Potoki i działania w usłudze Azure Data Factory i Azure Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Ważne
Obsługa usługi Azure Machine Learning Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Learning do tej daty.
Od 1 grudnia 2021 r. nie można utworzyć nowych zasobów usługi Machine Learning Studio (klasycznego) (obszaru roboczego i planu usługi internetowej). Do 31 sierpnia 2024 r. możesz nadal korzystać z istniejących eksperymentów i usług internetowych usługi Machine Learning Studio (klasycznych). Aby uzyskać więcej informacji, zobacz:
- Migrowanie do usługi Azure Machine Learning z usługi Machine Learning Studio (wersja klasyczna)
- Co to jest Azure Machine Learning?
Dokumentacja usługi Machine Learning Studio (klasyczna) jest wycofywana i może nie zostać zaktualizowana w przyszłości.
Ten artykuł pomaga zrozumieć potoki i działania w usługach Azure Data Factory i Azure Synapse Analytics oraz używać ich do tworzenia pełnych przepływów pracy opartych na danych na potrzeby scenariuszy przenoszenia danych i przetwarzania danych.
Omówienie
Obszar roboczy usługi Data Factory lub Synapse może mieć co najmniej jeden potok. Potok jest logicznym grupowaniem działań, które wspólnie wykonują zadanie. Na przykład potok może zawierać zestaw działań, które pozyskują i czyszczą dane dziennika, a następnie uruchamiają przepływ mapowania danych w celu przeanalizowania danych dziennika. Potok umożliwia zarządzanie działaniami jako zestawem, a nie każdym z nich osobno. Należy wdrożyć i zaplanować harmonogram potoku zamiast poszczególnych działań.
Działania w potoku określają akcje do wykonania na danych. Możesz na przykład użyć działania kopiowania w celu skopiowania danych z programu SQL Server do usługi Azure Blob Storage. Następnie użyj działania przepływu danych lub działania notesu usługi Databricks, aby przetwarzać i przekształcać dane z magazynu obiektów blob do puli usługi Azure Synapse Analytics, na podstawie których są tworzone rozwiązania do raportowania analizy biznesowej.
Usługi Azure Data Factory i Azure Synapse Analytics mają trzy grupy działań: działania przenoszenia danych, działania przekształcania danych i działania sterowania. Dane działanie może — ale nie musi — korzystać z wejściowych zestawów danych i generować co najmniej jeden wyjściowy zestaw danych. Na poniższym diagramie przedstawiono relację między potokiem, działaniem i zestawem danych:

Wejściowy zestaw danych reprezentuje dane wejściowe dla działania w potoku, a wyjściowy zestaw danych reprezentuje dane wyjściowe dla działania. Zestawy danych identyfikują dane w różnych magazynach danych, takich jak tabele, pliki, foldery i dokumenty. Po utworzeniu zestawu danych można go użyć z działaniami w potoku. Na przykład zestaw danych może być zestawem danych wejściowych/wyjściowych działania kopiowania lub działania HDInsightHive. Aby uzyskać więcej informacji na temat zestawów danych, zobacz artykuł Datasets in Azure Data Factory (Zestawy danych w usłudze Azure Data Factory).
Uwaga
Istnieje domyślny limit nietrwały wynoszący maksymalnie 80 działań na potok, który obejmuje działania wewnętrzne dla kontenerów.
Działania dotyczące przenoszenia danych
Działanie kopiowania w usłudze Data Factory kopiuje dane z magazynu danych źródła do magazynu danych ujścia. Usługa Data Factory obsługuje magazyny danych wymienione w tabeli w tej sekcji. Dane z dowolnego źródła można zapisać do dowolnego ujścia.
Aby uzyskać więcej informacji, zobacz artykuł Działanie kopiowania — omówienie.
Kliknij magazyn danych, aby dowiedzieć się, jak kopiować dane do i z tego magazynu.
