Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Edytor bez kodu ułatwia opracowywanie zadania usługi Stream Analytics w celu przetwarzania danych przesyłanych strumieniowo w czasie rzeczywistym. Używaj funkcji przeciągania i upuszczania bez konieczności pisania kodu. Środowisko udostępnia kanwę, na której można łączyć się ze źródłami wejściowymi, aby szybko wyświetlać dane przesyłane strumieniowo. Następnie możesz zmodyfikować go przed zapisem na miejscach docelowych.
Za pomocą edytora no-code można łatwo:
- Modyfikowanie schematów wejściowych.
- Wykonywanie operacji przygotowywania danych, takich jak sprzężenia i filtry.
- Podejmij się zaawansowanych scenariuszy, takich jak agregacje okien czasowych (okna skokowe, okna przeskakujące i okna sesji) dla operacji grupowania według kryteriów.
Po utworzeniu i uruchomieniu zadań usługi Stream Analytics można łatwo operacjonalizować obciążenia produkcyjne. Użyj odpowiedniego zestawu wbudowanych metryk na potrzeby monitorowania i rozwiązywania problemów. Zadania usługi Stream Analytics są rozliczane zgodnie z modelem cenowym , gdy są uruchomione.
Wymagania wstępne
Przed opracowaniem zadań usługi Stream Analytics przy użyciu edytora bez kodu upewnij się, że spełniasz następujące wymagania:
- Źródła danych wejściowych przesyłania strumieniowego i zasoby docelowe zadania Stream Analytics muszą być publicznie dostępne i nie mogą znajdować się w sieci wirtualnej Azure.
- Aby uzyskać dostęp do zasobów wejściowych i wyjściowych przesyłania strumieniowego, musisz mieć wymagane uprawnienia.
- Musisz zachować uprawnienia do tworzenia i modyfikowania zasobów usługi Azure Stream Analytics.
Uwaga
Edytor bez kodu nie jest obecnie dostępny w regionie Chin.
Zadanie usługi Azure Stream Analytics
Zadanie usługi Stream Analytics opiera się na trzech głównych składnikach: danych wejściowych przesyłania strumieniowego, przekształceń i danych wyjściowych. Można dołączyć dowolną liczbę składników, takich jak wiele danych wejściowych, równoległych gałęzi z wieloma przekształceniami i wiele danych wyjściowych. Aby uzyskać więcej informacji, zobacz dokumentację usługi Azure Stream Analytics.
