aktiviteten Kopiera i Azure Data Factory och Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I Azure Data Factory- och Synapse-pipelines kan du använda aktiviteten Kopiera för att kopiera data mellan datalager som finns lokalt och i molnet. När du har kopierat data kan du använda andra aktiviteter för att transformera och analysera dem ytterligare. Du kan också använda aktiviteten Kopiera för att publicera transformerings- och analysresultat för Business Intelligence (BI) och programförbrukning.
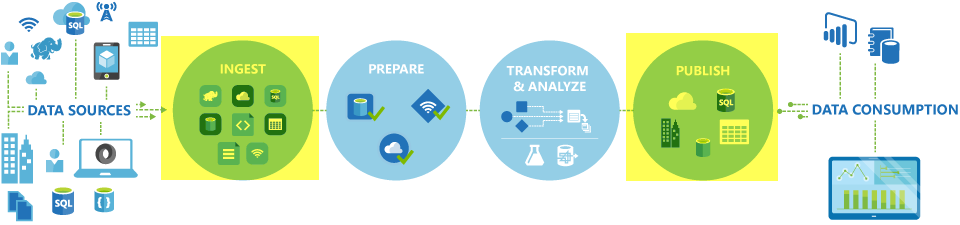
Aktiviteten Kopiera körs på en integrationskörning. Du kan använda olika typer av integreringskörningar för olika scenarier för datakopiering:
- När du kopierar data mellan två datalager som är offentligt tillgängliga via Internet från alla IP-adresser kan du använda Azure Integration Runtime för kopieringsaktiviteten. Den här integreringskörningen är säker, tillförlitlig, skalbar och globalt tillgänglig.
- När du kopierar data till och från datalager som finns lokalt eller i ett nätverk med åtkomstkontroll (till exempel ett virtuellt Azure-nätverk) måste du konfigurera en lokalt installerad integrationskörning.
En integrationskörning måste associeras med varje käll- och mottagardatalager. Information om hur aktiviteten Kopiera avgör vilken integreringskörning som ska användas finns i Fastställa vilken IR som ska användas.
Kommentar
Du kan inte använda mer än en lokalt installerad integrationskörning inom samma aktiviteten Kopiera. Källan och mottagaren för aktiviteten måste vara anslutna till samma lokalt installerade integrationskörning.
Om du vill kopiera data från en källa till en mottagare utför tjänsten som kör aktiviteten Kopiera följande steg:
- Läser data från ett källdatalager.
- Utför serialisering/deserialisering, komprimering/dekomprimering, kolumnmappning och så vidare. Den utför dessa åtgärder baserat på konfigurationen av indatauppsättningen, utdatauppsättningen och aktiviteten Kopiera.
- Skriver data till datalagret mottagare/mål.

Kommentar
Om en lokalt installerad integrationskörning används i antingen ett käll- eller mottagardatalager inom en aktiviteten Kopiera måste både källan och mottagaren vara tillgängliga från servern som är värd för integreringskörningen för att aktiviteten Kopiera ska lyckas.
Datalager och format som stöds
Kommentar
Om en anslutningsapp är märkt med förhandsversion kan du testa den och sedan ge feedback till oss. Om du vill skapa ett beroende på anslutningsappar som är i förhandsversion i din lösning kontaktar du Azure-supporten.
Filformat som stöds
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
- Avro-format
- Binärt format
- Avgränsat textformat
- Excel-format
- Iceberg-format (endast för Azure Data Lake Storage Gen2)
- JSON-format
- ORC-format
- Parquet-format
- XML-format
Du kan använda aktiviteten Kopiera för att kopiera filer som de är mellan två filbaserade datalager, i vilket fall data kopieras effektivt utan serialisering eller deserialisering. Dessutom kan du även parsa eller generera filer i ett visst format, till exempel kan du utföra följande:
- Kopiera data från en SQL Server-databas och skriv till Azure Data Lake Storage Gen2 i Parquet-format.
- Kopiera filer i textformat (CSV) från ett lokalt filsystem och skriv till Azure Blob Storage i Avro-format.
- Kopiera zippade filer från ett lokalt filsystem, dekomprimera dem direkt och skriv extraherade filer till Azure Data Lake Storage Gen2.
- Kopiera data i CSV-format (Komprimerad text) i Gzip från Azure Blob Storage och skriv dem till Azure SQL Database.
- Många fler aktiviteter som kräver serialisering/deserialisering eller komprimering/dekomprimering.
Regioner som stöds
Tjänsten som aktiverar aktiviteten Kopiera är tillgänglig globalt i de regioner och geografiska områden som anges på Azure Integration Runtime-platser. Den globalt tillgängliga topologin säkerställer effektiv dataflytt som vanligtvis undviker hopp mellan regioner. Se Produkter efter region för att kontrollera tillgängligheten för Data Factory, Synapse-arbetsytor och dataflytt i en viss region.