Uwaga
Jeśli łącznik jest oznaczony jako wersja zapoznawcza można go wypróbować, a następnie przekazać nam opinię na jego temat. Jeśli w swoim rozwiązaniu chcesz wprowadzić zależność od łączników w wersji zapoznawczej, skontaktuj się z pomocą techniczną platformy Azure.
Działania dotyczące przekształcania danych
Usługi Azure Data Factory i Azure Synapse Analytics obsługują następujące działania przekształcania, które można dodać pojedynczo lub połączyć łańcuch z innym działaniem.
Aby uzyskać więcej informacji, zobacz artykuł z działaniami dotyczącymi przekształcania danych.
| Działanie przekształcania danych | Środowisko obliczeniowe |
|---|---|
| Przepływ danych | Klastry Apache Spark zarządzane przez usługę Azure Data Factory |
| Funkcja platformy Azure | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Przesyłanie strumieniowe usługi Hadoop | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Działania programu ML Studio (klasyczne): wykonywanie wsadowe i aktualizowanie zasobu | Maszyna wirtualna platformy Azure |
| Procedura składowana | Azure SQL, Azure Synapse Analytics lub SQL Server |
| U-SQL | Azure Data Lake Analytics |
| Działanie niestandardowe | Usługa Azure Batch |
| Notes usługi Databricks | Azure Databricks |
| Działanie jar usługi Databricks | Azure Databricks |
| Działanie języka Python usługi Databricks | Azure Databricks |
| Działanie notesu usługi Synapse | Azure Synapse Analytics |
Działania przepływu sterowania
Obsługiwane są następujące działania przepływu sterowania:
