Ten artykuł zawiera wskazówki dotyczące tworzenia modelu danych usługi Power BI łączącego się z usługą Dataverse. Opisuje ona różnice między schematem usługi Dataverse i zoptymalizowanym schematem usługi Power BI oraz zawiera wskazówki dotyczące rozszerzania widoczności danych aplikacji biznesowych w usłudze Power BI.
Ze względu na łatwość konfiguracji, szybkiego wdrażania i powszechnego wdrażania usługa Dataverse przechowuje i zarządza coraz większą ilością danych w środowiskach w różnych organizacjach. Oznacza to, że istnieje jeszcze większa potrzeba i możliwość integracji analizy z tymi procesami. Możliwości obejmują:
Raport dotyczący wszystkich danych usługi Dataverse wykracza poza ograniczenia wbudowanych wykresów.
Zapewnij łatwy dostęp do odpowiednich, kontekstowych filtrowanych raportów w określonym rekordzie.
Zwiększ wartość danych usługi Dataverse, integrując je z danymi zewnętrznymi.
Korzystaj z wbudowanych sztucznej inteligencji (AI) usługi Power BI bez konieczności pisania złożonego kodu.
Zwiększ wdrażanie rozwiązań platformy Power Platform, zwiększając ich użyteczność i wartość.
Dostarczanie wartości danych w aplikacji osobom podejmującym decyzje biznesowe.
Łączenie usługi Power BI z usługą Dataverse
Łączenie usługi Power BI z usługą Dataverse obejmuje utworzenie modelu danych usługi Power BI. Możesz wybrać jedną z trzech metod, aby utworzyć model usługi Power BI.
importowanie danych usługi Dataverse przy użyciu łącznika Dataverse: ta metoda buforuje (przechowuje) dane usługi Dataverse w modelu usługi Power BI. Zapewnia ona szybką wydajność dzięki zapytaniom w pamięci. Zapewnia również elastyczność projektowania modelerom, umożliwiając im integrowanie danych z innych źródeł. Ze względu na te mocne strony importowanie danych jest trybem domyślnym podczas tworzenia modelu w programie Power BI Desktop.
Importowanie danych usługi Dataverse przy użyciu usługi Azure Synapse Link: ta metoda jest odmianą metody importowania, ponieważ buforuje również dane w modelu usługi Power BI, ale robi to, łącząc się z usługą Azure Synapse Analytics. Za pomocą usługi Azure Synapse Link dla usługi Dataverse tabele Dataverse są stale replikowane do usługi Azure Synapse lub Azure Data Lake Storage (ADLS) Gen2. To podejście służy do raportowania setek tysięcy, a nawet milionów rekordów w środowiskach Dataverse.
Utwórz połączenie DirectQuery przy użyciu łącznika Dataverse: ta metoda jest alternatywą do importowania danych. Model DirectQuery składa się tylko z metadanych definiujących strukturę modelu. Gdy użytkownik otworzy raport, usługa Power BI wysyła natywne zapytania do usługi Dataverse w celu pobrania danych. Rozważ utworzenie modelu DirectQuery, gdy raporty muszą wyświetlać dane usługi Dataverse niemal w czasie rzeczywistym lub gdy usługa Dataverse musi wymuszać zabezpieczenia oparte na rolach, aby użytkownicy mogli wyświetlać tylko dane, do których mają uprawnienia dostępu.
Ważne
Chociaż model DirectQuery może być dobrą alternatywą, jeśli potrzebujesz niemal w czasie rzeczywistym raportowania lub wymuszania zabezpieczeń usługi Dataverse w raporcie, może to spowodować niską wydajność tego raportu.
Aby określić właściwą metodę dla modelu usługi Power BI, należy wziąć pod uwagę następujące kwestie:
Wydajność zapytań
Ilość danych
Opóźnienie danych
Zabezpieczenia oparte na rolach
Złożoność instalacji
Napiwek
Aby zapoznać się ze szczegółową dyskusją na temat struktur modelu (importowania, trybu DirectQuery lub złożonego), ich korzyści i ograniczeń oraz funkcji, które ułatwiają optymalizowanie modeli danych usługi Power BI, zobacz Wybieranie struktury modelu usługi Power BI.
Wydajność zapytań
Zapytania wysyłane do modeli importu są szybsze niż zapytania natywne wysyłane do źródeł danych DirectQuery. Wynika to z faktu, że zaimportowane dane są buforowane w pamięci i są zoptymalizowane pod kątem zapytań analitycznych (operacji filtrowania, grupowania i podsumowywania).
Z drugiej strony modele DirectQuery pobierają dane ze źródła tylko po uruchomieniu raportu przez użytkownika, co powoduje opóźnienie w czasie renderowania raportu. Ponadto interakcje użytkowników w raporcie wymagają ponownego ściągniania źródła przez usługę Power BI, co jeszcze bardziej skraca czas odpowiedzi.
Ilość danych
Podczas tworzenia modelu importu należy dążyć do zminimalizowania danych załadowanych do modelu. Jest to szczególnie ważne w przypadku dużych modeli lub modeli, które przewidujesz, że w miarę upływu czasu staną się duże. Aby uzyskać więcej informacji, zobacz Techniki redukcji danych na potrzeby modelowania importu.