Konfiguration
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
För att kunna använda aktiviteten Kopiera i Azure Data Factory- eller Synapse-pipelines måste du i allmänhet:
- Skapa länkade tjänster för källdatalagret och datalagret för mottagare. Du hittar listan över anslutningsappar som stöds i avsnittet Datalager och format som stöds i den här artikeln. Se avsnittet "Egenskaper för länkad tjänst" i anslutningsappen för konfigurationsinformation och egenskaper som stöds.
- Skapa datauppsättningar för källan och mottagaren. Se avsnitten "Datauppsättningsegenskaper" i artiklarna för anslutningsappen för källa och mottagare för konfigurationsinformation och egenskaper som stöds.
- Skapa en pipeline med aktiviteten Kopiera. Nästa avsnitt innehåller ett exempel.
Syntax
Följande mall för en aktiviteten Kopiera innehåller en fullständig lista över egenskaper som stöds. Ange de som passar ditt scenario.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Syntaxinformation
| Property | beskrivning | Obligatorisk? |
|---|---|---|
| type | För en aktiviteten Kopiera anger du tillCopy |
Ja |
| Ingångar | Ange den datauppsättning som du skapade som pekar på källdata. Aktiviteten Kopiera stöder endast en enda indata. | Ja |
| Utgångar | Ange den datauppsättning som du skapade som pekar på mottagardata. Aktiviteten Kopiera stöder endast en enda utdata. | Ja |
| typeProperties | Ange egenskaper för att konfigurera aktiviteten Kopiera. | Ja |
| source | Ange typ av kopieringskälla och motsvarande egenskaper för att hämta data. Mer information finns i avsnittet "aktiviteten Kopiera egenskaper" i anslutningsappsartikeln som anges i Datalager och format som stöds. |
Ja |
| sjunka | Ange typ av kopieringsmottagare och motsvarande egenskaper för att skriva data. Mer information finns i avsnittet "aktiviteten Kopiera egenskaper" i anslutningsappsartikeln som anges i Datalager och format som stöds. |
Ja |
| översättare | Ange explicita kolumnmappningar från källa till mottagare. Den här egenskapen gäller när standardkopieringsbeteendet inte uppfyller dina behov. Mer information finns i Schemamappning i kopieringsaktivitet. |
Nej |
| dataIntegrationUnits | Ange ett mått som representerar den mängd ström som Azure-integreringskörningen använder för datakopiering. Dessa enheter kallades tidigare molndataförflyttningsenheter (DMU). Mer information finns i Dataintegration Enheter. |
Nej |
| parallelCopies | Ange den parallellitet som du vill att aktiviteten Kopiera ska använda när du läser data från källan och skriver data till mottagaren. Mer information finns i Parallell kopiering. |
Nej |
| bevara | Ange om metadata/ACL:er ska bevaras under datakopian. Mer information finns i Bevara metadata. |
Nej |
| enableStaging stagingSettings |
Ange om interimdata ska mellanlagras i Blob Storage i stället för att kopiera data direkt från källa till mottagare. Information om användbara scenarier och konfigurationsinformation finns i Mellanlagrad kopia. |
Nej |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Välj hur du ska hantera inkompatibla rader när du kopierar data från källa till mottagare. Mer information finns i Feltolerans. |
Nej |
Övervakning
Du kan övervaka aktiviteten Kopiera körs i Azure Data Factory- och Synapse-pipelines både visuellt och programmässigt. Mer information finns i Övervaka kopieringsaktivitet.
Inkrementell kopia
Med Data Factory- och Synapse-pipelines kan du stegvis kopiera deltadata från ett källdatalager till ett datalager för mottagare. Mer information finns i Självstudie: Kopiera data stegvis.
Prestanda- och justering
Övervakningsfunktionen för kopieringsaktivitet visar statistik över kopieringsprestanda för var och en av dina aktivitetskörningar. I guiden aktiviteten Kopiera prestanda och skalbarhet beskrivs viktiga faktorer som påverkar prestanda för dataflytt via aktiviteten Kopiera. Den visar också de prestandavärden som observerats under testningen och beskriver hur du optimerar prestanda för aktiviteten Kopiera.
Återuppta från den senaste misslyckade körningen
aktiviteten Kopiera stöder återuppta från senaste misslyckade körningen när du kopierar stora filer som de är med binärt format mellan filbaserade lager och väljer att behålla mapp-/filhierarkin från källa till mottagare, t.ex. för att migrera data från Amazon S3 till Azure Data Lake Storage Gen2. Den gäller för följande filbaserade anslutningsappar: Amazon S3, Amazon S3 Compatible Storage Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage och SFTP.
