Pipeline e attività in Azure Data Factory e Azure Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Importante
Il supporto di Azure Machine Learning Studio (versione classica) terminerà il 31 agosto 2024. Si consiglia di passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non è possibile creare nuove risorse (area di lavoro e piano di servizio Web) dello di Machine Learning Studio (versione classica). Fino al 31 agosto 2024 è possibile continuare a usare gli esperimenti e i servizi Web esistenti di Machine Learning Studio (versione classica). Per altre informazioni, vedi:
- Migrare a Azure Machine Learning da Machine Learning Studio (versione classica)
- Cos'è Azure Machine Learning?
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Questo articolo fornisce informazioni sulle pipeline e sulle attività in Azure Data Factory e Azure Synapse Analytics e su come usarle per creare flussi di lavoro completi basati sui dati per gli scenari di elaborazione e trasferimento dei dati.
Panoramica
Un'area di lavoro di Data Factory o Synapse può avere una o più pipeline. Una pipeline è un raggruppamento logico di attività che insieme eseguono un'operazione. Una pipeline, ad esempio, può contenere un set di attività che inseriscono e puliscono i dati di log e quindi avviano un flusso di dati di mapping per analizzare i dati di log. La pipeline consente di gestire le attività come un set anziché singolarmente. Si distribuisce e si pianifica la pipeline anziché ogni attività in modo indipendente.
Le attività in una pipeline definiscono le azioni da eseguire sui dati. Ad esempio, è possibile usare un'attività di copia per copiare i dati da un Server SQL a un archivio BLOB di Azure. Usare quindi un'attività di flusso di dati o un'attività dei notebook di Databricks per elaborare e trasformare i dati dall'archivio BLOB in un pool di Azure Synapse Analytics, in cui vengono compilate soluzioni di creazione di report di business intelligence.
Azure Data Factory e Azure Synapse Analytics hanno tre raggruppamenti di attività: attività di spostamento dei dati, attività di trasformazione dei dati e attività di controllo. Un'attività può non avere alcun set di dati di input o può averne più di uno e generare uno o più set di dati di output. Nel diagramma seguente viene illustrata la relazione tra pipeline, attività e set di dati:

Un set di dati di input rappresenta l'input per un'attività nella pipeline, un set di dati di output rappresenta l'output dell'attività. I set di dati identificano i dati all'interno dei diversi archivi dati, come tabelle, file, cartelle e documenti. Dopo aver creato un set di dati, è possibile usarlo con le attività in una pipeline. Ad esempio, un set di dati può essere configurato come set di dati di input o di output di un'attività di copia o un'attività HDInsightHive. Per altre informazioni sui set di dati, vedere l'articolo Set di dati in Azure Data Factory.
Nota
Esiste un limite predefinito di 80 attività per ogni pipeline, che include le attività interne per i contenitori.
Attività di spostamento dei dati
L'attività di copia in Data Factory esegue la copia dei dati da un archivio dati di origine a un archivio dati sink. Il servizio Data Factory supporta gli archivi dati elencati nella tabella in questa sezione. I dati da qualsiasi origine possono essere scritti in qualsiasi sink.
Per altre informazioni, vedere l'articolo Copy Activity in Azure Data Factory (Attività di copia in Azure Data Factory).
Fare clic su un archivio dati per informazioni su come copiare dati da e verso tale archivio.
Nota
Se un connettore è contrassegnato come anteprima, è possibile provarlo e inviare feedback. Se si vuole accettare una dipendenza dai connettori in versione di anteprima nella propria soluzione, contattare il supporto tecnico di Azure.
Attività di trasformazione dei dati
Azure Data Factory e Azure Synapse Analytics supportano le attività di trasformazione seguenti che possono essere aggiunte singolarmente o concatenati con un'altra attività.
Per altre informazioni, vedere l'articolo Attività di trasformazione dei dati.
| Attività di trasformazione dei dati | Ambiente di calcolo |
|---|---|
| Flusso di dati | Cluster Apache Spark gestiti da Azure Data Factory |
| Funzione di Azure | Funzioni di Azure |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop Streaming | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Attività di Studio di Azure Machine Learning (versione classica): esecuzione batch e aggiornamento risorse | Macchina virtuale di Azure |
| Stored procedure | Azure SQL, Azure Synapse Analytics o SQL Server |
| U-SQL | Azure Data Lake Analytics. |
| Attività personalizzata | Azure Batch |
| Notebook di Databricks | Azure Databricks |
| Attività JAR di Databricks | Azure Databricks |
| Attività Python di Databricks | Azure Databricks |
| Attività di Synapse Notebook | Azure Synapse Analytics |
Attività del flusso di controllo
Sono supportate le seguenti attività del flusso di controllo:
| Attività di controllo | Descrizione |
|---|---|
| Accoda variabile | Aggiungere un valore a una variabile di matrice esistente. |
| Esegui pipeline | L'attività Execute Pipeline consente a una pipeline di Data Factory o Synapse di richiamare un'altra pipeline. |
| Filtra | Applicare un'espressione di filtro a una matrice di input |
| For each | L'attività ForEach definisce un flusso di controllo ripetuto nella pipeline. Questa attività viene usata per eseguire l'iterazione di una raccolta e attività specifiche in un ciclo. L'implementazione in cicli di questa attività è simile alla struttura di esecuzione in cicli Foreach nei linguaggi di programmazione. |
| Ottenere metadati | L'attività GetMetadata può essere usata per recuperare i metadati di qualsiasi dato in una pipeline Data Factory o Synapse. |
| Attività della condizione If | Può essere usata per creare un ramo in base alla condizione che il valore restituito sia true o false. L'attività IfCondition svolge la stessa funzione dell'istruzione If nei linguaggi di programmazione. Valuta un set di attività se la condizione restituisce true e un altro set di attività se la condizione restituisce false. |
| Attività Lookup | L'attività Lookup può essere usata per la lettura o la ricerca di un record/nome di tabella/valore da qualsiasi origine esterna. Questo output può essere referenziato ulteriormente dalle attività successive. |
| Impostare una variabile | Impostare il valore di una variabile esistente. |
| Attività Until | Implementa il ciclo Do-Until che è simile alla struttura di esecuzione cicli Do-Until nei linguaggi di programmazione. Esegue infatti un set di attività in un ciclo finché la condizione associata con l'attività restituisce true. È possibile specificare un valore di timeout per l'attività Until. |
| Attività di convalida | Verificare che una pipeline continui l'esecuzione solo se esiste un set di dati di riferimento, soddisfi i criteri specificati o che sia stato raggiunto un timeout. |
| Attività Wait | Quando si usa un'attività Wait in una pipeline, la pipeline attende per il periodo di tempo specificato prima di proseguire con l'esecuzione delle attività successive. |
| Attività Web | È possibile usare l'attività Web per chiamare un endpoint REST personalizzato da una pipeline. È possibile passare set di dati e servizi collegati in modo che l'attività possa usarli e accedervi. |
| Attività Webhook | Usando l'attività webhook, chiamare un endpoint e passare un URL di callback. L'esecuzione della pipeline attende che il callback venga richiamato prima di procedere all'attività successiva. |
Creazione di una pipeline con l'interfaccia utente
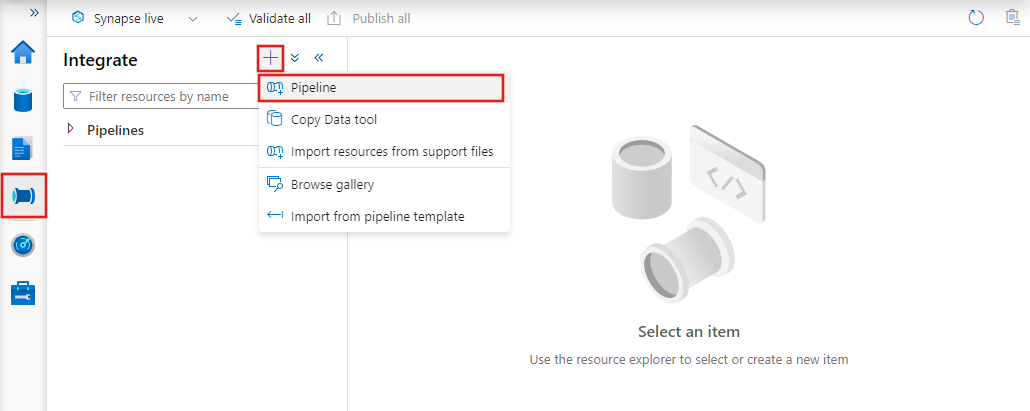
Per creare una nuova pipeline, passare alla scheda Autore in Data Factory Studio (rappresentata dall'icona a forma di matita), quindi fare clic sul segno più e scegliere Pipeline dal menu e di nuovo Pipeline dal sottomenu.
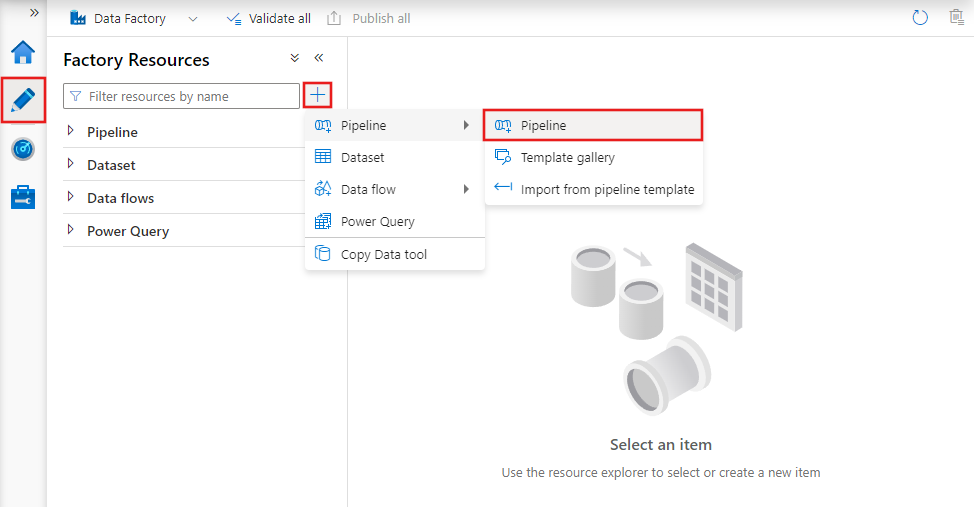
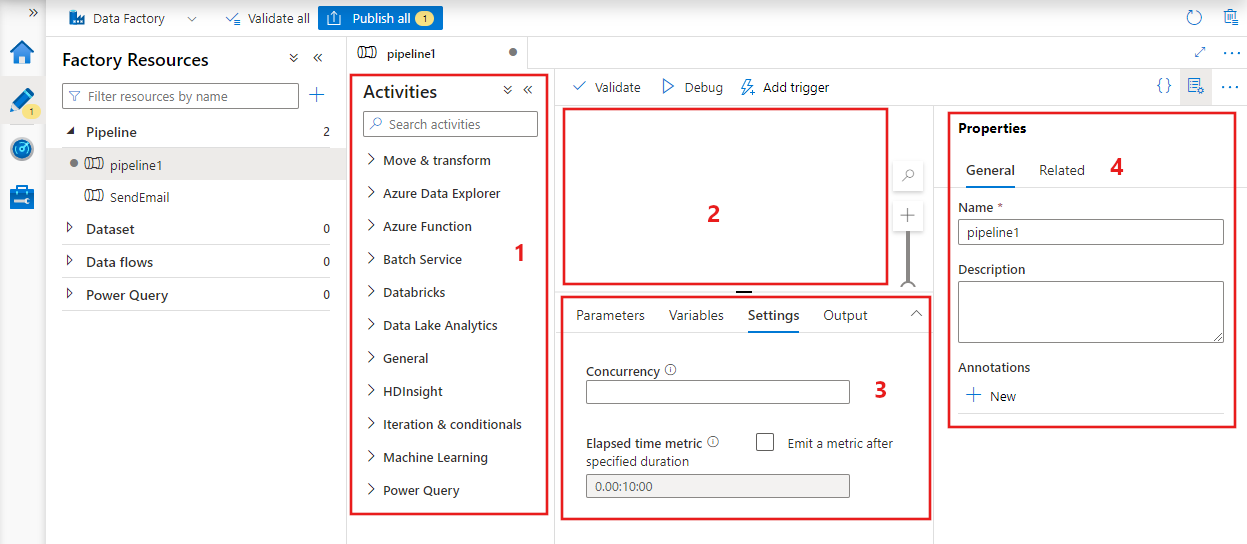
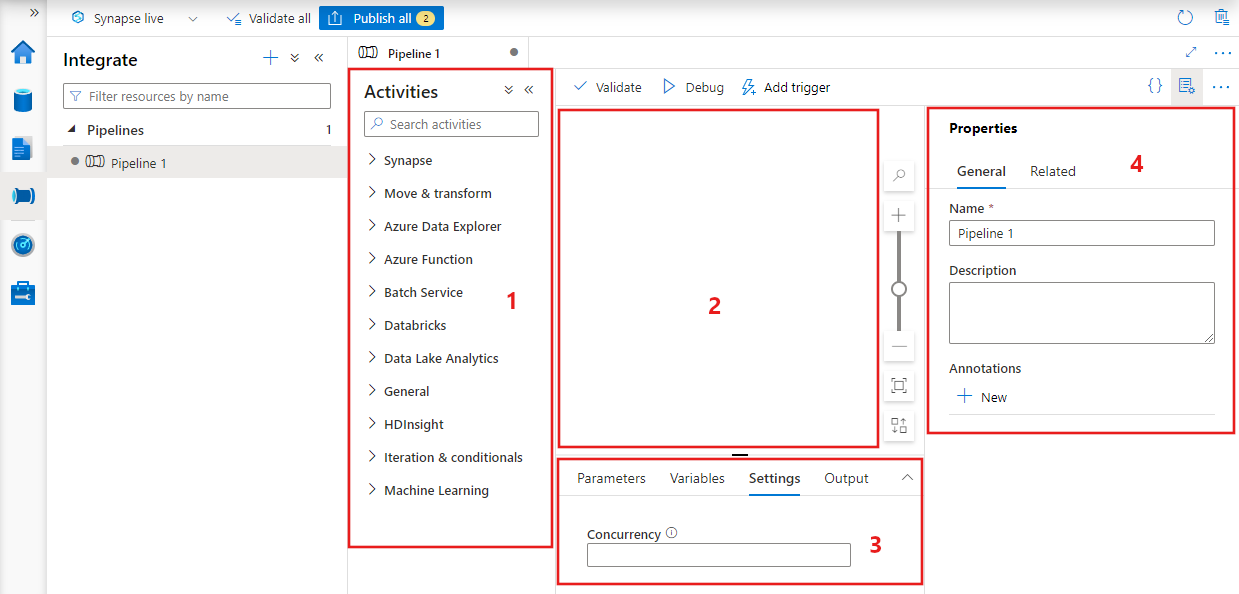
Data factory visualizzerà l'editor della pipeline in cui è possibile trovare:
- Tutte le attività che è possibile usare all'interno della pipeline.
- Canvas dell'editor di pipeline, in cui le attività verranno visualizzate quando vengono aggiunte alla pipeline.
- Riquadro delle configurazioni della pipeline, inclusi parametri, variabili, impostazioni generali e output.
- Riquadro delle proprietà della pipeline, in cui è possibile configurare il nome della pipeline, la descrizione facoltativa e le annotazioni. Questo riquadro mostrerà anche tutti gli elementi correlati alla pipeline all'interno della data factory.
Pipeline JSON
Ecco come una pipeline viene definita in formato JSON:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Tag | Descrizione | Type | Obbligatorio |
|---|---|---|---|
| name | Nome della pipeline. Specificare un nome che rappresenti l'azione eseguita dalla pipeline.
|
String | Sì |
| description | Specificare il testo descrittivo che illustra lo scopo della pipeline. | Stringa | No |
| activities | Nella sezione delle attività possono essere definite una o più attività. Vedere la sezione relativa al formato JSON delle attività per informazioni dettagliate sull'elemento JSON delle attività. | Matrice | Sì |
| parameters | La sezione parameters può avere uno o più parametri definiti all'interno della pipeline, assicurando la flessibilità per il riutilizzo della pipeline. | List | No |
| concurrency | Il numero massimo di esecuzioni simultanee che la pipeline può avere. Per impostazione predefinita, non è presente alcun valore massimo. Se viene raggiunto il limite di concorrenza, le esecuzioni di pipeline aggiuntive vengono accodate fino al completamento di quelle precedenti | Numero | No |
| annotations | Elenco di tag associati alla pipeline | Matrice | No |
Attività JSON
Nella sezione delle attività possono essere definite una o più attività. Esistono due tipi principali di attività: attività di esecuzione e di controllo.
Attività di esecuzione
Includono le attività di spostamento dei dati e di trasformazione dei dati. Presentano la seguente struttura di primo livello:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
La tabella seguente descrive le proprietà all'interno della definizione JSON dell'attività:
| Tag | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'impegno. Specificare un nome che rappresenti l'azione eseguita dall'attività.
|
Sì |
| description | Testo descrittivo per il tipo o lo scopo dell'attività | Sì |
| type | Tipo di attività. Per informazioni sui diversi tipi di attività, vedere le sezioni Attività di spostamento dei dati, Attività di trasformazione dei dati e Attività di controllo. | Sì |
| linkedServiceName | Nome del servizio collegato usato dall'attività. Per un'attività potrebbe essere necessario specificare il servizio collegato che collega all'ambiente di calcolo richiesto. |
Sì per l'attività HDInsight, l'attività di assegnazione dei punteggi batch di ML Studio (versione classica) e l'attività stored procedure. No per tutto il resto |
| typeProperties | Le proprietà nella sezione typeProperties dipendono da ogni tipo di attività. Per visualizzare le proprietà del tipo per un'attività, fare clic sui collegamenti all'attività nella sezione precedente. | No |
| Criterio | Criteri che influiscono sul comportamento di runtime dell'attività. Questa proprietà include un comportamento di timeout e ripetizione. Se queste impostazioni non vengono specificate, vengono usati i valori predefiniti. Per altre informazioni, vedere la sezione Criteri di attività. | No |
| dependsOn | Questa proprietà viene usata per definire le dipendenze delle attività e come le attività successive dipendono dalle attività precedenti. Per altre informazioni, vedere Dipendenza delle attività. | No |
Criteri attività
Criteri che influiscono sul comportamento runtime di un'attività, offrendo le opzioni di configurazione. I criteri delle attività sono disponibili solo per le attività di esecuzione.
Definizione JSON dei criteri di attività
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| Nome JSON | Descrizione | Valori consentiti | Richiesto |
|---|---|---|---|
| timeout | Specifica il timeout per l'attività da eseguire. | TimeSpan | No. Il timeout predefinito è 12 ore, minimo 10 minuti. |
| retry | Numero massimo di tentativi | Intero | No. Il valore predefinito è 0 |
| retryIntervalInSeconds | Il ritardo tra tentativi di ripetizione espresso in secondi | Intero | No. Il valore predefinito è 30 secondi |
| secureOutput | Se impostato su true, l'output dell'attività viene considerato sicuro e non viene registrato per il monitoraggio. | Booleano | No. Il valore predefinito è false. |
Attività di controllo
Le attività di controllo presentano la seguente struttura di primo livello:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Tag | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'impegno. Specificare un nome che rappresenti l'azione eseguita dall'attività.
|
Sì |
| description | Testo descrittivo per il tipo o lo scopo dell'attività | Sì |
| type | Tipo di attività. Per informazioni sui diversi tipi di attività, vedere le sezioni Attività di spostamento dei dati, Attività di trasformazione dei dati e Attività di controllo. | Sì |
| typeProperties | Le proprietà nella sezione typeProperties dipendono da ogni tipo di attività. Per visualizzare le proprietà del tipo per un'attività, fare clic sui collegamenti all'attività nella sezione precedente. | No |
| dependsOn | Questa proprietà viene usata per definire la dipendenza delle attività e come le attività successive dipendono dalle attività precedenti. Per altre informazioni, vedere la Dipendenza delle attività. | No |
Dipendenza di attività
La dipendenza delle attività definisce in che modo le attività successive dipendono dalle attività precedenti, determinando la condizione dell'eventuale esecuzione dell'attività successiva. Un'attività può dipendere da una o più attività precedenti con condizioni di dipendenza diverse.
Le diverse condizioni di dipendenza sono: Succeeded (esito positivo), Failed (esito negativo), Skipped (operazione ignorata), Completed (operazione completata).
Ad esempio, se una pipeline dispone di un'attività A-> Attività B, i diversi scenari possibili sono:
- L'attività B ha una condizione di dipendenza dall'attività A con succeeded: l'attività B viene eseguita solo se lo stato finale dell'attività A è con esito positivo.
- L'attività B ha una condizione di dipendenza dall'attività A con failed: l'attività B viene eseguita solo se lo stato finale dell'attività A è con esito negativo.
- L'attività B ha una condizione di dipendenza dall'attività A con completed: l'attività B viene eseguita solo se lo stato finale dell'attività A è con esito positivo o negativo.
- L'attività B ha una condizione di dipendenza dall'attività A con operazione ignorata: l'attività B viene eseguita se lo stato finale dell'attività A è di operazione ignorata. Lo stato Operazione ignorata si verifica nello scenario Attività X -> Attività Y -> Attività Z, in cui ogni attività viene eseguita solo se l'attività precedente ha esito positivo. Se l'attività X ha esito negativo, lo stato dell'attività Y è "Operazione ignorata" perché non viene mai eseguita. Analogamente, anche lo stato dell'attività Z è "Operazione ignorata".
Esempio: l'attività 2 dipende dall'esito positivo dell'attività 1
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Esempio di una pipeline di copia
In questa pipeline di esempio è presente un'attività di tipo Copy in the attività . In questo esempio, Copia attività consente di copiare i dati da un archivio BLOB di Azure a un database in Database Azure SQL.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Tenere presente quanto segue:
- Nella sezione delle attività esiste una sola attività con l'oggetto type impostato su Copy.
- L'input per l'attività è impostato su InputDataset e l'output è impostato su OutputDataset. Vedere l'articolo Set di dati per la definizione di set di dati in JSON.
- Nella sezione typeProperties vengono specificati BlobSource come tipo di origine e SqlSink come tipo di sink. Nella sezione Attività di spostamento dati scegliere l'archivio dati che si vuole usare come origine o sink per avere altre informazioni sullo spostamento dei dati da e verso tale archivio dati.
Per la procedura dettagliata sulla creazione di questa pipeline, vedere Avvio rapido: Creare una data factory.
Esempio di una pipeline di trasformazione
In questa pipeline di esempio è presente un'attività di tipo HDInsightHive in the attività . In questo esempio, l' attività Hive di HDInsight trasforma i dati da un archivio BLOB di Azure tramite l'esecuzione di un file di script Hive in un cluster Hadoop di HDInsight.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Tenere presente quanto segue:
- Nella sezione attività esiste una sola attività con l'oggetto type impostato su HDInsightHive.
- Il file di script Hive, partitionweblogs.hql, viene archiviato nell'account di archiviazione di Azure (specificato da scriptLinkedService, denominato AzureStorageLinkedService) e nella cartella script nel contenitore
adfgetstarted. - La sezione
definesviene usata per specificare le impostazioni di runtime che vengono passate allo script Hive come valori di configurazione Hive, ad esempio{hiveconf:inputtable}e${hiveconf:partitionedtable}.
La sezione typeProperties è diversa per ogni attività di trasformazione. Per altre informazioni sulle proprietà del tipo supportate per un'attività di trasformazione, fare clic sull'attività di trasformazione nelle attività di trasformazione dei dati.
Per la procedura dettagliata sulla creazione di questa pipeline, vedere Esercitazione: Trasformare i dati usando Spark.
Attività multiple in una pipeline
Le due pipeline di due esempio precedenti contengono una sola attività. È possibile avere più di un'attività in una pipeline. Se sono disponibili più attività in una pipeline e le attività successive non dipendono da quelle precedenti, le attività potrebbero essere eseguite in parallelo.
È possibile concatenare due attività usando la dipendenza delle attività, che definisce in che modo le attività successive dipendono dalle attività precedenti, determinando la condizione se si passerà all'esecuzione dell'attività successiva. Un'attività può dipendere da una o più attività precedenti con condizioni di dipendenza diverse.
Pianificazione delle pipeline
Le pipeline vengono pianificate da trigger. Esistono diversi tipi di trigger (il trigger dell'utilità di pianificazione che consente di attivare le pipeline con una pianificazione basata sul tempo reale e il trigger manuale che attiva le pipeline su richiesta). Per altre informazioni sui trigger, vedere l'articolo Esecuzione e trigger di pipeline.
Per fare in modo che il trigger attivi l'esecuzione di una pipeline, è necessario includere un riferimento di pipeline della pipeline specifica nella definizione del trigger. Pipeline e trigger hanno una relazione n-m. Più trigger possono avviare una singola pipeline e lo stesso trigger può avviare più pipeline. Dopo che il trigger è stato definito è necessario avviarlo per iniziare ad attivare la pipeline. Per altre informazioni sui trigger, vedere l'articolo Esecuzione e trigger di pipeline.
Ad esempio, si può disporre di un trigger dell'utilità di pianificazione, "Trigger A", per avviare la pipeline, "MyCopyPipeline". Definire il trigger come illustrato nell'esempio seguente:
Definizione del trigger A
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}