| Działanie sterowania | opis |
|---|---|
| Dołącz zmienną | Dodaj wartość do istniejącej zmiennej tablicy. |
| Wykonywanie potoku | Działanie Execute Pipeline (Wykonywanie potoku) umożliwia potokowi usługi Data Factory lub Synapse wywoływanie innego potoku. |
| Filtr | Stosowanie wyrażenia filtru do tablicy wejściowej |
| Dla każdego | Działanie ForEach definiuje powtarzający się przepływ sterowania w potoku. To działanie służy do wykonywania iteracji po kolekcji i wykonuje określone działania w pętli. Implementacja pętli tego działania przypomina strukturę pętli Foreach w językach programowania. |
| Pobieranie metadanych | Działanie GetMetadata może służyć do pobierania metadanych dowolnych danych w potoku usługi Data Factory lub Synapse. |
| Działanie If Condition | Działanie If Condition umożliwia tworzenie gałęzi na podstawie warunków, które są obliczane na wartość true lub false. Działanie If Condition pełni taką samą rolę, co instrukcja if w językach programowania. Ocenia zestaw działań, gdy warunek jest obliczany na true i inny zestaw działań, gdy warunek ma wartość false. |
| Działanie Lookup | Działanie Lookup może być używane do odczytywania lub wyszukiwania rekordu/nazwy tabeli/wartości z dowolnego źródła zewnętrznego. Do tych danych wyjściowych mogą także odwoływać się kolejne działania. |
| Ustaw zmienną | Ustaw wartość istniejącej zmiennej. |
| Działanie Until | Wprowadza pętlę Do-Until, przypominającą strukturę pętli Do-Until w językach programowania. Służy do wykonywania zestawu działań w pętli do momentu, gdy warunek skojarzony z działaniem zostanie obliczony na wartość true. Możesz określić wartość limitu czasu dla działania until. |
| Działanie walidacji | Upewnij się, że potok kontynuuje wykonywanie tylko wtedy, gdy istnieje zestaw danych referencyjnych, spełnia określone kryteria lub osiągnięto limit czasu. |
| Działanie Wait | Gdy używasz działania Wait w potoku, potok czeka na określony czas przed kontynuowaniem wykonywania kolejnych działań. |
| Działanie internetowe | Działanie internetowe może służyć do wywoływania niestandardowego punktu końcowego REST z potoku. Można przekazywać zestawy danych i połączone usługi do zużycia i dostępu przez działanie. |
| Działanie elementu webhook | Za pomocą działania elementu webhook wywołaj punkt końcowy i przekaż adres URL wywołania zwrotnego. Uruchomienie potoku czeka na wywołanie zwrotne przed przejściem do następnego działania. |
Tworzenie potoku za pomocą interfejsu użytkownika
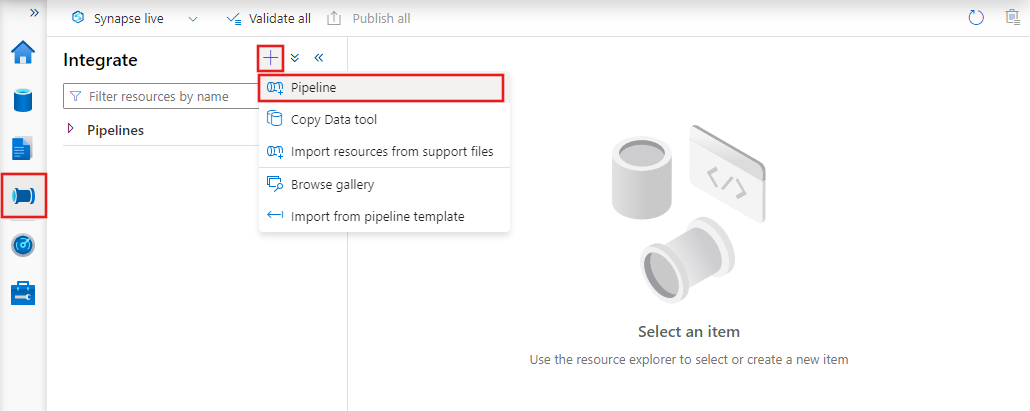
Aby utworzyć nowy potok, przejdź do karty Autor w narzędziu Data Factory Studio (reprezentowanej przez ikonę ołówka), a następnie kliknij znak plus i wybierz pozycję Potok z menu, a następnie ponownie pozycję Potok z podmenu.
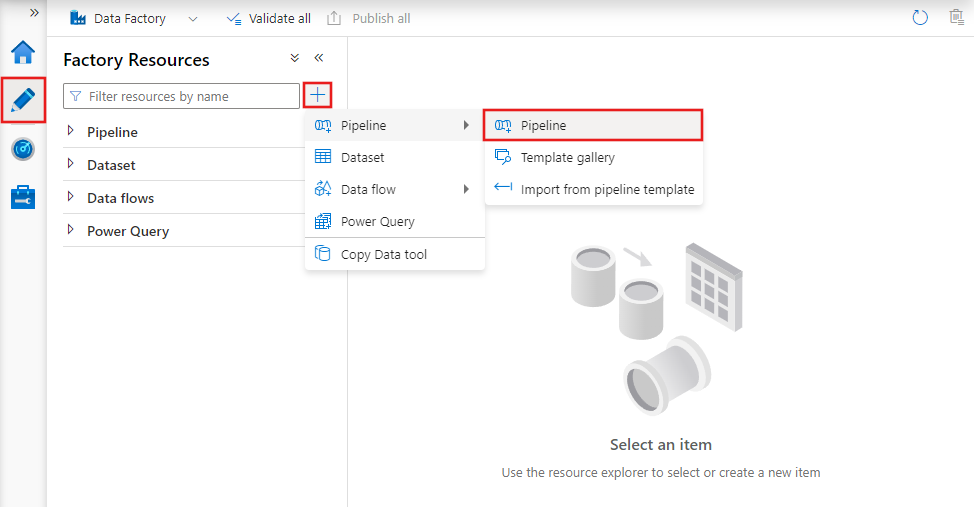
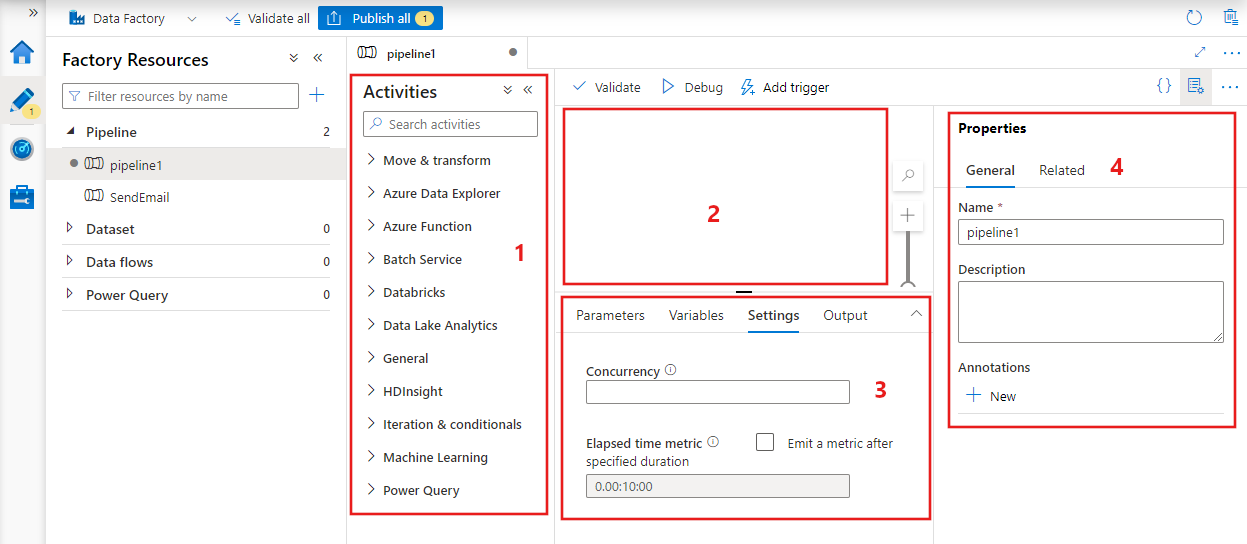
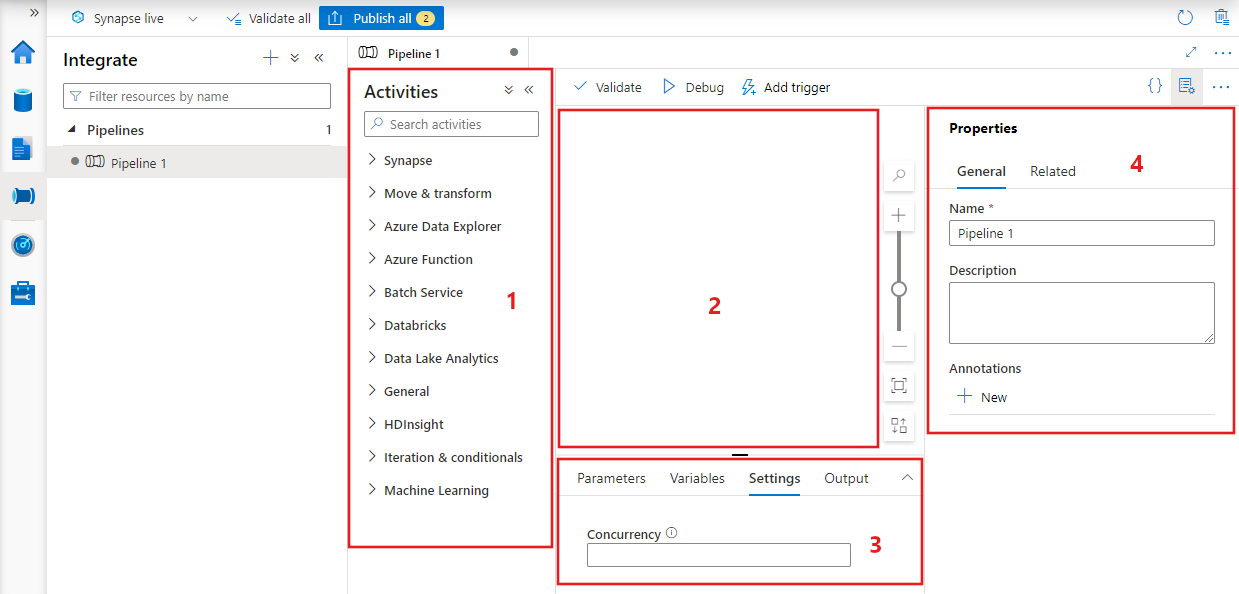
W usłudze Data Factory zostanie wyświetlony edytor potoków, w którym można znaleźć:
- Wszystkie działania, które mogą być używane w potoku.
- Kanwa edytora potoków, na której będą wyświetlane działania po dodaniu do potoku.
- Okienko konfiguracji potoku, w tym parametry, zmienne, ustawienia ogólne i dane wyjściowe.
- Okienko właściwości potoku, w którym można skonfigurować nazwę potoku, opcjonalny opis i adnotacje. W tym okienku zostaną również wyświetlone wszystkie powiązane elementy potoku w fabryce danych.
Kod JSON potoku
Poniżej przedstawiono sposób definiowania potoku w formacie JSON:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Tag | opis | Type | Wymagania |
|---|---|---|---|
| name | Nazwa potoku. Określ nazwę, która reprezentuje akcję wykonywaną przez potok.
|
String | Tak |
| opis | Wprowadź tekst opisujący przeznaczenie potoku. | String | Nie |
| activities | W sekcji activities można zdefiniować jedno lub więcej działań. Sprawdź sekcję Format JSON działania, aby uzyskać szczegółowe informacje na temat elementu JSON activities. | Tablica | Tak |
| parameters | Sekcja parameters może zawierać jeden lub kilka parametrów zdefiniowanych w potoku, co zwiększa elastyczność i możliwość ponownego zastosowania potoku. | List | Nie. |
| współbieżność | Maksymalna liczba współbieżnych przebiegów, które może mieć potok. Domyślnie nie ma maksymalnej wartości. Jeśli osiągnięto limit współbieżności, dodatkowe uruchomienia potoków są kolejkowane do czasu ukończenia wcześniejszych | Liczba | Nie. |
| Adnotacje | Lista tagów skojarzonych z potokiem | Tablica | Nie. |
Format JSON działania
W sekcji activities można zdefiniować jedno lub więcej działań. Istnieją dwa główne typy działań: działania wykonywania i sterowania.
Działania wykonywania
Działania wykonywania obejmują działania przenoszenia danych i działania przekształcania danych. Ich struktura najwyższego poziomu wygląda następująco:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
Poniższa tabela zawiera opis właściwości w definicji JSON działania:
| Tag | opis | Wymagania |
|---|---|---|
| name | Nazwa działania. Określ nazwę, która reprezentuje akcję wykonywaną przez działanie.
|
Tak |
| opis | Tekst opisujący przeznaczenie działania | Tak |
| type | Typ działania. Poszczególne typy działań opisano w sekcjach Działania przenoszenia danych, Działania przekształcania danych i Działania sterowania. | Tak |
| linkedServiceName | Nazwa połączonej usługi używana na potrzeby działania. Działanie może wymagać określenia połączonej usługi, która łączy się z wymaganym środowiskiem obliczeniowym. |
Tak w przypadku działania usługi HDInsight, działania oceniania wsadowego ml Studio (klasycznego), działania procedury składowanej. Nie dla wszystkich innych |
| typeProperties | Właściwości w sekcji typeProperties zależą od typu działania. Aby wyświetlić właściwości typu dla działania, kliknij linki do działań w poprzedniej sekcji. | Nie. |
| policy | Zasady, które mają wpływ na zachowanie działania w czasie wykonania. Ta właściwość zawiera limit czasu i zachowanie ponawiania prób. Jeśli nie zostanie określony, zostaną użyte wartości domyślne. Więcej informacji można znaleźć w sekcji Zasady działania. | Nie. |
| dependsOn | Ta właściwość jest używana do definiowania zależności działania oraz sposobu, w jaki kolejne działania zależą od poprzednich działań. Więcej informacji można znaleźć w sekcji Zależności działania | Nie. |
Zasady dotyczące działań
Zasady wpływają na zachowanie działania w czasie wykonywania, dając opcje konfiguracji. Zasady działania są dostępne tylko dla działań wykonywania.