Du kan använda kopieringsaktivitetens cv på följande två sätt:
Försök igen på aktivitetsnivå: Du kan ange antal återförsök för kopieringsaktivitet. Om kopieringsaktiviteten misslyckas under pipelinekörningen startar nästa automatiska återförsök från den senaste utvärderingsversionens felpunkt.
Kör om från misslyckad aktivitet: När pipelinekörningen har slutförts kan du också utlösa en omkörning från den misslyckade aktiviteten i övervakningsvyn för ADF-användargränssnittet eller programmatiskt. Om den misslyckade aktiviteten är en kopieringsaktivitet körs pipelinen inte bara igen från den här aktiviteten, utan återupptas också från den föregående körningens felpunkt.
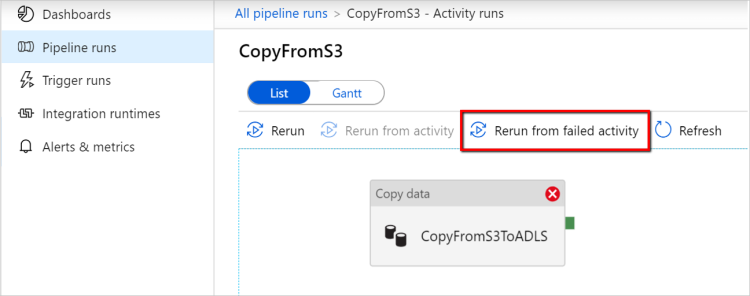
Några punkter att notera:
- Återuppta sker på filnivå. Om kopieringsaktiviteten misslyckas vid kopiering av en fil kopieras den här specifika filen igen i nästa körning.
- Ändra inte inställningarna för kopieringsaktiviteten mellan omkörningarna för att återuppta att fungera korrekt.
- När du kopierar data från Amazon S3, Azure Blob, Azure Data Lake Storage Gen2 och Google Cloud Storage kan kopieringsaktiviteten återupptas från godtyckligt antal kopierade filer. För resten av filbaserade anslutningsappar som källa stöder kopieringsaktiviteten för närvarande återuppta från ett begränsat antal filer, vanligtvis i intervallet tiotusentals och varierar beroende på längden på filsökvägarna. filer utöver det här talet kopieras på nytt under omkörningar.
För andra scenarier än binär filkopiering startar omkörningen av kopieringsaktiviteten från början.
Kommentar
Att återuppta från den senaste misslyckade körningen via lokalt installerad integrationskörning stöds nu endast i den lokalt installerade integrationskörningsversionen 5.43.8935.2 eller senare.
Bevara metadata tillsammans med data
När du kopierar data från källa till mottagare kan du i scenarier som datasjömigrering också välja att bevara metadata och ACL:er tillsammans med data med hjälp av kopieringsaktivitet. Mer information finns i Bevara metadata .
Lägga till metadatataggar i filbaserad mottagare
När mottagaren är Azure Storage-baserad (Azure Data Lake Storage eller Azure Blob Storage) kan vi välja att lägga till metadata i filerna. Dessa metadata visas som en del av filegenskaperna som nyckel/värde-par. För alla typer av filbaserade mottagare kan du lägga till metadata med dynamiskt innehåll med hjälp av pipelineparametrar, systemvariabler, funktioner och variabler. För binärfilsbaserad mottagare har du dessutom möjlighet att lägga till datumtid för senast ändrad (för källfilen) med nyckelordet $$LASTMODIFIED, samt anpassade värden som metadata i mottagarfilen.
Schema- och datatypsmappning
Se Schema- och datatypsmappning för information om hur aktiviteten Kopiera mappar dina källdata till mottagaren.
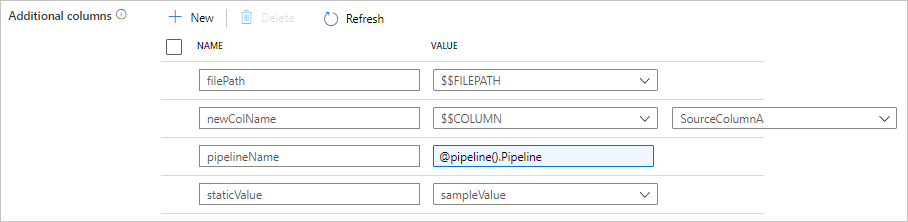
Lägg till ytterligare kolumner under kopiering
Förutom att kopiera data från källdatalager till mottagare kan du även konfigurera att lägga till ytterligare datakolumner som ska kopieras till mottagare. Till exempel:
- När du kopierar från en filbaserad källa lagrar du den relativa filsökvägen som en ytterligare kolumn att spåra från vilken fil data kommer från.
- Duplicera den angivna källkolumnen som en annan kolumn.