Uwaga
Następujące funkcje i typy danych wyjściowych nie są dostępne w przypadku korzystania z edytora bez kodu:
- Funkcje zdefiniowane przez użytkownika.
- Edytowanie zapytań na stronie zapytania Azure Stream Analytics. Można jednak wyświetlić zapytanie wygenerowane przez edytor bez kodu na stronie zapytania.
- Dodawanie danych wejściowych i wyjściowych na stronach wejściowych i wyjściowych Azure Stream Analytics. Można jednak wyświetlić dane wejściowe i wyjściowe wygenerowane przez edytor bez kodu na stronie wejściowej i wyjściowej.
- Następujące typy danych wyjściowych nie są dostępne: Azure Function, Azure Data Lake Storage Gen1, PostgreSQL DB, Service Bus queue/topic, Table Storage.
Aby uzyskać dostęp do edytora no-code do tworzenia zadania usługi Stream Analytics, użyj jednego z następujących metod:
Za pośrednictwem portalu usługi Azure Stream Analytics (wersja zapoznawcza): Utwórz zadanie usługi Stream Analytics, a następnie wybierz Edytor no-code na karcie Wprowadzenie na stronie Przegląd, lub wybierz Edytor no-code w panelu po lewej stronie.
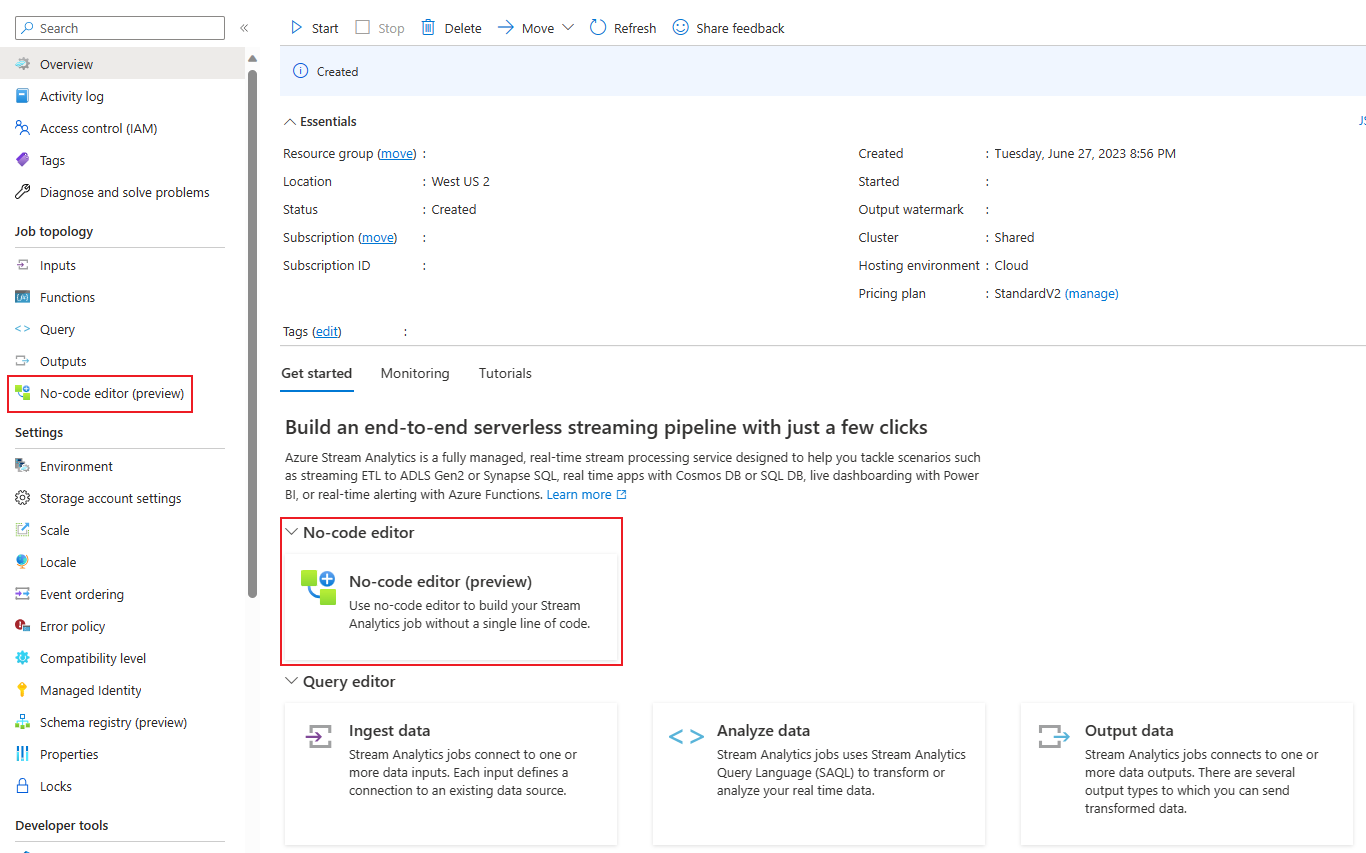
Za pośrednictwem portalu Azure Event Hubs: Otwórz instancję Event Hubs. Wybierz pozycję Przetwarzanie danych, a następnie wybierz dowolny wstępnie zdefiniowany szablon.
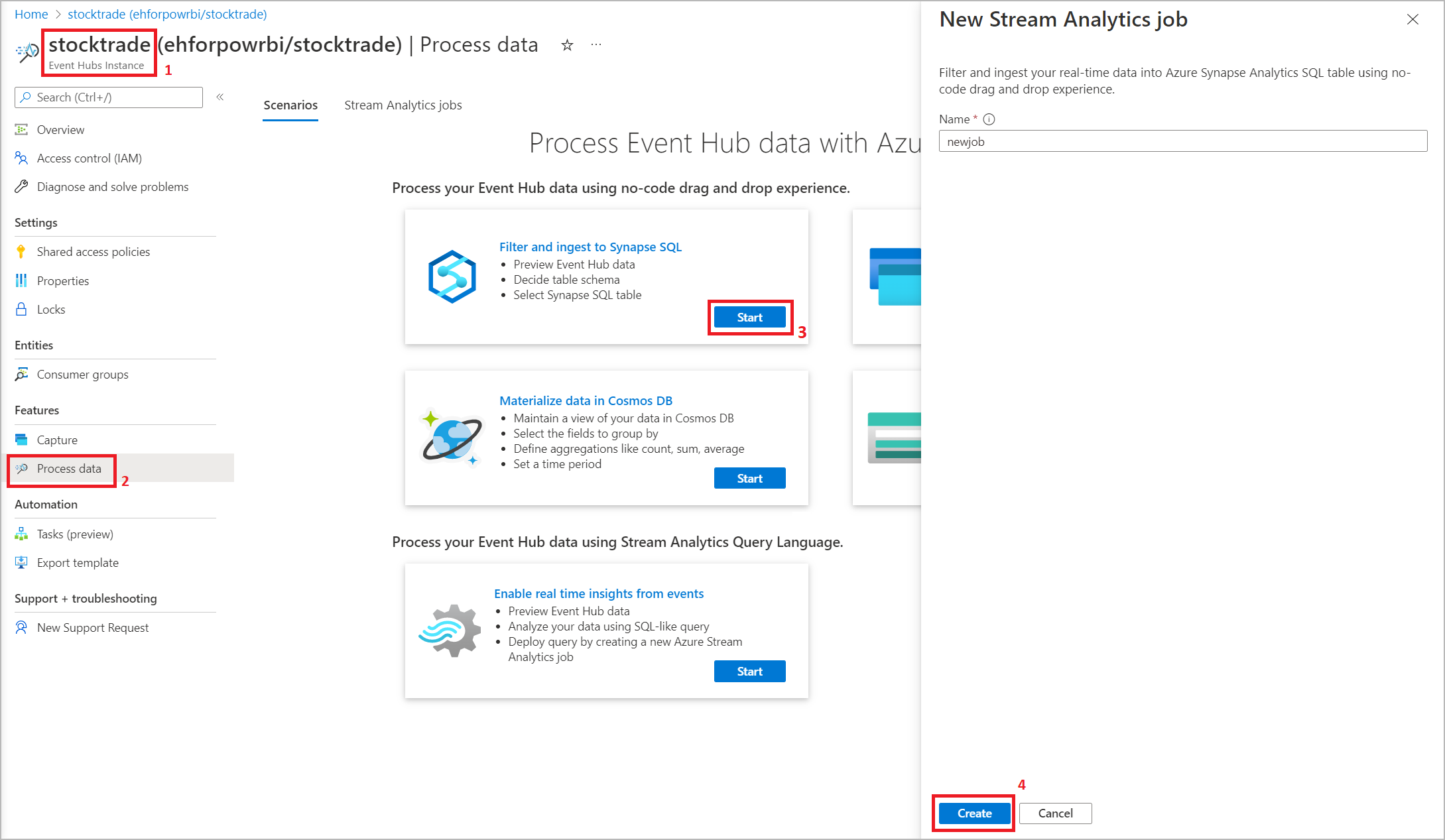
Wstępnie zdefiniowane szablony mogą pomóc w opracowaniu i uruchomieniu zadania w celu rozwiązania różnych scenariuszy, w tym:
- Przechwytywanie danych z usługi Event Hubs w formacie Delta Lake (w wersji zapoznawczej)
- Filtrowanie i wczytywanie do Azure Synapse SQL
- Przechwytywanie danych usługi Event Hubs w formacie Parquet w usłudze Azure Data Lake Storage Gen2
- Materializowanie danych w usłudze Azure Cosmos DB
- Filtrowanie i pozyskiwanie do usługi Azure Data Lake Storage Gen2
- Wzbogacanie danych i wprowadzanie do Event Hub
- Przekształcanie i przechowywanie danych w bazie danych Azure SQL Database
- Filtrowanie i pozyskiwanie do usługi Azure Data Explorer