Połączenie zapytania bezpośredniego z usługą Dataverse jest dobrym wyborem, gdy wynik zapytania raportu nie jest duży. Duży wynik zapytania zawiera ponad 20 000 wierszy w tabelach źródłowych raportu lub wynik zwracany do raportu po zastosowaniu filtrów wynosi ponad 20 000 wierszy. W takim przypadku możesz utworzyć raport usługi Power BI przy użyciu łącznika Dataverse.
Uwaga
Rozmiar wiersza 20 000 nie jest twardym limitem. Jednak każde zapytanie źródła danych musi zwrócić wynik w ciągu 10 minut. W dalszej części tego artykułu dowiesz się, jak pracować w ramach tych ograniczeń i innych zagadnień dotyczących projektowania trybu DirectQuery w usłudze Dataverse.
Wydajność większych modeli semantycznych można poprawić przy użyciu łącznika Dataverse w celu zaimportowania danych do modelu danych.
Jeszcze większe modele semantyczne — z kilkoma setkami tysięcy lub nawet milionami wierszy — mogą korzystać z usługi Azure Synapse Link dla usługi Dataverse. To podejście konfiguruje ciągły zarządzany potok, który kopiuje dane usługi Dataverse do usługi ADLS Gen2 jako pliki CSV lub Parquet. Usługa Power BI może następnie wysyłać zapytania do bezserwerowej puli SQL usługi Azure Synapse w celu załadowania modelu importu.
Opóźnienie danych
Gdy dane usługi Dataverse zmieniają się szybko, a użytkownicy raportu muszą wyświetlać aktualne dane, model DirectQuery może dostarczać wyniki zapytań niemal w czasie rzeczywistym.
Napiwek
Możesz utworzyć raport usługi Power BI, który używa automatycznego odświeżania strony do wyświetlania aktualizacji w czasie rzeczywistym, ale tylko wtedy, gdy raport łączy się z modelem DirectQuery.
Importowanie modeli danych musi zakończyć odświeżanie danych, aby umożliwić raportowanie ostatnich zmian danych. Należy pamiętać, że istnieją ograniczenia dotyczące liczby codziennych operacji zaplanowanego odświeżania danych. W pojemności udostępnionej można zaplanować maksymalnie osiem odświeżeń dziennie.
W pojemności Premium lub pojemności usługi Microsoft Fabric można zaplanować maksymalnie 48 odświeżeń dziennie, co może osiągnąć 15-minutową częstotliwość odświeżania.
Ważne
Czasami w tym artykule opisano usługę Power BI Premium lub jej subskrypcje pojemności (jednostki SKU P). Należy pamiętać, że firma Microsoft obecnie konsoliduje opcje zakupu i cofnie usługę Power BI Premium na jednostki SKU pojemności. Nowi i istniejący klienci powinni rozważyć zakup subskrypcji pojemności sieci szkieletowej (jednostki SKU F).
Jeśli konieczne jest wymuszenie zabezpieczeń opartych na rolach, może to mieć bezpośredni wpływ na wybór struktury modelu usługi Power BI.
Usługa Dataverse może wymuszać złożone zabezpieczenia oparte na rolach w celu kontrolowania dostępu określonych rekordów do określonych użytkowników. Na przykład sprzedawca może mieć zezwolenie na wyświetlanie tylko szans sprzedaży, podczas gdy menedżer sprzedaży może zobaczyć wszystkie możliwości sprzedaży dla wszystkich sprzedawców. Możesz dostosować poziom złożoności na podstawie potrzeb organizacji.
Model DirectQuery oparty na usłudze Dataverse może łączyć się przy użyciu kontekstu zabezpieczeń użytkownika raportu. W ten sposób użytkownik raportu będzie widzieć tylko dane, do których mają dostęp. Takie podejście może uprościć projekt raportu, zapewniając akceptowalną wydajność.
Aby uzyskać lepszą wydajność, można utworzyć model importu, który łączy się z usługą Dataverse. W takim przypadku można w razie potrzeby dodać zabezpieczenia na poziomie wiersza do modelu.
Uwaga
Replikacja niektórych zabezpieczeń opartych na rolach usługi Dataverse może być trudna, szczególnie w przypadku wymuszania złożonych uprawnień przez usługę Dataverse. Ponadto może wymagać ciągłego zarządzania, aby zapewnić synchronizację uprawnień usługi Power BI z uprawnieniami usługi Dataverse.
Używanie łącznika Dataverse w usłudze Power BI — zarówno w przypadku modeli importu, jak i DirectQuery — jest proste i nie wymaga żadnego specjalnego oprogramowania ani podniesionych uprawnień usługi Dataverse. Jest to zaleta dla organizacji lub działów, które są coraz pracę.
Opcja usługi Azure Synapse Link wymaga dostępu administratora systemu do usługi Dataverse i niektórych uprawnień platformy Azure. Te uprawnienia platformy Azure są wymagane do skonfigurowania konta magazynu i obszaru roboczego usługi Synapse.
Zalecane wskazówki
W tej sekcji opisano wzorce projektowe (i anty-wzorce), które należy wziąć pod uwagę podczas tworzenia modelu usługi Power BI łączącego się z usługą Dataverse. Tylko kilka z tych wzorców jest unikatowych dla usługi Dataverse, ale zwykle są to typowe wyzwania dla twórców usługi Dataverse podczas tworzenia raportów usługi Power BI.
Skup się na konkretnym przypadku użycia
Zamiast próbować rozwiązać wszystko, skoncentruj się na konkretnym przypadku użycia.
To zalecenie jest prawdopodobnie najbardziej typowe i łatwe w najtrudniejszym antywzór, aby uniknąć. Próba utworzenia pojedynczego modelu, który osiąga wszystkie potrzeby samoobsługowego raportowania, jest trudna. Rzeczywistość polega na tym, że udane modele są tworzone w celu odpowiadania na pytania dotyczące centralnego zestawu faktów w jednym podstawowym temacie. Chociaż początkowo może to wydawać się ograniczać model, faktycznie zwiększa możliwości, ponieważ można dostroić i zoptymalizować model pod kątem odpowiadania na pytania w tym temacie.
Aby upewnić się, że masz jasne zrozumienie celu modelu, zadaj sobie następujące pytania.
Jaki obszar tematu będzie obsługiwał ten model?
Kto jest odbiorcą raportów?
Jakie pytania dotyczą raportów próbujących odpowiedzieć?
Jaki jest minimalny realny model semantyczny?
Opór łączenia wielu obszarów tematów w jeden model tylko dlatego, że użytkownik raportu ma pytania w wielu obszarach tematów, które mają być rozwiązane przez pojedynczy raport. Dzieląc ten raport na wiele raportów, z których każdy koncentruje się na innym temacie (lub tabeli faktów), można tworzyć znacznie wydajniejsze, skalowalne i możliwe do zarządzania modele.
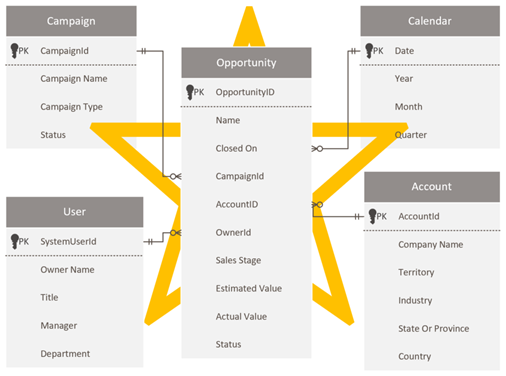
Projektowanie schematu gwiazdy
Deweloperzy i administratorzy usługi Dataverse, którzy dobrze korzystają ze schematu usługi Dataverse, mogą być skłonni do odtworzenia tego samego schematu w usłudze Power BI. Takie podejście jest anty-wzorzec i jest prawdopodobnie najtrudniejsze do pokonania, ponieważ po prostu czuje się prawo do utrzymania spójności.
Usługa Dataverse, jako model relacyjny, dobrze nadaje się do swojego celu. Nie jest ona jednak zaprojektowana jako model analityczny zoptymalizowany pod kątem raportów analitycznych. Najbardziej rozpowszechnionym wzorcem modelowania danych analitycznych jest projekt schematu gwiazdy. Schemat gwiazdy to dojrzałe podejście do modelowania powszechnie stosowane przez magazyny danych relacyjnych. Wymaga to, aby modeliści sklasyfikowali swoje tabele modelu jako wymiar lub fakt. Raporty mogą filtrować lub grupować przy użyciu kolumn tabeli wymiarów oraz podsumowywać kolumny tabeli faktów.
Aparat mashupu Power Query stara się osiągnąć składanie zapytań, gdy jest to możliwe ze względu na wydajność. Zapytanie, które umożliwia składanie delegatów przetwarzania zapytań do systemu źródłowego.
W tym przypadku system źródłowy Dataverse musi dostarczać tylko odfiltrowane lub podsumowane wyniki do usługi Power BI. Złożone zapytanie jest często znacznie szybsze i wydajniejsze niż zapytanie, które nie składa się.
Aby uzyskać więcej informacji na temat sposobu składania zapytań, zobacz Składanie zapytań Dodatku Power Query.
Uwaga
Optymalizacja dodatku Power Query jest szerokim tematem. Aby lepiej zrozumieć, co robi dodatek Power Query podczas tworzenia i odświeżania modelu w programie Power BI Desktop, zobacz Diagnostyka zapytań.
Minimalizuj liczbę kolumn zapytania
Domyślnie podczas ładowania tabeli Dataverse przy użyciu dodatku Power Query pobiera ona wszystkie wiersze i wszystkie kolumny. Na przykład podczas wykonywania zapytań względem tabeli użytkownika systemu może ona zawierać więcej niż 1000 kolumn. Kolumny w metadanych zawierają relacje z innymi jednostkami i odnośnikami do etykiet opcji, dzięki czemu łączna liczba kolumn rośnie wraz ze złożonością tabeli Dataverse.
Próba pobrania danych ze wszystkich kolumn jest antywzorem. Często powoduje to rozszerzone operacje odświeżania danych i spowoduje to niepowodzenie zapytania, gdy czas potrzebny do zwrócenia danych przekracza 10 minut.
Ponadto upewnij się, że wprowadzasz krok Krok Usuwania kolumn dodatku Power Query, aby składać się z powrotem do źródła. Dzięki temu dodatek Power Query może uniknąć niepotrzebnej pracy przy wyodrębnieniu danych źródłowych tylko w celu ich późniejszego odrzucenia (w rozwiniętym kroku).
Jeśli masz tabelę zawierającą wiele kolumn, użycie konstruktora interakcyjnego zapytania dodatku Power Query może być niepraktyczne. W takim przypadku możesz rozpocząć od utworzenia pustego zapytania. Następnie możesz użyć Edytor zaawansowany, aby wkleić minimalne zapytanie, które tworzy punkt początkowy.
Rozważ następujące zapytanie, które pobiera dane z zaledwie dwóch kolumn tabeli account.
Power Query M
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Pisanie zapytań natywnych
Jeśli masz określone wymagania dotyczące transformacji, możesz osiągnąć lepszą wydajność przy użyciu zapytania natywnego napisanego w usłudze Dataverse SQL, który jest podzbiorem języka Transact-SQL. Możesz napisać zapytanie natywne w celu:
Zmniejsz liczbę wierszy (przy użyciu klauzuli WHERE ).
Agregowanie danych (przy użyciu GROUP BY klauzul i HAVING ).
Łączenie tabel w określony sposób (przy użyciu JOIN składni lub APPLY ).
Wykonywanie zapytań natywnych za pomocą opcji EnableFolding
Dodatek Power Query wykonuje zapytanie natywne przy użyciu Value.NativeQuery funkcji .
W przypadku korzystania z tej funkcji należy dodać EnableFolding=true opcję, aby upewnić się, że zapytania są składane z powrotem do usługi Dataverse. Zapytanie natywne nie zostanie złożone, chyba że ta opcja zostanie dodana. Włączenie tej opcji może spowodować znaczne zwiększenie wydajności — w niektórych przypadkach nawet 97 procent szybciej.
Rozważ następujące zapytanie, które używa zapytania natywnego, aby pobrać wybrane kolumny z tabeli account. Zapytanie natywne zostanie złożone, ponieważ opcja jest ustawiona EnableFolding=true .
Power Query M
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Podczas pobierania podzbioru danych z dużego woluminu danych można oczekiwać osiągnięcia największych ulepszeń wydajności.
Napiwek
Poprawa wydajności może również zależeć od tego, jak usługa Power BI wysyła zapytania do źródłowej bazy danych. Na przykład miara korzystająca z COUNTDISTINCT funkcji języka DAX nie wykazała niemal żadnej poprawy z lub bez wskazówki składania. Gdy formuła miary została przepisana do używania SUMX funkcji języka DAX, zapytanie składało się, co spowodowało 97-procentową poprawę w tym samym zapytaniu bez wskazówki.
Aby uzyskać więcej informacji, zobacz Value.NativeQuery. (Opcja EnableFolding nie jest udokumentowana, ponieważ jest specyficzna tylko dla niektórych źródeł danych).
Przyspieszanie etapu oceny
Jeśli używasz łącznika Dataverse (wcześniej znanego jako Usługa Common Data Service), możesz dodać CreateNavigationProperties=false opcję przyspieszenia etapu oceny importu danych.
Etap oceny danych importowanych iteruje za pośrednictwem metadanych źródła, aby określić wszystkie możliwe relacje tabeli. Te metadane mogą być obszerne, szczególnie w przypadku usługi Dataverse. Dodając tę opcję do zapytania, możesz poinformować dodatek Power Query, że nie zamierzasz używać tych relacji. Opcja umożliwia programowi Power BI Desktop pominięcie tego etapu odświeżania i przejście do pobierania danych.
Uwaga
Nie używaj tej opcji, gdy zapytanie zależy od żadnych rozszerzonych kolumn relacji.
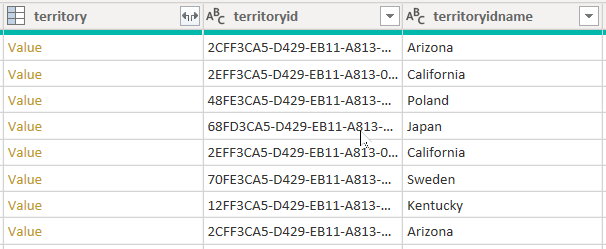
Rozważmy przykład, który pobiera dane z tabeli account. Zawiera trzy kolumny powiązane z terytorium: territory, territoryidi territoryidname.
Po ustawieniu opcji CreateNavigationProperties=false, kolumny territoryid i territoryidname pozostaną, ale kolumna territory, która jest kolumną relacji (pokazuje powiązania wartości z linkami), zostanie wykluczona. Ważne jest, aby zrozumieć, że kolumny relacji dodatku Power Query to inna koncepcja relacji modelu, która propaguje filtry między tabelami modelu.
Rozważ następujące zapytanie, które używa CreateNavigationProperties=false opcji (w kroku źródła ), aby przyspieszyć etap oceny importu danych.
Power Query M
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
W przypadku korzystania z tej opcji prawdopodobnie wystąpi znaczna poprawa wydajności, gdy tabela Dataverse ma wiele relacji z innymi tabelami. Na przykład ze względu na to, że tabela SystemUser jest powiązana z każdą inną tabelą w bazie danych, wydajność odświeżania tej tabeli przyniesie korzyści, ustawiając opcję CreateNavigationProperties=false.
Uwaga
Ta opcja może poprawić wydajność odświeżania danych tabel importu lub tabel w trybie przechowywania podwójnego, w tym procesu stosowania zmian okna Edytor Power Query. Nie poprawia wydajności interakcyjnego filtrowania krzyżowego tabel trybu przechowywania DirectQuery.
Rozwiązywanie problemów z pustymi etykietami wyboru
Jeśli okaże się, że etykiety wyboru usługi Dataverse są puste w usłudze Power BI, może to być spowodowane tym, że etykiety nie zostały opublikowane w punkcie końcowym strumienia danych tabelarycznych (TDS).
W takim przypadku otwórz portal usługi Dataverse Maker, przejdź do obszaru Rozwiązania , a następnie wybierz pozycję Publikuj wszystkie dostosowania. Proces publikacji zaktualizuje punkt końcowy TDS przy użyciu najnowszych metadanych, dzięki czemu etykiety opcji będą dostępne dla usługi Power BI.
Większe modele semantyczne za pomocą usługi Azure Synapse Link
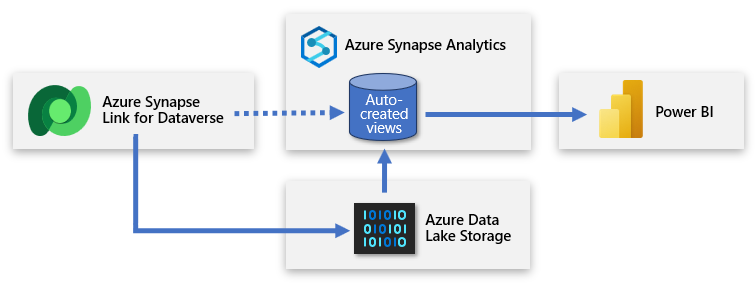
Usługa Dataverse umożliwia synchronizowanie tabel z usługą Azure Data Lake Storage (ADLS), a następnie łączenie się z danymi za pośrednictwem obszaru roboczego usługi Azure Synapse. Dzięki minimalnym nakładom pracy możesz skonfigurować usługę Azure Synapse Link , aby wypełnić dane usługi Dataverse w usłudze Azure Synapse i umożliwić zespołom danych odnajdywanie szczegółowych informacji.
Usługa Azure Synapse Link umożliwia ciągłą replikację danych i metadanych z usługi Dataverse do usługi Data Lake. Udostępnia również wbudowaną bezserwerową pulę SQL jako wygodne źródło danych dla zapytań usługi Power BI.
Mocne strony tego podejścia są znaczące. Klienci uzyskują możliwość uruchamiania analiz, analizy biznesowej i obciążeń uczenia maszynowego w danych platformy Dataverse przy użyciu różnych zaawansowanych usług. Zaawansowane usługi to Apache Spark, Power BI, Azure Data Factory, Azure Databricks i Azure Machine Learning.
Tworzenie usługi Azure Synapse Link dla usługi Dataverse
Aby utworzyć usługę Azure Synapse Link dla usługi Dataverse, musisz spełnić następujące wymagania wstępne.
Dostęp administratora systemu do środowiska Dataverse.
W przypadku usługi Azure Data Lake Storage:
Musisz mieć konto magazynu do użycia z usługą ADLS Gen2.
Musisz mieć przypisany dostęp właściciela danych obiektu blob usługi Storage i współautora danych obiektu blob usługi Storage do konta magazynu. Aby uzyskać więcej informacji, zobacz Kontrola dostępu oparta na rolach (Azure RBAC).
Obszar roboczy musi znajdować się w tym samym regionie co konto magazynu usługi ADLS Gen2.
Konfiguracja obejmuje logowanie się do usługi Power Apps i łączenie usługi Dataverse z obszarem roboczym usługi Azure Synapse. Środowisko przypominające kreatora umożliwia utworzenie nowego linku, wybierając konto magazynu i tabele do wyeksportowania. Następnie usługa Azure Synapse Link kopiuje dane do magazynu usługi ADLS Gen2 i automatycznie tworzy widoki w wbudowanej bezserwerowej puli SQL usługi Azure Synapse. Następnie możesz połączyć się z tymi widokami , aby utworzyć model usługi Power BI.
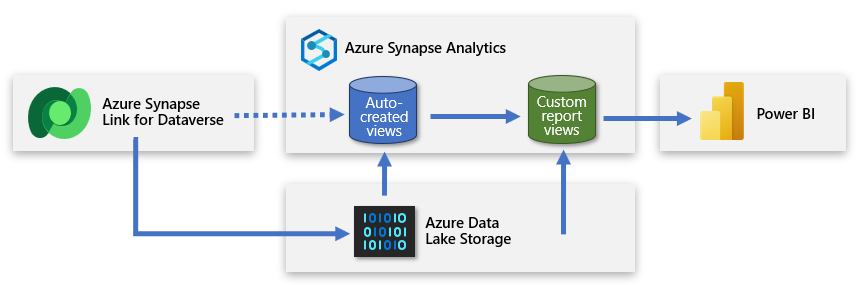
Możesz utworzyć drugą bezserwerową bazę danych SQL i użyć jej do dodawania niestandardowych widoków raportów. W ten sposób można przedstawić uproszczony zestaw danych twórcy usługi Power BI, który pozwala im utworzyć model na podstawie przydatnych i odpowiednich danych. Nowa bezserwerowa baza danych SQL staje się podstawowym połączeniem źródłowym twórcy i przyjazną reprezentacją danych pochodzących z usługi Data Lake.
Takie podejście dostarcza dane do usługi Power BI, która jest skoncentrowana, wzbogacona i filtrowana.
Bazę danych SQL bezserwerową można utworzyć w obszarze roboczym usługi Azure Synapse przy użyciu usługi Azure Synapse Studio. Wybierz pozycję Bezserwerowa jako typ bazy danych SQL i wprowadź nazwę bazy danych. Dodatek Power Query może nawiązać połączenie z tą bazą danych, łącząc się z punktem końcowym SQL obszaru roboczego.
Tworzenie widoków niestandardowych
Możesz utworzyć widoki niestandardowe, które opakowujące bezserwerowe zapytania puli SQL. Te widoki będą służyć jako proste, czyste źródła danych, z którymi łączy się usługa Power BI. Widoki powinny:
Dołącz etykiety skojarzone z polami wyboru.
Zmniejsz złożoność, dołączając tylko kolumny wymagane do modelowania danych.
Odfiltruj niepotrzebne wiersze, takie jak nieaktywne rekordy.
Rozważmy następujący widok, który pobiera dane kampanii.
SQL
CREATEVIEW [VW_Campaign]
ASSELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFTOUTERJOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033AND [campaign_typecode].[EntityName] = 'campaign'AND [campaign_typecode].[OptionSetName] = 'typecode'LEFTOUTERJOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033AND [campaign_status].[EntityName] = 'campaign'WHERE
[base].[statecode] = 0;
Zwróć uwagę, że widok zawiera tylko cztery kolumny, z których każdy jest aliasem o przyjaznej nazwie. Istnieje również klauzula zwracająca WHERE tylko niezbędne wiersze, w tym przypadku aktywne kampanie. Ponadto widok wykonuje zapytanie do tabeli kampanii, która jest połączona z tabelami OptionsetMetadata i StatusMetadata, pobierającymi etykiety wyboru.
Usługa Azure Synapse Link dla usługi Dataverse zapewnia ciągłą synchronizację danych z danymi w usłudze Data Lake. W przypadku działań o wysokim użyciu jednoczesne zapisy i odczyty mogą tworzyć blokady, które powodują niepowodzenie zapytań. Aby zapewnić niezawodność podczas pobierania danych, w usłudze Azure Synapse są synchronizowane dwie wersje danych tabeli.
dane niemal w czasie rzeczywistym: udostępnia kopię danych zsynchronizowaną z usługi Dataverse za pośrednictwem usługi Azure Synapse Link w wydajny sposób, wykrywając, jakie dane uległy zmianie od czasu ich początkowego wyodrębnienia lub ostatniej synchronizacji.
dane migawki: udostępnia kopię danych tylko do odczytu niemal w czasie rzeczywistym, które są aktualizowane w regularnych odstępach czasu (w tym przypadku co godzinę). Nazwy tabel danych migawek mają _partitioned dołączane do ich nazwy.
Jeśli przewidujesz, że duża liczba operacji odczytu i zapisu zostanie wykonana jednocześnie, pobierz dane z tabel migawek, aby uniknąć błędów zapytań.
Nawiązywanie połączenia z usługą Synapse Analytics
Aby wykonać zapytanie dotyczące bezserwerowej puli SQL usługi Azure Synapse, potrzebny będzie jego punkt końcowy SQL obszaru roboczego. Punkt końcowy można pobrać z programu Synapse Studio, otwierając właściwości bezserwerowej puli SQL.
W programie Power BI Desktop możesz nawiązać połączenie z usługą Azure Synapse przy użyciu łącznika SQL usługi Azure Synapse Analytics. Po wyświetleniu monitu o serwer wprowadź punkt końcowy SQL obszaru roboczego.
Zagadnienia dotyczące zapytania bezpośredniego
Istnieje wiele przypadków użycia, gdy korzystanie z trybu przechowywania DirectQuery może rozwiązać twoje wymagania. Jednak użycie trybu DirectQuery może negatywnie wpłynąć na wydajność raportów usługi Power BI. Raport korzystający z połączenia DirectQuery z usługą Dataverse nie będzie tak szybki, jak raport korzystający z modelu importu. Ogólnie rzecz biorąc, należy importować dane do usługi Power BI zawsze, gdy jest to możliwe.
Zalecamy rozważenie tematów w tej sekcji podczas pracy z zapytaniem bezpośrednim.
Aby uzyskać więcej informacji na temat określania, kiedy należy pracować z trybem przechowywania DirectQuery, zobacz Wybieranie struktury modelu usługi Power BI.
Używanie tabel wymiarów w trybie przechowywania podwójnego
Tabela z podwójnym trybem przechowywania jest ustawiona tak, aby korzystała zarówno z trybów importowania, jak i trybu przechowywania DirectQuery. W czasie wykonywania zapytań usługa Power BI określa najbardziej wydajny tryb do użycia. Jeśli to możliwe, usługa Power BI próbuje spełnić zapytania przy użyciu zaimportowanych danych, ponieważ jest szybsza.