- Lägg till en kolumn med ADF-uttryck för att koppla ADF-systemvariabler som pipelinenamn/pipeline-ID eller lagra annat dynamiskt värde från uppströmsaktivitetens utdata.
- Lägg till en kolumn med statiskt värde för att uppfylla ditt behov av nedströmsförbrukning.
Du hittar följande konfiguration på fliken kopieringsaktivitetskälla. Du kan också mappa de ytterligare kolumnerna i schemamappningen för kopieringsaktivitet som vanligt med hjälp av dina definierade kolumnnamn.
Dricks
Den här funktionen fungerar med den senaste datamängdsmodellen. Om du inte ser det här alternativet från användargränssnittet kan du prova att skapa en ny datauppsättning.
Om du vill konfigurera den programmatiskt lägger du till egenskapen i kopieringsaktivitetskällan additionalColumns :
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| additionalColumns | Lägg till ytterligare datakolumner som ska kopieras till mottagare. Varje objekt under matrisen additionalColumns representerar en extra kolumn. Definierar name kolumnnamnet och value anger datavärdet för kolumnen.Tillåtna datavärden är: - $$FILEPATH – en reserverad variabel anger att källfilernas relativa sökväg ska lagras till mappsökvägen som anges i datauppsättningen. Använd på filbaserad källa.- $$COLUMN:<source_column_name> – ett mönster för reserverad variabel anger att den angivna källkolumnen ska dupliceras som en annan kolumn- Expression - Statiskt värde |
Nej |
Exempel:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Dricks
När du har konfigurerat ytterligare kolumner kommer du ihåg att mappa dem till målmottagaren på fliken Mappning.
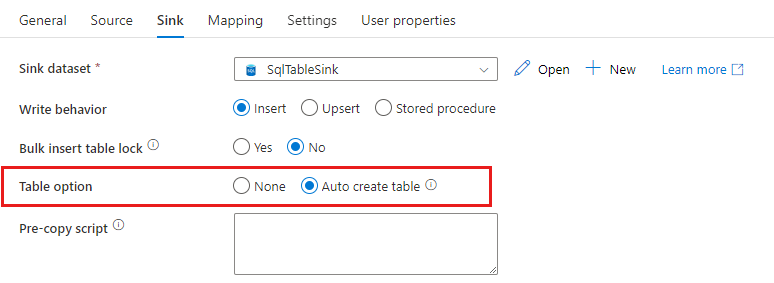
Skapa mottagartabeller automatiskt
När du kopierar data till SQL Database/Azure Synapse Analytics, om måltabellen inte finns, stöder kopieringsaktiviteten automatiskt att skapa den baserat på källdata. Syftet är att hjälpa dig att snabbt komma igång med att läsa in data och utvärdera SQL Database/Azure Synapse Analytics. Efter datainmatningen kan du granska och justera tabellschemat för mottagare enligt dina behov.
Den här funktionen stöds när du kopierar data från alla källor till följande datalager för mottagare. Du hittar alternativet för ADF-redigering av användargränssnittet ->aktiviteten Kopiera mottagare ->Tabellalternativet ->Skapa tabell automatiskt eller via tableOption egenskapen i nyttolasten för kopieringsaktivitetsmottagaren.
Feltolerans
Som standard slutar aktiviteten Kopiera kopiera data och returnerar ett fel när källdatarader inte är kompatibla med rader med mottagardata. För att kopian ska lyckas kan du konfigurera aktiviteten Kopiera att hoppa över och logga de inkompatibla raderna och kopiera endast kompatibla data. Mer information finns i aktiviteten Kopiera feltolerans.
Verifiering av datakonsekvens
När du flyttar data från källa till mållager ger kopieringsaktiviteten ett alternativ där du kan utföra ytterligare verifiering av datakonsekvens för att säkerställa att data inte bara kopieras från källa till mållager, utan även verifieras vara konsekventa mellan käll- och målarkivet. När inkonsekventa filer har hittats under dataflytten kan du antingen avbryta kopieringsaktiviteten eller fortsätta kopiera resten genom att aktivera feltoleransinställningen för att hoppa över inkonsekventa filer. Du kan hämta de överhoppade filnamnen genom att aktivera sessionslogginställningen i kopieringsaktiviteten. Mer information finns i Verifiering av datakonsekvens i kopieringsaktiviteten .
Sessionslogg
Du kan logga dina kopierade filnamn, vilket kan hjälpa dig att ytterligare se till att data inte bara kopieras från källa till målarkiv, utan även vara konsekventa mellan käll- och målarkivet genom att granska sessionsloggarna för kopieringsaktivitet. Mer information finns i Kopieringsaktivitet för sessionsinloggning.
Relaterat innehåll
Se följande snabbstarter, självstudier och exempel: