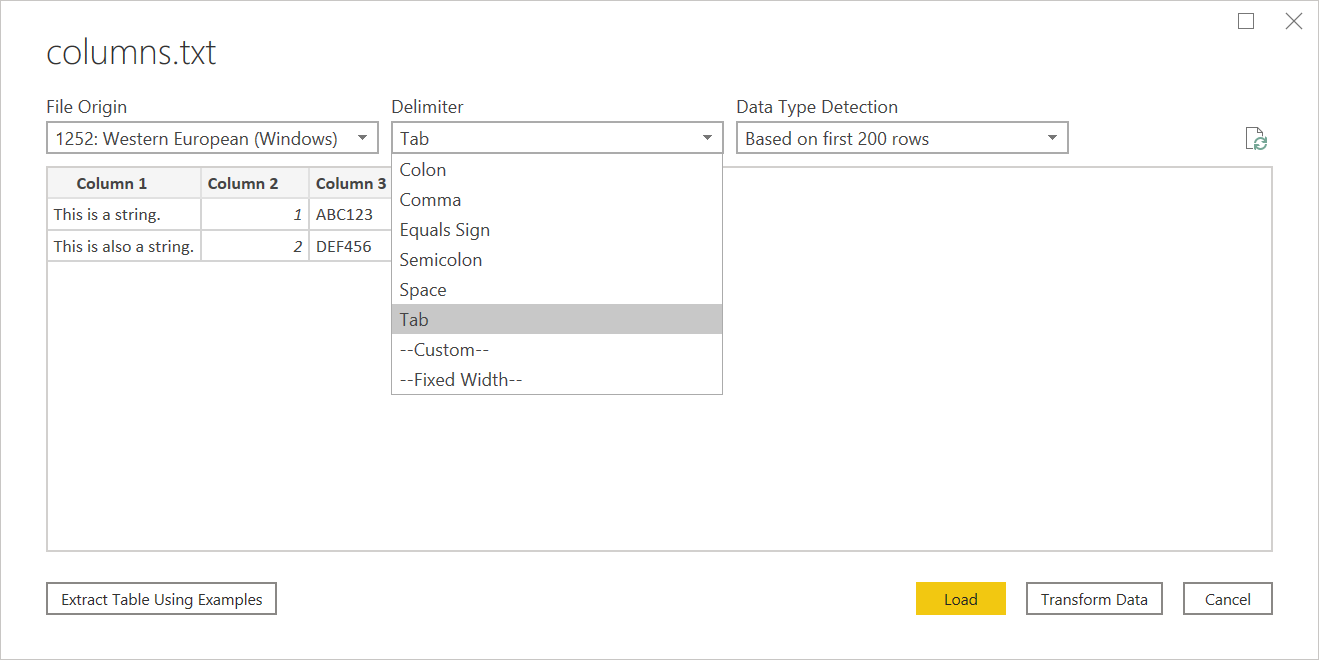
Ez bármilyen más elválasztóalapú fájlhoz használható.
A forráslépés szerkesztésekor kissé eltérő párbeszédpanel jelenik meg, mint a kezdeti betöltéskor. Attól függően, hogy jelenleg miként kezeli a fájlt (azaz szöveget vagy csv-t), számos legördülő menüt tartalmazó képernyő jelenik meg.
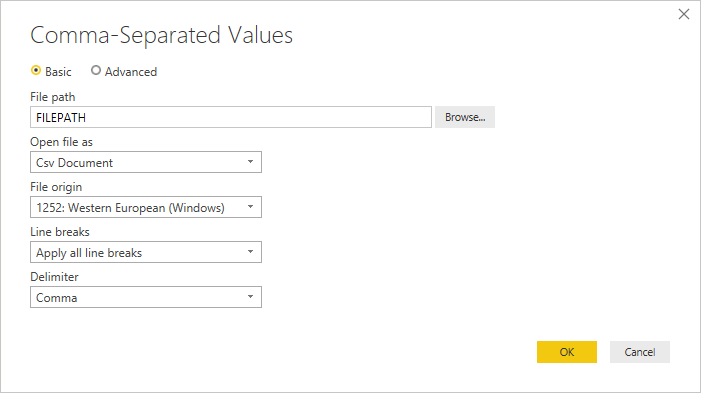
A Sortörések legördülő listában kiválaszthatja, hogy idézőjelek között lévő sortöréseket szeretne-e alkalmazni.

Ha például a fent megadott "strukturált" mintát szerkessze, hozzáadhat egy sortörést.
Column 1 Column 2 Column 3
This is a string. 1 "ABC
123"
This is also a string. 2 "DEF456"
Ha a sortörések figyelmen kívül hagyása értékre vannak beállítva, akkor úgy fog betöltődni, mintha nem lett volna sortörés (plusz szóközzel).

