Den här artikeln beskriver hur du använder kopieringsaktiviteten i en Azure Data Factory- eller Synapse Analytics-pipeline för att kopiera data från Spark. Den bygger på översiktsartikeln för kopieringsaktivitet som visar en allmän översikt över kopieringsaktiviteten.
Funktioner som stöds
Den här Spark-anslutningsappen stöds för följande funktioner:
En lista över datalager som stöds som källor/mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Tjänsten tillhandahåller en inbyggd drivrutin för att aktivera anslutningen. Därför behöver du inte installera någon drivrutin manuellt med den här anslutningsappen.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Komma igång
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Spark-anslutningsappen.
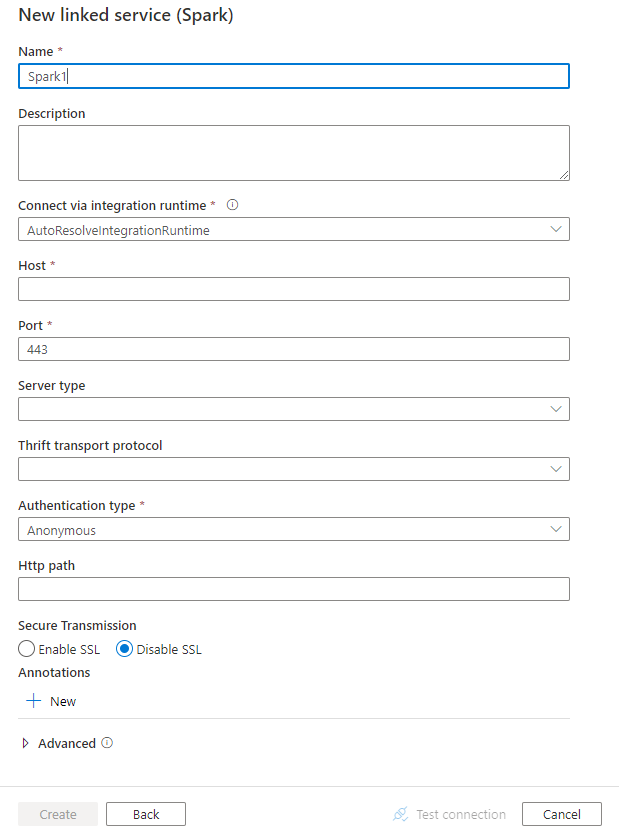
Länkade tjänstegenskaper
Följande egenskaper stöds för spark-länkad tjänst:
Property
Beskrivning
Obligatoriskt
type
Typegenskapen måste anges till: Spark
Ja
värd
IP-adress eller värdnamn för Spark-servern
Ja
port
TCP-porten som Spark-servern använder för att lyssna efter klientanslutningar. Om du ansluter till Azure HDInsights anger du porten som 443.
Ja
serverType
Typ av Spark-server. Tillåtna värden är: SharkServer, SharkServer2, SparkThriftServer
Nej
thriftTransportProtocol
Transportprotokollet som ska användas i Thrift-lagret. Tillåtna värden är: Binär, SASL, HTTP
Nej
authenticationType
Den autentiseringsmetod som används för att komma åt Spark-servern. Tillåtna värden är: Anonym, Användarnamn, AnvändarnamnAndPassword, WindowsAzureHDInsightService
Ja
användarnamn
Det användarnamn som du använder för att komma åt Spark Server.
Anger om anslutningarna till servern krypteras med hjälp av TLS. Standardvärdet är "false".
Nej
trustedCertPath
Den fullständiga sökvägen till .pem-filen som innehåller betrodda CA-certifikat för att verifiera servern när du ansluter via TLS. Den här egenskapen kan bara anges när du använder TLS på lokalt installerad IR. Standardvärdet är filen cacerts.pem som är installerad med IR.
Nej
useSystemTrustStore
Anger om du vill använda ett CA-certifikat från systemförtroendearkivet eller från en angiven PEM-fil. Standardvärdet är "false".
Nej
allowHostNameCNMismatch
Anger om ett CA-utfärdat TLS/SSL-certifikatnamn ska matcha serverns värdnamn vid anslutning via TLS. Standardvärdet är "false".
Nej
allowSelfSignedServerCert
Anger om självsignerade certifikat ska tillåtas från servern. Standardvärdet är "false".
Nej
connectVia
Integration Runtime som ska användas för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om den inte anges använder den standardkörningen för Azure-integrering.
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Spark-datauppsättningen.
Om du vill kopiera data från Spark anger du datamängdens typegenskap till SparkObject. Följande egenskaper stöds:
Property
Beskrivning
Obligatoriskt
type
Typegenskapen för datamängden måste anges till: SparkObject
Ja
schema
Namnet på schemat.
Nej (om "fråga" i aktivitetskällan har angetts)
table
Tabellens namn.
Nej (om "fråga" i aktivitetskällan har angetts)
tableName
Namnet på tabellen med schemat. Den här egenskapen stöds för bakåtkompatibilitet. Använd schema och table för ny arbetsbelastning.
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Spark-källan.
Spark som källa
Om du vill kopiera data från Spark anger du källtypen i kopieringsaktiviteten till SparkSource. Följande egenskaper stöds i avsnittet kopieringsaktivitetskälla:
Property
Beskrivning
Obligatoriskt
type
Typegenskapen för kopieringsaktivitetskällan måste anges till: SparkSource
Ja
query
Använd den anpassade SQL-frågan för att läsa data. Exempel: "SELECT * FROM MyTable".
Nej (om "tableName" i datauppsättningen har angetts)
Visa förståelse för vanliga datateknikuppgifter för att implementera och hantera arbetsbelastningar för datateknik i Microsoft Azure med hjälp av ett antal Azure-tjänster.
 Azure Data Factory
Azure Data Factory