Poniższy zrzut ekranu przedstawia ukończone zadanie usługi Stream Analytics. Wyróżnia wszystkie sekcje dostępne dla ciebie podczas tworzenia.

- Wstążka: Na wstążce sekcje są uporządkowane zgodnie z klasycznym procesem analitycznym: koncentrator zdarzeń jako dane wejściowe (znany również jako źródło danych), przekształcenia (strumieniowe operacje wyodrębniania, przekształcania i ładowania), dane wyjściowe, przycisk do zapisywania postępu i przycisk do uruchamiania zadania.
- Widok diagramu: ten widok jest graficzną reprezentacją zadania usługi Stream Analytics — od danych wejściowych do operacji po dane wyjściowe.
- Okienko boczne: w zależności od wybranego składnika w widoku diagramu są wyświetlane ustawienia modyfikowania danych wejściowych, transformacji lub danych wyjściowych.
- Karty podglądu danych, błędy autorskie, dzienniki wykonania i metryki: dla każdego kafelka podgląd danych wyświetla wyniki dla tego kroku (na żywo w przypadku danych wejściowych; na żądanie dla przekształceń i danych wyjściowych). Ta sekcja zawiera również podsumowanie błędów tworzenia lub ostrzeżeń, które mogą występować w zadaniu podczas jego opracowywania. Wybranie każdego błędu lub ostrzeżenia wybierze tę transformację. Udostępnia również metryki zadań do monitorowania kondycji uruchomionego zadania.
Przesyłanie strumieniowe danych wejściowych
Edytor bez kodu obsługuje przesyłanie strumieniowe danych wejściowych z trzech typów zasobów:
- Azure Event Hubs
- Azure IoT Hub
- Azure Data Lake Storage Gen2
Aby uzyskać więcej informacji na temat danych wejściowych przesyłania strumieniowego, zobacz Stream data as input into Stream Analytics (Przesyłanie strumieniowe danych jako dane wejściowe do usługi Stream Analytics).
Uwaga
Edytor bez kodu w portalu usługi Azure Event Hubs ma Event Hub tylko jako opcja wejściowa.

Usługa Azure Event Hubs jako dane wejściowe przesyłania strumieniowego
Azure Event Hubs to platforma przesyłania strumieniowego danych big data i usługa pozyskiwania zdarzeń. Może odbierać i przetwarzać miliony zdarzeń na sekundę. Dane wysyłane do centrum zdarzeń można przekształcać i przechowywać za pośrednictwem dowolnego dostawcy analityki w czasie rzeczywistym lub adaptera do przetwarzania wsadowego i magazynowania.
Aby skonfigurować centrum zdarzeń jako dane wejściowe dla zadania, wybierz ikonę Centrum zdarzeń. Kafelek jest widoczny w widoku diagramu, z bocznym panelem do jego konfiguracji i połączenia.
Po nawiązaniu połączenia z centrum zdarzeń w edytorze bez kodu utwórz nową grupę odbiorców (która jest opcją domyślną). Takie podejście pomaga zapobiec osiągnięciu limitu współbieżnych odbiorców przez centrum zdarzeń. Aby dowiedzieć się więcej o grupach odbiorców i o tym, czy należy wybrać istniejącą grupę odbiorców, czy utworzyć nową, zobacz Grupy odbiorców.
Jeśli centrum zdarzeń znajduje się w warstwie Podstawowa, możesz korzystać wyłącznie z istniejącej grupy odbiorców $Default. Jeśli twój Event Hub znajduje się w warstwie standardowej lub premium, możesz utworzyć nową grupę odbiorców.
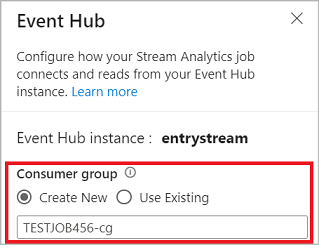
Podczas łączenia się z centrum zdarzeń, jeśli wybierzesz Zarządzaną tożsamość jako tryb uwierzytelniania, rola właściciela danych Azure Event Hubs jest przypisywana zarządzanej tożsamości dla zadania Stream Analytics. Aby dowiedzieć się więcej o tożsamościach zarządzanych dla centrum zdarzeń, zobacz Używanie tożsamości zarządzanych do uzyskiwania dostępu do centrum zdarzeń z poziomu zadania usługi Azure Stream Analytics.
Tożsamości zarządzane eliminują ograniczenia metod uwierzytelniania opartych na użytkownikach. Ograniczenia te obejmują konieczność ponownego uwierzytelnienia ze względu na zmiany hasła lub wygaśnięcie tokenu użytkownika, które występują co 90 dni.
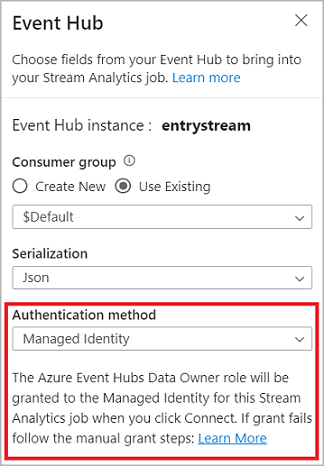
Po skonfigurowaniu szczegółów centrum zdarzeń i wybraniu pozycji Połącz możesz ręcznie dodać pola przy użyciu pozycji + Dodaj pole , jeśli znasz nazwy pól. Aby zamiast tego automatycznie wykrywać pola i typy danych na podstawie próbki przychodzących komunikatów, wybierz pozycję Pola autowykrywania. Wybranie ikony koła zębatego umożliwia edytowanie poświadczeń, jeśli jest to konieczne.
Gdy zadania usługi Stream Analytics wykryją pola, będą one widoczne na liście. Widzisz również podgląd na żywo komunikatów przychodzących w tabeli Podgląd danych pod widokiem diagramu.
Modyfikowanie danych wejściowych
Możesz edytować nazwy pól, usuwać pola, zmieniać typ danych lub zmieniać czas zdarzenia (Oznacz jako czas zdarzenia: klauzula TIMESTAMP BY, jeśli jest to pole typu data/godzina) przez wybranie symbolu z trzema kropkami obok każdego pola. Możesz również rozwinąć, wybrać i edytować wszystkie zagnieżdżone pola z przychodzących komunikatów, jak pokazano na poniższej ilustracji.
Wskazówka
Ten proces dotyczy również danych wejściowych z Azure IoT Hub i Azure Data Lake Storage Gen2.

Dostępne typy danych to:
- Data/godzina: pole Daty i godziny w formacie ISO.
- Liczba zmiennoprzecinkowa: liczba dziesiętna.
- Int: liczba całkowita.
- Rekord: zagnieżdżony obiekt z wieloma rekordami.
- Ciąg: tekst.
Usługa Azure IoT Hub jako wejście przesyłania strumieniowego
Azure IoT Hub to zarządzana usługa hostowana w chmurze, która działa jako centralne centrum komunikatów do komunikacji między aplikacją IoT a dołączonymi urządzeniami. Możesz użyć danych urządzenia IoT wysyłanych do centrum IoT jako danych wejściowych dla zadania usługi Stream Analytics.
Uwaga
Możesz użyć wejścia Azure IoT Hub w edytorze niewymagającym kodowania na portalu Azure Stream Analytics.
Aby dodać IoT Hub jako wejście do przesyłania strumieniowego dla zadania, wybierz IoT Hub z sekcji Dane wejściowe na wstążce. Następnie wypełnij potrzebne informacje w panelu po prawej stronie, aby połączyć IoT Hub z Twoim zadaniem. Aby dowiedzieć się więcej na temat szczegółów każdego pola, zobacz Stream data from IoT Hub to Stream Analytics job (Przesyłanie strumieniowe danych z usługi IoT Hub do zadania usługi Stream Analytics).

Usługa Azure Data Lake Storage Gen2 jako dane wejściowe do przesyłania strumieniowego
Azure Data Lake Storage Gen2 (ADLS Gen2) to oparte na chmurze rozwiązanie typu data lake przedsiębiorstwa. Jest ona przeznaczona do przechowywania ogromnych ilości danych w dowolnym formacie i ułatwiania obciążeń analitycznych danych big data. Usługa Stream Analytics może przetwarzać dane przechowywane w usłudze ADLS Gen2 jako strumień danych. Aby dowiedzieć się więcej na temat tego typu danych wejściowych, zobacz Przesyłanie danych strumieniowych z ADLS Gen2 do zadania Stream Analytics.
Uwaga
Możesz użyć danych wejściowych z Azure Data Lake Storage Gen2 w edytorze wizualnym (bez kodowania) w portalu Azure Stream Analytics.
Aby dodać ADLS Gen2 jako strumieniowe dane wejściowe do zadania, wybierz ADLS Gen2 z Dane wejściowe na pasku narzędzi. Następnie wypełnij wymagane informacje na panelu po prawej stronie, aby połączyć usługę ADLS Gen2 z zadaniem. Aby dowiedzieć się więcej o szczegółach każdego pola, zobacz Stream data from ADLS Gen2 to Stream Analytics job (Przesyłanie strumieniowe danych z usługi ADLS Gen2 do zadania usługi Stream Analytics).

Wejścia danych referencyjnych
Dane referencyjne są statyczne lub zmieniają się powoli w czasie. Zazwyczaj używasz go do wzbogacania strumieni przychodzących i wykonywania wyszukiwań w swoim zadaniu. Możesz na przykład połączyć dane wejściowe strumienia danych z danymi referencyjnymi, podobnie jak łączenie SQL, aby wyszukać wartości statyczne. Aby uzyskać więcej informacji na temat referencyjnych danych wejściowych, zobacz Use reference data for lookups in Stream Analytics (Używanie danych referencyjnych do wyszukiwania w usłudze Stream Analytics).
Edytor bez kodu obsługuje teraz dwa źródła danych referencyjnych:
- Azure Data Lake Storage Gen2
- Azure SQL Database

Usługa Azure Data Lake Storage Gen2 jako dane referencyjne
Dane referencyjne modelu są przedstawiane jako sekwencja obiektów blob w porządku rosnącym, zgodnie z kombinacją daty i czasu określoną w nazwie blobu. Obiekty blob można dodawać do końca sekwencji tylko wtedy, gdy ich data i godzina są późniejsze niż data i godzina ostatniego obiektu blob określonego w sekwencji. Zdefiniuj obiekty blob w konfiguracji wejściowej.
Najpierw w sekcji Dane wejściowe na wstążce wybierz Referencję ADLS Gen2. Aby wyświetlić szczegółowe informacje o poszczególnych polach, zobacz sekcję dotyczącą usługi Azure Blob Storage w temacie Używanie danych referencyjnych do wyszukiwania w usłudze Stream Analytics.
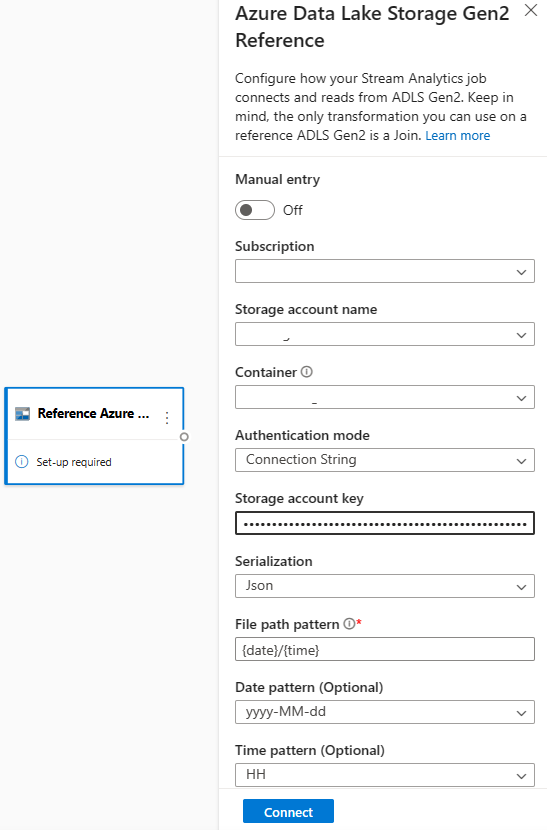
Następnie przekaż plik tablicy JSON. System wykrywa pola. Użyj tych danych referencyjnych do wykonania transformacji strumieniowych danych wejściowych z usługi Event Hubs.

Usługa Azure SQL Database jako dane referencyjne
Usługę Azure SQL Database można używać jako danych referencyjnych dla zadania usługi Stream Analytics w edytorze bez kodu. Aby uzyskać więcej informacji, zobacz sekcję dotyczącą usługi SQL Database w temacie Use reference data for lookups in Stream Analytics (Używanie danych referencyjnych do wyszukiwania w usłudze Stream Analytics).
Aby skonfigurować bazę danych SQL jako referencyjne dane wejściowe, wybierz pozycję Reference SQL Database w sekcji Dane wejściowe na wstążce. Następnie wypełnij informacje, aby połączyć bazę danych referencyjnych i wybrać tabelę z potrzebnymi kolumnami. Możesz również pobrać dane referencyjne z tabeli, edytując zapytanie SQL ręcznie.

Przekształcenia
Przekształcenia danych przesyłanych strumieniowo różnią się z natury od przekształceń danych wsadowych. Prawie wszystkie dane przesyłane strumieniowo mają składnik czasu, który ma wpływ na wszystkie zadania związane z przygotowywaniem danych.
Aby dodać przekształcenie danych przesyłanych strumieniowo do zadania, wybierz symbol przekształcenia w sekcji Operacje na wstążce dla tej transformacji. Odpowiedni kafelek zostanie dodany do widoku diagramu. Po jej wybraniu zostanie wyświetlone okienko boczne dla tego przekształcenia w celu jej skonfigurowania.

Filtr
Użyj przekształcenia filtru, aby filtrować zdarzenia na podstawie wartości pola w danych wejściowych. W zależności od typu danych (liczby lub tekstu) przekształcenie zachowuje wartości zgodne z wybranym warunkiem.

Uwaga
Wewnątrz każdego kafelka są wyświetlane informacje o tym, czego jeszcze potrzeba, aby transformacja była gotowa. Na przykład po dodaniu nowego kafelka zostanie wyświetlony komunikat Wymagana konfiguracja. Jeśli brakuje łącznika węzła, zostanie wyświetlony komunikat o błędzie lub komunikat Ostrzeżenie .
Zarządzanie polami
Przekształcenie Zarządzaj polami umożliwia dodawanie, usuwanie lub zmienianie nazw pól przychodzących z danych wejściowych lub innego przekształcenia. Ustawienia w okienku bocznym umożliwiają dodawanie nowego pola, wybierając pozycję Dodaj pole lub dodając wszystkie pola jednocześnie.

Możesz również dodać nowe pole przy użyciu wbudowanych funkcji, aby agregować dane z nadrzędnego strumienia. Obecnie obsługiwane funkcje wbudowane to niektóre funkcje funkcji ciągów, funkcji daty i godziny oraz funkcji matematycznych. Aby dowiedzieć się więcej na temat definicji tych funkcji, zobacz Wbudowane funkcje (Azure Stream Analytics).

Wskazówka
Po skonfigurowaniu kafelka widok diagramu daje wgląd w ustawienia w obrębie kafelka. Na przykład w obszarze Zarządzaj polami powyższego obrazu można zobaczyć pierwsze trzy pola zarządzane i nowe nazwy przypisane do nich. Każdy kafelek zawiera odpowiednie informacje.
Agregacja
Użyj przekształcenia Agregacja, aby obliczyć agregację (Suma, Minimum, Maksimum lub Średnia) za każdym razem, gdy nowe zdarzenie występuje w danym okresie. Ta operacja umożliwia również filtrowanie lub podział agregacji na podstawie innych wymiarów danych. W tej samej transformacji można uwzględnić co najmniej jedną agregację.
Aby dodać agregację, wybierz symbol przekształcenia. Następnie połącz dane wejściowe, wybierz agregację, dodaj dowolny wymiar filtru lub wycinka i wybierz okres czasu, w którym jest obliczana agregacja. W tym przykładzie liczysz sumę wartości opłaty według stanu, z którego pochodzi pojazd, w ciągu ostatnich 10 sekund.