Ha a sortörések az Összes sortörés alkalmazása beállításra van beállítva, akkor egy további sort tölt be, és a sortörések utáni tartalom az egyetlen tartalom ebben a sorban (a pontos kimenet a fájl tartalmának szerkezetétől függhet).

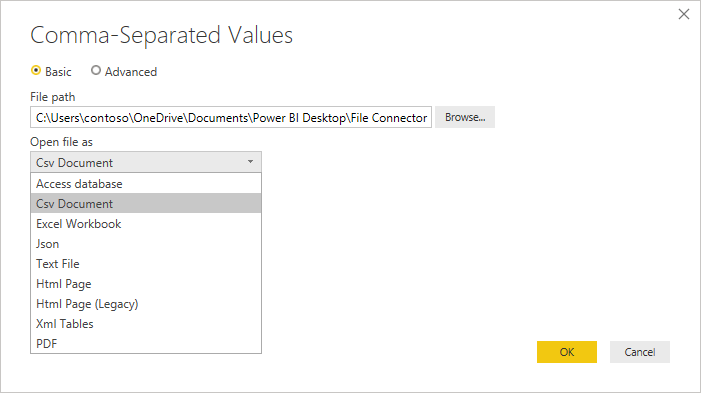
A Fájl megnyitása legördülő menüben szerkesztheti, hogy mit szeretne betölteni a fájlban– ez fontos a hibaelhárításhoz. Olyan strukturált fájlok esetében, amelyek technikailag nem CSV-k (például egy tabulátorral tagolt értékfájl, amelyet szövegfájlként mentettek), akkor is csv-hez beállított Open fájlnak kell lennie. Ez a beállítás azt is meghatározza, hogy mely legördülő listák érhetők el a párbeszédpanel többi részében.
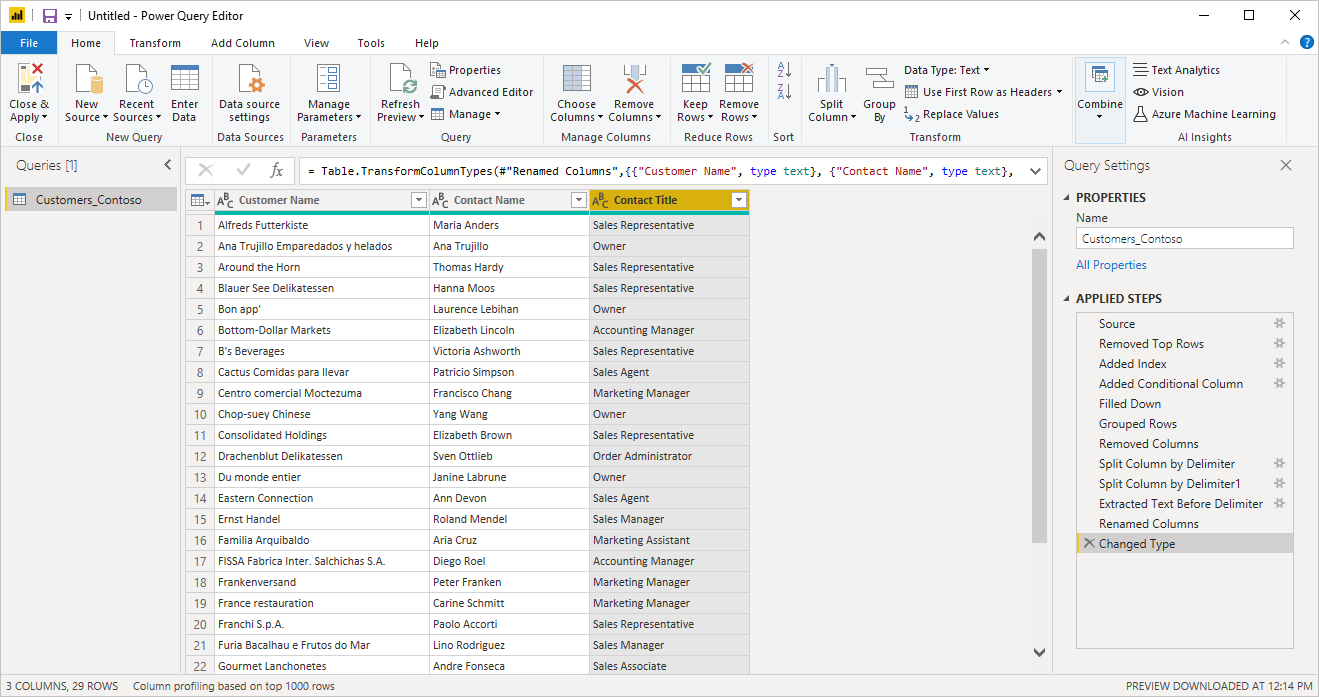
A Power Queryben a Text/CSV By Example egy általánosan elérhető funkció a Power BI Desktopban és a Power Query Online-ban. A Szöveg/CSV-összekötő használatakor megjelenik egy lehetőség a táblázat kinyerésére példák használatával a kezelő bal alsó sarkában.