W razie potrzeby należy rozważyć ustawienie tabel wymiarów na tryb przechowywania podwójnego. Dzięki temu wizualizacje fragmentatora i listy kart filtru — które są często oparte na kolumnach tabeli wymiarów — będą renderowane szybciej, ponieważ będą one wykonywane względem zaimportowanych danych.
Ważne
Jeśli tabela wymiarów musi dziedziczyć model zabezpieczeń Usługi Dataverse, nie jest odpowiednia do używania trybu przechowywania podwójnego.
Tabele faktów, które zwykle przechowują duże ilości danych, powinny pozostać tabelami trybu przechowywania DirectQuery. Będą one filtrowane według powiązanych tabel wymiarów trybu przechowywania podwójnego, które można połączyć z tabelą faktów w celu uzyskania wydajnego filtrowania i grupowania.
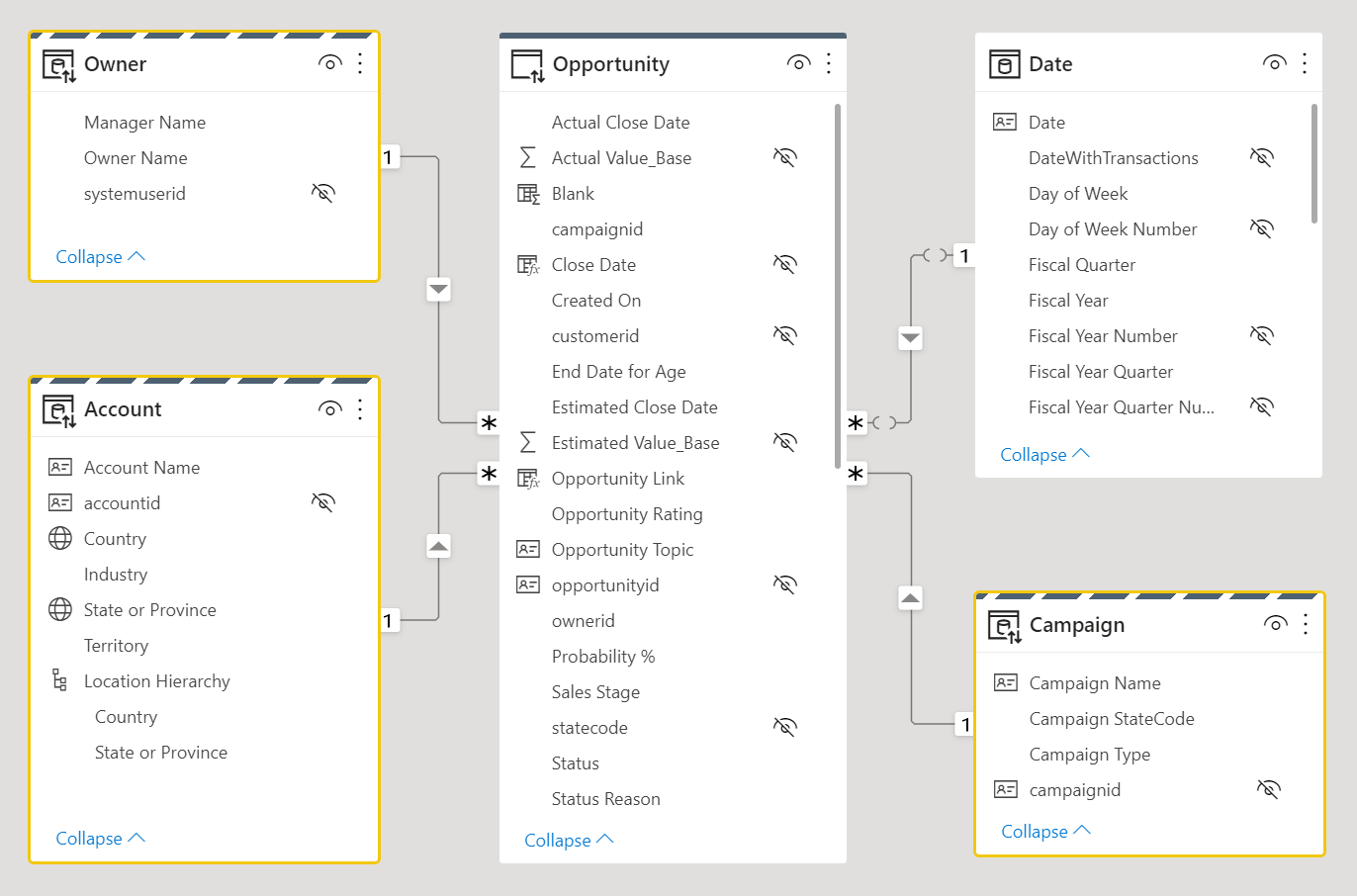
Rozważmy następujący projekt modelu danych. Trzy tabele wymiarów, Owner, Accounti Campaign mają paskowane górne obramowanie, co oznacza, że są ustawione na tryb przechowywania podwójnego.