Aby dodać kolejną agregację do tej samej transformacji, wybierz pozycję Dodaj funkcję agregacji. Filtr lub wycinek ma zastosowanie do wszystkich agregacji w transformacji.
Dołączanie
Użyj przekształcenia Join, aby połączyć zdarzenia z dwóch danych wejściowych na podstawie wybranych par pól. Jeśli nie wybierzesz pary pól, połączenie jest domyślnie oparte na czasie. Wartością domyślną jest to, co sprawia, że ta transformacja różni się od tej wsadowej.
Podobnie jak w przypadku zwykłych sprzężeń, masz opcje logiki sprzężenia:
- Złączenie wewnętrzne: dołącz tylko rekordy z obu tabel, gdzie pary są zgodne. W tym przykładzie tablica rejestracyjna pasuje do obu danych wejściowych.
- Zewnętrzne sprzężenie lewostronne: uwzględnij wszystkie rekordy z lewej (czyli pierwszej) tabeli i tylko rekordy z drugiej, pasujące do pary pól. Jeśli nie ma dopasowania, pola z drugiego wejścia są puste.
Aby wybrać typ sprzężenia, wybierz symbol preferowanego typu w okienku bocznym.
Na koniec wybierz okres, na który chcesz obliczyć łączenie. W tym przykładzie łączenie uwzględnia ostatnie 10 sekund. Tym dłuższy jest okres, tym rzadziej są używane dane wyjściowe, a tym więcej zasobów przetwarzania używanych do transformacji.
Domyślnie dane wyjściowe zawierają wszystkie pola z obu tabel. Prefiksy po lewej (pierwszy węzeł) i prawe (drugi węzeł) ułatwiają odróżnienie źródła.

Grupuj według
Aby obliczyć agregacje we wszystkich zdarzeniach w określonym przedziale czasu, użyj przekształcenia pełniącego funkcję Grupuj według. Można grupować według wartości w co najmniej jednym polu. Jest podobna do przekształcenia Aggregate, ale oferuje więcej opcji agregacji. Zawiera również bardziej złożone opcje okien czasowych. Podobnie jak agregacja, można dodać więcej niż jedną agregację na transformację.
Agregacje dostępne w transformacji to:
- Średnia
- Licznik
- Maksimum
- Minimum
- Percentyl (ciągły i dyskretny)
- Odchylenie standardowe
- Sum
- Wariancja
Aby skonfigurować transformację:
- Wybierz preferowaną agregację.
- Wybierz pole, na którym chcesz zagregować.
- Wybierz opcjonalne pole do grupowania, jeśli chcesz uzyskać obliczenie agregacyjne dla innego wymiaru lub kategorii. Na przykład: Stan.
- Wybierz swoją funkcję dla okien czasowych.
Aby dodać kolejną agregację do tej samej transformacji, wybierz pozycję Dodaj funkcję agregacji. Należy pamiętać, że pole Grupuj według i funkcja okna mają zastosowanie do wszystkich agregacji w transformacji.

Sygnatura czasowa końca okna czasowego jest wyświetlana jako część danych wyjściowych transformacji do celów referencyjnych. Aby uzyskać więcej informacji na temat okien czasowych, które obsługują zadania usługi Stream Analytics, zobacz Funkcje obsługi okien (Azure Stream Analytics).
Unia
Użyj przekształcenia Union aby połączyć co najmniej dwa dane wejściowe. Dodaj zdarzenia, które mają wspólne pola (o nazwach i typach danych takich samych) do jednej tabeli. Dane wyjściowe wyklucza pola, które nie są zgodne.
Rozwiń tablicę
Użyj przekształcenia Rozwiń tablicę, aby utworzyć nowy wiersz dla każdej wartości w tablicy.

Dane wyjściowe przesyłania strumieniowego
Środowisko przeciągania i upuszczania bez kodu obsługuje obecnie kilka ujściów danych wyjściowych do przechowywania przetworzonych danych w czasie rzeczywistym.