Definicja JSON zasad działania
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| Nazwa JSON | opis | Dozwolone wartości | Wymagania |
|---|---|---|---|
| timeout | Określa limit czasu pracy działania. | Zakres czasu | L.p. Domyślny limit czasu to 12 godzin, co najmniej 10 minut. |
| Spróbuj ponownie | Maksymalna liczba ponownych prób | Integer | L.p. Wartość domyślna to 0 |
| retryIntervalInSeconds | Opóźnienie między ponownymi próbami w sekundach | Integer | L.p. Wartość domyślna to 30 sekund |
| secureOutput | Po ustawieniu wartości true dane wyjściowe z działania są uznawane za bezpieczne i nie są rejestrowane do monitorowania. | Wartość logiczna | L.p. Wartość domyślna to „fałsz”. |
Działanie sterowania
Działania sterowania mają następującą strukturę najwyższego poziomu:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Tag | opis | Wymagania |
|---|---|---|
| name | Nazwa działania. Określ nazwę, która reprezentuje akcję wykonywaną przez działanie.
|
Tak |
| opis | Tekst opisujący przeznaczenie działania | Tak |
| type | Typ działania. Poszczególne typy działań opisano w sekcjach Działania przenoszenia danych, Działania przekształcania danych i Działania sterowania. | Tak |
| typeProperties | Właściwości w sekcji typeProperties zależą od typu działania. Aby wyświetlić właściwości typu dla działania, kliknij linki do działań w poprzedniej sekcji. | Nie. |
| dependsOn | Ta właściwość jest używana do definiowania zależności działania oraz sposobu, w jaki kolejne działania zależą od poprzednich działań. Więcej informacji można znaleźć w sekcji Zależność działania. | Nie. |
Zależność działania
Zależność działania określa, w jaki sposób kolejne działania zależą od poprzednich działań, określając warunek kontynuowania wykonywania następnego zadania. Działanie może zależeć od jednego lub wielu poprzednich działań, z różnymi warunkami zależności.
Różne warunki zależności to: Succeeded (powodzenie), Failed (niepowodzenie), Skipped (pominięto) i Completed (ukończono).
Jeśli na przykład potok ma działanie A —> Działanie B, różne scenariusze, które mogą się zdarzyć, to:
- Działanie B zawiera warunek zależności dla Działanie A z parametrem succeeded: Działanie B jest uruchamiane tylko wtedy, gdy ostateczny stan Działania A to succeeded
- Działanie B zawiera warunek zależności dla Działanie A z parametrem failed: Działanie B jest uruchamiane tylko wtedy, gdy ostateczny stan Działania A to failed
- Działanie B zawiera warunek zależności dla Działanie A z parametrem completed: Działanie B jest uruchamiane tylko wtedy, gdy ostateczny stan Działania A to succeeded lub failed
- Działanie B ma warunek zależności od działania A z pominiętym: działanie B jest uruchamiane, jeśli działanie A ma ostateczny stan pominiętego. Pominięte występuje w scenariuszu Działania X —> Działanie Y —> Działanie Z, gdzie każde działanie jest uruchamiane tylko wtedy, gdy poprzednie działanie powiedzie się. Jeśli działanie X nie powiedzie się, a następnie działanie Y ma stan "Pominięto", ponieważ nigdy nie jest wykonywane. Podobnie działanie Z ma również stan "Pominięto".
Przykład: Działanie 2 zależy od pomyślnego zakończenia Działania 1
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Przykładowy potok kopiowania
W poniższym przykładowym potoku występuje jedno działanie typu Copy w sekcji activities. W tym przykładzie działanie kopiowania kopiuje dane z usługi Azure Blob Storage do bazy danych w usłudze Azure SQL Database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Należy uwzględnić następujące informacje:
- W sekcji działań jest tylko jedno działanie, którego parametr type (typ) został ustawiony na wartość Copy.