Ha ezt a gombot választja, a rendszer a Tábla kinyerése példák használatával lapra kerül. Ezen a lapon megadhatja a szöveg-/CSV-fájlból kinyerni kívánt adatok kimeneti mintaértékeit. Miután beírta az oszlop első celláját, az oszlop többi celláját is kitölti a rendszer. Előfordulhat, hogy az adatok helyes kinyeréséhez több cellát is be kell írnia az oszlopba. Ha az oszlop egyes cellái helytelenek, kijavíthatja az első helytelen cellát, és az adatok ismét kinyerhetők. Ellenőrizze az első néhány cellában lévő adatokat, hogy az adatok kinyerése sikeresen megtörtént-e.
Megjegyzés
Javasoljuk, hogy a példákat oszlopsorrendben adja meg. Miután sikeresen kitöltötte az oszlopot, hozzon létre egy új oszlopot, és kezdjen el példákat beírni az új oszlopba.

Miután elkészült a tábla összeállításával, kiválaszthatja az adatok betöltését vagy átalakítását. Figyelje meg, hogy az eredményként kapott lekérdezések hogyan tartalmazzák az adatkinyeréshez levont összes lépés részletes lebontását. Ezek a lépések csak rendszeres lekérdezési lépések, amelyeket igény szerint testre szabhat.
Ha szöveges/csv-fájlokat kér az internetről, és a fejléceket is támogatja, és elég fájlt kér le, amelyet a lehetséges szabályozással kell foglalkoznia, fontolja meg a hívás körbefuttatását Web.ContentsBinary.Buffer(). Ebben az esetben a fájl fejlécek előléptetése előtt történő pufferelése miatt a fájl csak egyszer kérhető le.
Ha nagy CSV-fájlokkal dolgozik a Power Query Online szerkesztőjében, belső hiba jelenhet meg. Javasoljuk, hogy először egy kisebb méretű CSV-fájllal dolgozzon, alkalmazza a lépéseket a szerkesztőben, és ha végzett, módosítsa a nagyobb CSV-fájl elérési útját. Ezzel a módszerrel hatékonyabban dolgozhat, és csökkentheti az időtúllépés esélyét az online szerkesztőben. Nem számítunk arra, hogy ez a hiba a frissítés ideje alatt jelenik meg, mivel hosszabb időtúllépési időtartamot engedélyezünk.
Ritkán egy olyan dokumentumot, amely a bekezdések vesszőihez hasonló számokkal rendelkezik, CSV-nek tekinthető. Ha ez a probléma jelentkezik, szerkessze a Forrás lépést a Power Query-szerkesztőben, és válassza a Szöveg lehetőséget CSV helyett a Fájl megnyitása legördülő menüben.
CSV-fájl importálásakor a Power BI Desktop létrehoz egy x oszlopot (ahol x a CSV-fájl oszlopainak száma a kezdeti importálás során) a Power Query-szerkesztő lépéseként. Ha később további oszlopokat ad hozzá, és az adatforrás frissítésre van beállítva, a kezdeti x oszlopszámon túli oszlopok nem frissülnek.
Amikor szöveges/CSV-fájlokat tölt be egy webes forrásból, és az élőfejeket is támogatja, előfordulhat, hogy a következő hibákat tapasztalja: "An existing connection was forcibly closed by the remote host" vagy "Received an unexpected EOF or 0 bytes from the transport stream." ezeket a hibákat a védelmi intézkedéseket alkalmazó gazdagép okozhatja, és bezárhat egy kapcsolatot, amely ideiglenesen szüneteltethető, például amikor egy másik adatforrás-kapcsolatra vár egy illesztési vagy hozzáfűzési műveletre. A hibák megkerüléséhez próbáljon meg hozzáadni egy Binary.Buffer (ajánlott) vagy Table.Buffer hívást, amely letölti a fájlt, betölti a memóriába, és azonnal bezárja a kapcsolatot. Ez megakadályozza a letöltés közbeni szüneteltetéseket, és megakadályozza, hogy a gazdagép kényszerítve zárja be a kapcsolatot a tartalom lekérése előtt.
Az alábbi példa ezt a megkerülő megoldást szemlélteti. Ezt a pufferelést el kell végezni, mielőtt az eredményként kapott táblát átadják a Table.PromoteHeadersnek.
Csv.Document(Web.Contents("https://.../MyFile.csv"))
Binary.Buffer:Csv.Document(Binary.Buffer(Web.Contents("https://.../MyFile.csv")))
Table.Buffer:Table.Buffer(Csv.Document(Web.Contents("https://.../MyFile.csv")))
Oktatás
Modul
Use Power Query to load data in Dataverse - Training
Learn how to synchronize data from different sources to a Microsoft Dataverse table using Power Query and create dataflows in Power Apps.