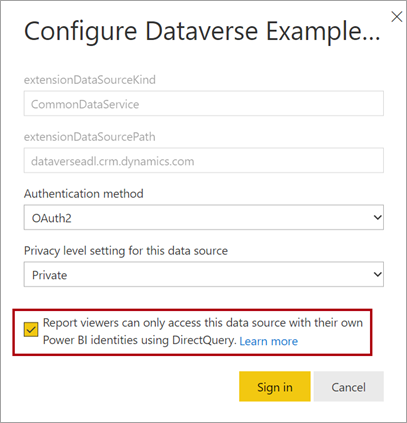
Podczas publikowania modelu DirectQuery w usługa Power BI można użyć ustawień modelu semantycznego, aby włączyć logowanie jednokrotne przy użyciu protokołu OAuth2 firmy Microsoft dla użytkowników raportu. Należy włączyć tę opcję, gdy zapytania usługi Dataverse muszą być wykonywane w kontekście zabezpieczeń użytkownika raportu.
Po włączeniu opcji logowania jednokrotnego usługa Power BI wysyła uwierzytelnione poświadczenia microsoft entra użytkownika raportu w zapytaniach do usługi Dataverse. Ta opcja umożliwia usłudze Power BI uhonorowanie ustawień zabezpieczeń skonfigurowanych w źródle danych.
W przypadku korzystania z usługi Microsoft Dynamics 365 Customer Engagement (CE) i opartych na modelu aplikacji Power Apps opartych na usłudze Dataverse można tworzyć widoki, które pokazują tylko rekordy, w których pole nazwy użytkownika, takie jak Owner, jest równe bieżącemu użytkownikowi. Możesz na przykład tworzyć widoki o nazwie "Moje otwarte możliwości", "Moje aktywne przypadki" i inne.
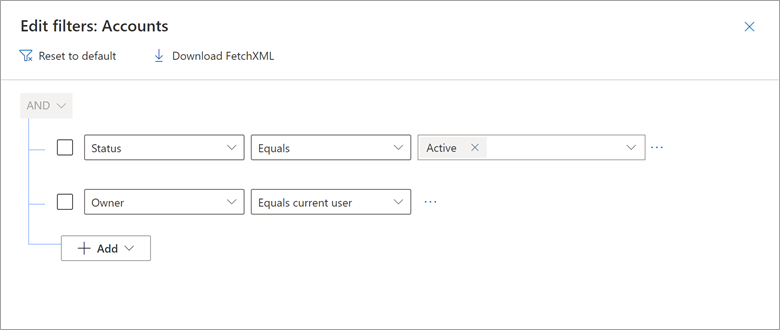
Rozważmy przykład sposobu, w jaki widok Moje aktywne konta usługi Dynamics 365 zawiera filtr, w którym właściciel jest równy bieżącemu użytkownikowi.
Ten wynik można odtworzyć w dodatku Power Query przy użyciu natywnego zapytania, które osadza CURRENT_USER token.
Rozważmy poniższy przykład pokazujący zapytanie natywne zwracające konta bieżącego użytkownika. W klauzuli WHERE zwróć uwagę, że kolumna ownerid jest filtrowana według tokenu CURRENT_USER.
Power Query M
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Po opublikowaniu modelu w usługa Power BI należy włączyć logowanie jednokrotne( SSO), aby usługa Power BI wysyłała uwierzytelnione poświadczenia użytkownika raportu firmy Microsoft Entra do usługi Dataverse.
Tworzenie dodatkowych modeli importu
Możesz utworzyć model DirectQuery, który wymusza uprawnienia usługi Dataverse, wiedząc , że wydajność będzie niska. Następnie można uzupełnić ten model modelem importu, które dotyczą określonych tematów lub odbiorców, które mogą wymuszać uprawnienia zabezpieczeń na poziomie wiersza.
Na przykład model importu może zapewnić dostęp do wszystkich danych usługi Dataverse, ale nie wymusza żadnych uprawnień. Ten model byłby odpowiedni dla kadry kierowniczej, którzy mają już dostęp do wszystkich danych usługi Dataverse.
W innym przykładzie, gdy usługa Dataverse wymusza uprawnienia oparte na rolach według regionu sprzedaży, można utworzyć jeden model importu i zreplikować te uprawnienia przy użyciu zabezpieczeń na poziomie wiersza. Alternatywnie można utworzyć model dla każdego regionu sprzedaży. Następnie można udzielić uprawnień do odczytu tym modelom (semantycznym modelom) sprzedawcom każdego regionu. Aby ułatwić tworzenie tych modeli regionalnych, można użyć parametrów i szablonów raportów. Aby uzyskać więcej informacji, zobacz Tworzenie i używanie szablonów raportów w programie Power BI Desktop.
Powiązana zawartość
Aby uzyskać więcej informacji związanych z tym artykułem, zapoznaj się z następującymi zasobami.
Ostateczne wydarzenie prowadzone przez społeczność w usłudze Power BI, sieci szkieletowej, SQL i sztucznej inteligencji. 31 marca - 2 kwietnia. Użyj kodu MSCUST dla rabatu w wysokości 150 USD. Ceny idą w górę 11 lutego.
Demonstrate methods and best practices that align with business and technical requirements for modeling, visualizing, and analyzing data with Microsoft Power BI.
Poznaj projekt schematu gwiazdy i jego znaczenie dla opracowywania modeli semantycznych usługi Power BI zoptymalizowanych pod kątem wydajności i użyteczności.