- Dane wejściowe dla działania mają ustawienie InputDataset, a dane wyjściowe — OutputDataset. Definiowanie zestawów danych w formacie JSON opisano w artykule Zestawy danych.
- W sekcji typeProperties parametr BlobSource został określony jako typ źródłowy, a parametr SqlSink został określony jako typ ujścia. W sekcji działania ruchu danych kliknij magazyn danych, którego chcesz użyć jako źródła lub ujścia, aby uzyskać dodatkowe informacje na temat przenoszenia danych z/do tego magazynu danych.
Aby zapoznać się z kompletnym przewodnikiem tworzenia tego potoku, zobacz Szybki start: tworzenie fabryki danych.
Przykładowy potok przekształcania
W poniższym przykładowym potoku występuje jedno działanie typu HDInsightHive w sekcji activities. W tym przykładzie działanie HDInsight Hive przekształca dane z usługi Azure Blob Storage przez uruchomienie pliku skryptu Hive na klastrze usługi Azure HDInsight Hadoop.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Należy uwzględnić następujące informacje:
- W sekcji działań jest tylko jedno działanie, którego parametr type został ustawiony na wartość HDInsightHive.
- Plik skryptu hive partitionweblogs.hql jest przechowywany na koncie usługi Azure Storage (określonym przez scriptLinkedService o nazwie AzureStorageLinkedService) i w folderze script w kontenerze
adfgetstarted. - Sekcja
definessłuży do określania ustawień środowiska uruchomieniowego, które są przekazywane do skryptu Hive jako wartości konfiguracyjne magazynu Hive (np. ${hiveconf:inputtable},${hiveconf:partitionedtable}).
Sekcja typeProperties jest inna dla każdego działania przekształcania. Aby uzyskać informacje na temat właściwości typu obsługiwanych dla działania przekształcania, kliknij działanie przekształcania w sekcji Działania przekształcania danych.
Aby uzyskać szczegółowy przewodnik tworzenia tego potoku, zobacz Tutorial: transform data using Spark (Szybki start: przekształcanie danych przy użyciu usługi Spark).
Wiele działań w potoku
Poprzednie dwa przykładowe potoki zawierają tylko po jednym działaniu. Potok może obejmować więcej niż jedno działanie. Jeśli masz wiele działań w potoku, a kolejne działania nie są zależne od poprzednich działań, działania mogą być uruchamiane równolegle.
Można połączyć dwa działania przy użyciu zależności działania, która definiuje, w jaki sposób kolejne działania zależą od poprzednich działań, określając warunek kontynuowania wykonywania kolejnego działania. Działanie może zależeć od jednego lub kilku poprzednich działań, z różnymi warunkami zależności.
Planowanie potoków
Planowanie potoków odbywa się przy użyciu wyzwalaczy. Istnieją różne typy wyzwalaczy (wyzwalacz harmonogramu, który umożliwia wyzwalanie potoków zgodnie z harmonogramem zegara, a także wyzwalacz ręczny, który wyzwala potoki na żądanie). Więcej informacji na temat wyzwalaczy zawiera artykuł na temat wykonywania potoku i wyzwalaczy.
Aby wyzwalacz uruchamiał potok, należy dołączyć odwołanie do konkretnego potoku do definicji wyzwalacza. Między potokami i wyzwalaczami występuje relacja typu „wiele do wielu”. Wiele wyzwalaczy może uruchamiać jeden potok, a jeden wyzwalacz może uruchamiać wiele potoków. Po zdefiniowaniu wyzwalacza należy go uruchomić, aby rozpoczął wyzwalanie potoków. Więcej informacji na temat wyzwalaczy zawiera artykuł na temat wykonywania potoku i wyzwalaczy.
Załóżmy na przykład, że masz wyzwalacz harmonogramu "Trigger A", że chcę uruchomić potok "MyCopyPipeline". Zdefiniujesz wyzwalacz, jak pokazano w poniższym przykładzie:
Definicja wyzwalacza Trigger A
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}