Attività Copy in Azure Data Factory e Azure Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Nelle pipeline di Azure Data Factory e Synapse è possibile usare l'attività Copy per copiare i dati da archivi dati locali e cloud. Dopo aver copiato i dati, è possibile usare altre attività per trasformarli e analizzarli ulteriormente. L'attività Copy può essere usata anche per pubblicare risultati di trasformazione e analisi a scopi di business intelligence (BI) e per l'utilizzo da parte delle applicazioni.
L'attività Copy viene eseguita in un runtime di integrazione. È possibile usare tipi di runtime di integrazione diversi per scenari di copia dei dati diversi:
- Quando si copiano dati tra due archivi dati accessibili pubblicamente tramite Internet da qualsiasi IP, è possibile usare Azure Integration Runtime per l'attività Copy. Questo runtime di integrazione è sicuro, affidabile, scalabile e disponibile a livello globale.
- Quando si copiano i dati da e verso archivi dati ubicati in locale o in una rete con controllo di accesso (ad esempio, una rete virtuale di Azure), è necessario configurare un runtime di integrazione self-hosted.
Un runtime di integrazione deve essere associato a ogni archivio dati di origine e sink. Per informazioni su come l'attività Copy determina quale runtime di integrazione usare, vedere Determinare il runtime di integrazione da usare.
Nota
Non è possibile usare più di un runtime di integrazione self-hosted all'interno della stessa attività Copy. L'origine e il sink per l'attività devono essere connessi tramite lo stesso runtime di integrazione self-hosted.
Per copiare dati da un'origine a un sink, il servizio che esegue l'attività Copy esegue questi passaggi:
- Legge i dati dall'archivio dati di origine.
- Esegue la serializzazione/deserializzazione, compressione/decompressione, il mapping di colonne e così via. Esegue queste operazioni sulla base della configurazione del set di dati di input, del set di dati di output e dell'attività Copy.
- Scrive i dati nell'archivio dati sink/di destinazione.

Nota
Se un runtime di integrazione self-hosted viene usato in un archivio dati di origine o sink all'interno di un'attività Copy, affinché l'attività Copy venga completata correttamente sia l'origine che il sink devono essere accessibili dal server che ospita il runtime di integrazione.
Archivi dati e formati supportati
Nota
Se un connettore è contrassegnato come anteprima, è possibile provarlo e inviare feedback. Se si vuole accettare una dipendenza dai connettori in versione di anteprima nella propria soluzione, contattare il supporto tecnico di Azure.
Formati di file supportati
Azure Data Factory supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
- Formato Avro
- Formato binario
- Formato di testo delimitato
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
È possibile usare l'attività Copy per copiare i file così come sono tra due archivi dati basati su file. In questo caso i dati vengono copiati in modo efficiente senza serializzazione o deserializzazione. Inoltre, è anche possibile analizzare o generare file di un determinato formato, ad esempio è possibile eseguire queste operazioni:
- Copiare dati da un database di SQL Server e scrivere in Azure Data Lake Storage Gen2 in formato Parquet.
- Copiare file in formato testo (CSV) da un file system locale e scrivere nell'archiviazione BLOB in formato Avro.
- Copiare file compressi da un file system locale, decomprimerli in tempo reale e scrivere i file estratti in Azure Data Lake Storage Gen2.
- Copiare dati in formato testo (CSV) con compressione GZip dall'archiviazione BLOB e scrivere nel database SQL di Azure.
- Molte altre attività che richiedono serializzazione/deserializzazione o compressione/decompressione.
Aree geografiche supportate
Il servizio alla base dell'attività Copy è disponibile a livello globale nelle aree geografiche e nelle posizioni indicate tra le posizioni di Azure Integration Runtime. La topologia disponibile a livello globale garantisce uno spostamento di dati efficiente e di solito consente di evitare passaggi tra diverse aree. Vedere Prodotti per area per verificare la disponibilità di Data Factory, aree di lavoro Synapse e spostamento dei dati in un'area specifica.
Impostazione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- L'SDK Python
- Azure PowerShell
- L'API REST
- Modello di Azure Resource Manager
In generale, per usare l'attività Copy nelle pipeline di Azure Data Factory o Synapse, è necessario:
- Creare servizi collegati per l'archivio dati di origine e l'archivio dati sink. È possibile trovare un elenco dei connettori supportati nella sezione Archivi di dati e formati supportati di questo articolo. Per le informazioni di configurazione e le proprietà supportate, fare riferimento alla sezione "Proprietà del servizio collegato" dell'articolo sul connettore.
- Creare i set di dati per origine e sink. Per le informazioni di configurazione e le proprietà supportate, fare riferimento alle sezioni "Proprietà dei set di dati" degli articoli sui connettori di origine e sink.
- Creare una pipeline con l'attività Copy. Nella sezione seguente viene illustrato un esempio.
Sintassi
Il modello di attività Copy seguente contiene un elenco completo delle proprietà supportate. Specificare quelle più adatte per il proprio scenario.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Dettagli sintassi
| Proprietà | Descrizione | Obbligatorio? |
|---|---|---|
| type | Per un'attività Copy, impostare su Copy |
Sì |
| input | Specificare il set di dati creato che punta ai dati di origine. L'attività Copy supporta un singolo input. | Sì |
| outputs | Specificare il set di dati creato che punta ai dati sink. L'attività Copy supporta un singolo output. | Sì |
| typeProperties | Specificare le proprietà per configurare l'attività Copy. | Sì |
| source | Specificare il tipo di origine della copia e le proprietà corrispondenti per il recupero dei dati. Per altre informazioni, vedere la sezione "Proprietà dell'attività Copy" nell'articolo sul connettore elencato in Archivi dati e formati supportati. |
Sì |
| sink | Specificare il tipo di sink della copia e le proprietà corrispondenti per la scrittura dei dati. Per altre informazioni, vedere la sezione "Proprietà dell'attività Copy" nell'articolo sul connettore elencato in Archivi dati e formati supportati. |
Sì |
| translator | Specificare il mapping esplicito di colonne da origine a sink. Questa proprietà si applica quando il comportamento di copia predefinito non soddisfa le esigenze. Per altre informazioni, vedere Mapping dello schema nell'attività Copy. |
No |
| dataIntegrationUnits | Specificare una misura che rappresenti la quantità di potenza usata da Azure Integration Runtime per la copia dei dati. Queste unità erano precedentemente note come unità di spostamento dati cloud o DMU. Per altre informazioni, vedere Unità di integrazione dei dati. |
No |
| parallelCopies | Specificare il parallelismo che l'attività Copy deve usare durante la lettura dei dati dall'origine e la scrittura dei dati nel sink. Per altre informazioni, vedere Copia parallela. |
No |
| preserve | Specificare se mantenere metadati ed elenchi di controllo di accesso (ACL) durante la copia dei dati. Per altre informazioni, vedere Mantenere i metadati. |
No |
| enableStaging stagingSettings |
Specificare se eseguire lo staging dei dati provvisori nell'archiviazione BLOB anziché copiarli direttamente dall'origine al sink. Per informazioni su scenari utili e dettagli di configurazione, vedere Copia di staging. |
No |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Scegliere come gestire le righe incompatibili durante la copia di dati dall'origine al sink. Per altre informazioni, vedere Tolleranza di errore. |
No |
Monitoraggio
È possibile monitorare l'esecuzione dell'attività Copy nelle pipeline di Azure Data Factory e Synapse sia visivamente che a livello di codice. Per informazioni dettagliate, vedere Monitorare l'attività Copy pipeline.
Copia incrementale
Le pipeline di Data Factory e Synapse consentono di copiare in modo incrementale i dati differenziali da un archivio dati di origine a un archivio dati sink. Per informazioni dettagliate, vedere Esercitazione: Copiare dati in modo incrementale.
Prestazioni e ottimizzazione
L'esperienza di monitoraggio dell'attività Copy mostra le statistiche sulle prestazioni di copia per ogni esecuzione dell'attività. Nella Guida a prestazioni e scalabilità dell'attività Copy vengono descritti i fattori chiave che influiscono sulle prestazioni di spostamento dati tramite l'attività Copy. Vengono anche elencati i valori delle prestazioni osservati durante i test e vengono descritti i modi per ottimizzare le prestazioni dell'attività Copy.
Riprendere dall'ultima esecuzione non riuscita
L'attività Copy supporta la ripresa dall'ultima esecuzione non riuscita quando si copiano grandi dimensioni di file così come sono con formato binario tra archivi basati su file e si sceglie di mantenere la gerarchia di cartelle/file dall'origine al sink, ad esempio per eseguire la migrazione dei dati da Amazon S3 ad Azure Data Lake Storage Gen2. Si applica ai connettori basati su file seguenti: Amazon S3, Archiviazione compatibile con Amazon S3BLOB di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, File di Azure, File system, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage e SFTP.
È possibile sfruttare la ripresa dell'attività Copy nei due modi seguenti:
Retry a livello di attività: è possibile impostare il numero di retry per l'attività Copy. Durante l'esecuzione della pipeline, se l'esecuzione dell'attività Copy ha esito negativo, il retry automatico successivo inizierà dal punto di errore dell'ultimo tentativo.
Riesecuzione dall'attività non riuscita: dopo il completamento dell'esecuzione della pipeline è anche possibile attivare una riesecuzione dall'attività non riuscita nella visualizzazione di monitoraggio dell'interfaccia utente di Azure Data Factory o a livello di codice. Se l'attività non riuscita è un'attività Copy, la pipeline non solo verrà rieseguita a partire da questa attività, ma riprenderà anche dal punto di errore dell'esecuzione precedente.
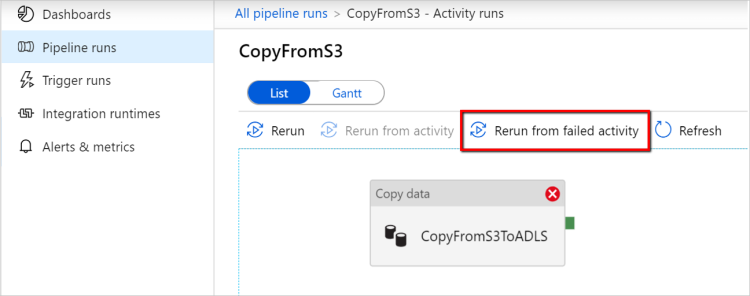
Alcuni punti da notare:
- La ripresa avviene a livello di file. Se l'attività Copy non riesce durante la copia di un file, nell'esecuzione successiva questo file specifico verrà copiato nuovamente.
- Per il corretto funzionamento della ripresa, non modificare le impostazioni dell'attività Copy tra le riesecuzioni.
- Quando si copiano dati da Amazon S3, BLOB di Azure, Azure Data Lake Storage Gen2 e Google Cloud Storage, l'attività Copy può riprendere da un numero arbitrario di file copiati. Per il resto dei connettori basati su file come origine, attualmente l'attività Copy supporta la ripresa da un numero limitato di file, in genere nell'ordine delle decine di migliaia, e varia a seconda della lunghezza dei percorsi dei file. I file oltre questo numero verranno copiati nuovamente durante le riesecuzioni.
Per scenari diversi dalla copia di file binari, la riesecuzione dell'attività di copia parte dall'inizio.
Mantenere i metadati insieme ai dati
Durante la copia dei dati dall'origine al sink, in scenari come la migrazione di Data Lake si può anche scegliere di mantenere i metadati e gli ACL insieme ai dati usando l'attività Copy. Per informazioni dettagliate, vedere Mantenere i metadati.
Aggiungere tag di metadati nel sink basato su file
Quando il sink è basato su Archiviazione di Azure (Azure Data Lake Storage o Archiviazione BLOB di Azure), è possibile scegliere di aggiungere alcuni metadati ai file. Questi metadati verranno visualizzati come parte delle proprietà del file come coppie chiave-valore. Per tutti i tipi di sink basati su file, è possibile aggiungere metadati che includono contenuto dinamico usando parametri della pipeline, variabili di sistema, funzioni e variabili. Oltre a questo, per il sink basato su file binario è possibile aggiungere la data e ora dell'ultima modifica (del file di origine) usando la parola chiave $$LASTMODIFIED, oltre che valori personalizzati sotto forma di metadati del file sink.
Mapping dello schema e dei tipi di dati
Vedere Mapping dello schema e dei tipi di dati per informazioni su come l'attività Copy esegue il mapping dei dati di origine al sink.
Aggiungere altre colonne durante la copia
Oltre a copiare dati dall'archivio dati di origine al sink, è anche possibile configurare l'aggiunta di altre colonne di dati da copiare nel sink. Ad esempio:
- Quando si copia da un'origine basata su file, archiviare il percorso del file relativo come colonna aggiuntiva per tenere traccia del file da cui provengono i dati.
- Duplicare la colonna di origine specificata come un'altra colonna.
- Aggiungere una colonna con un'espressione di Azure Data Factory per collegare variabili di sistema di Azure Data Factory, ad esempio il nome della pipeline o l'ID della pipeline, o archiviare un altro valore dinamico dall'output dell'attività upstream.
- Aggiungere una colonna con valore statico per soddisfare le esigenze di utilizzo downstream.
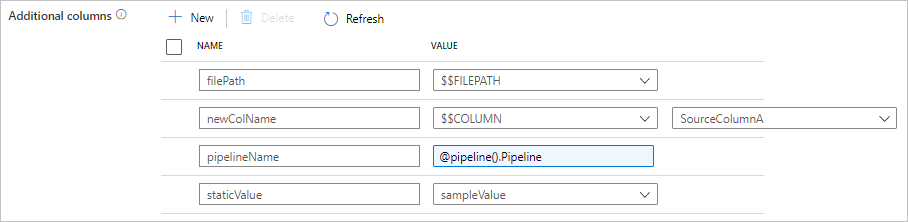
È possibile trovare la configurazione seguente nella scheda di origine dell'attività Copy. È anche possibile eseguire il mapping di tali colonne aggiuntive nel mapping dello schema dell'attività Copy come di consueto, usando i nomi di colonna definiti.
Suggerimento
Questa funzionalità funziona con il modello di set di dati più recente. Se questa opzione non compare nell'interfaccia utente, provare a creare un nuovo set di dati.
Per configurarla a livello di codice, aggiungere la proprietà additionalColumns nell'origine dell'attività Copy:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| additionalColumns | Aggiungere altre colonne di dati da copiare nel sink. Ogni oggetto sotto la matrice additionalColumns rappresenta una colonna aggiuntiva. name definisce il nome della colonna e value indica il valore dei dati di tale colonna.I valori dei dati consentiti sono: - $$FILEPATH: una variabile riservata indica di archiviare il percorso relativo dei file di origine al percorso della cartella specificato nel set di dati. Applicare all'origine basata su file.- $$COLUMN:<source_column_name>: un modello di variabile riservata indica di duplicare la colonna di origine specificata come un'altra colonna- Expression - Valore statico |
No |
Esempio:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Suggerimento
Dopo aver configurato colonne aggiuntive, ricordarsi di eseguirne il mapping al sink di destinazione, nella scheda Mapping.
Creare automaticamente tabelle del sink
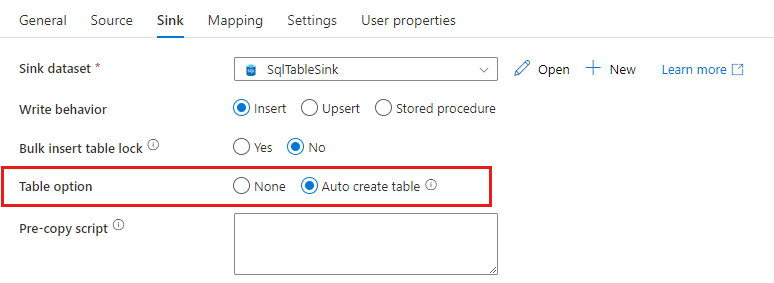
Quando si copiano dati nel database SQL o in Azure Synapse Analytics, se la tabella di destinazione non esiste l'attività Copy ne supporta la creazione automatica in base ai dati di origine. Lo scopo è permettere di iniziare rapidamente a caricare i dati e valutare il database SQL/Azure Synapse Analytics. Dopo l'inserimento dei dati, è possibile esaminare e modificare lo schema della tabella del sink in base alle esigenze.
Questa funzionalità è supportata quando si copiano dati da qualsiasi origine negli archivi dati sink seguenti. È possibile trovare l'opzione nell'interfaccia utente di creazione di Azure Data Factory ->Sink dell'attività Copy ->Opzione Tabella ->Crea tabella automaticamente o tramite la proprietà tableOption nel payload del sink dell'attività Copy.
Tolleranza di errore
Per impostazione predefinita, l'attività Copy interrompe la copia dei dati e restituisce un errore le righe di dati di origine sono incompatibili con le righe di dati del sink. Perché la copia vada a buon fine è possibile configurare l'attività Copy in modo da ignorare e registrare le righe incompatibili e copiare soltanto i dati compatibili. Per altri dettagli, vedere Tolleranza di errore dell'attività Copy.
Verifica della coerenza dei dati
Quando si spostano i dati dall'archivio di origine a quello di destinazione, l'attività Copy offre un'opzione che consente di eseguire ulteriori verifiche di coerenza dei dati per garantire non solo che i dati vengano copiati correttamente dall'archivio di origine all'archivio di destinazione, ma anche che siano coerenti tra l'archivio di origine e quello di destinazione. Se vengono trovati dati incoerenti durante lo spostamento dati, è possibile interrompere l'attività Copy o continuare a copiare il resto abilitando l'impostazione di tolleranza di errore per ignorare i file incoerenti. È possibile ottenere i nomi dei file ignorati abilitando l'impostazione del log della sessione nell'attività Copy. Per informazioni dettagliate, vedere Verifica della coerenza dei dati nell'attività Copy.
Log di sessione
È possibile registrare i nomi dei file copiati. L'esame dei log di sessione dell'attività Copy offre un'ulteriore possibilità di verificare che i dati non solo vengano copiati correttamente dall'archivio di origine a quello di destinazione, ma anche che siano coerenti tra l'archivio di origine e quello di destinazione. Per informazioni dettagliate, vedere Log di sessione dell'attività Copy.
Contenuto correlato
Vedere le guide rapide, le esercitazioni e gli esempi seguenti:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per