Azure Data Lake Storage Gen2
Usługa Data Lake Storage Gen2 sprawia, że usługa Azure Storage stanowi podstawę do tworzenia magazynów danych przedsiębiorstwa na platformie Azure. Jest ona przeznaczona do obsługi wielu petabajtów informacji przy jednoczesnym utrzymaniu setek gigabitów przepływności. Umożliwia łatwe zarządzanie ogromnymi ilościami danych. Usługa Azure Blob Storage oferuje ekonomiczne i skalowalne rozwiązanie do przechowywania dużych ilości danych bez struktury w chmurze.
W sekcji Dane wyjściowe na wstążce wybierz pozycję ADLS Gen2 jako dane wyjściowe zadania usługi Stream Analytics. Następnie wybierz kontener, w którym chcesz wysłać dane wyjściowe zadania. Aby uzyskać więcej informacji na temat danych wyjściowych usługi Azure Data Lake Gen2 dla zadania usługi Stream Analytics, zobacz Dane wyjściowe usługi Blob Storage i Azure Data Lake Gen2 z usługi Azure Stream Analytics.
Jeśli łączysz się z Azure Data Lake Storage Gen2 i wybierzesz opcję Managed Identity jako tryb uwierzytelniania, rola Współautor danych obiektu blob usługi Storage zostanie przyznana Managed Identity do zadania Stream Analytics. Aby dowiedzieć się więcej o tożsamościach zarządzanych dla usługi Azure Data Lake Storage Gen2, zobacz Używanie tożsamości zarządzanych do uwierzytelniania zadania usługi Azure Stream Analytics w usłudze Azure Blob Storage.
Tożsamości zarządzane eliminują ograniczenia metod uwierzytelniania opartych na użytkownikach. Ograniczenia te obejmują konieczność ponownego uwierzytelnienia ze względu na zmiany hasła lub wygaśnięcie tokenu użytkownika, które występują co 90 dni.
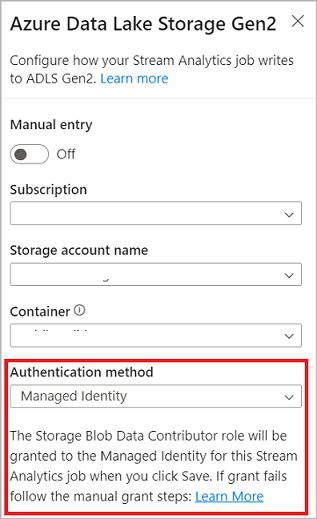
Dostarczenie dokładnie raz (wersja zapoznawcza) jest obsługiwane w usłudze ADLS Gen2 jako dane wyjściowe bez edytora kodu. Można ją włączyć w sekcji Tryb zapisu w konfiguracji usługi ADLS Gen2. Aby uzyskać więcej informacji na temat tej funkcji, zobacz Dokładne jednokrotne dostarczenie (wersja próbna) w usłudze Azure Data Lake Gen2.

Zapisywanie w tabeli Delta Lake (wersja wstępna) jest obsługiwane w usłudze ADLS Gen2 jako wyjście edytora bez kodu. Dostęp do tej opcji można uzyskać w sekcji Serializacja w konfiguracji usługi ADLS Gen2. Aby uzyskać więcej informacji na temat tej funkcjonalności, zobacz Zapisywanie do tabeli Delta Lake.

Azure Synapse Analytics
Zadania usługi Azure Stream Analytics mogą wysyłać dane wyjściowe do dedykowanej tabeli puli SQL w usłudze Azure Synapse Analytics i przetwarzać współczynniki przepływności do 200 MB na sekundę. Usługa Stream Analytics obsługuje najbardziej wymagające analizy w czasie rzeczywistym i potrzeby przetwarzania danych ścieżki gorącej dla obciążeń, takich jak raportowanie i pulpity nawigacyjne.
Ważne
Dedykowana tabela puli SQL musi istnieć przed dodaniem jej jako danych wyjściowych do zadania usługi Stream Analytics. Schemat tabeli musi być zgodny z polami i ich typami w danych wyjściowych zadania.
W sekcji Dane wyjściowe na wstążce wybierz pozycję Synapse jako dane wyjściowe zadania usługi Stream Analytics. Następnie wybierz tabelę puli SQL, w której chcesz wysłać dane wyjściowe zadania. Aby uzyskać więcej informacji na temat danych wyjściowych usługi Azure Synapse dla zadania usługi Stream Analytics, zobacz Dane wyjściowe usługi Azure Synapse Analytics z usługi Azure Stream Analytics.
Azure Cosmos DB
Azure Cosmos DB to globalnie rozproszona usługa bazy danych, która oferuje nieograniczoną elastyczną skalę na całym świecie. Oferuje ona również zaawansowane zapytania i automatyczne indeksowanie za pośrednictwem modeli danych niezależnych od schematu.
W sekcji Dane wyjściowe na wstążce wybierz pozycję CosmosDB jako dane wyjściowe zadania usługi Stream Analytics. Aby uzyskać więcej informacji na temat danych wyjściowych usługi Azure Cosmos DB dla zadania usługi Stream Analytics, zobacz Dane wyjściowe usługi Azure Cosmos DB z usługi Azure Stream Analytics.
Jeśli nawiążesz połączenie z Azure Cosmos DB i wybierzesz Managed Identity jako tryb uwierzytelniania, rola Współtwórcy zostanie przydzielona dla tożsamości zarządzanej w zadaniu usługi Stream Analytics. Aby dowiedzieć się więcej o tożsamościach zarządzanych dla usługi Azure Cosmos DB, zobacz Używanie tożsamości zarządzanych do uzyskiwania dostępu do usługi Azure Cosmos DB z zadania usługi Azure Stream Analytics (wersja zapoznawcza).
Dane wyjściowe Azure Cosmos DB w edytorze bez kodu obsługują również metodę uwierzytelniania tożsamości zarządzanych. Ta metoda zapewnia takie same korzyści jak w danych wyjściowych usługi ADLS Gen2.
Azure SQL Database
Azure SQL Database to w pełni zarządzany silnik bazodanowy platformy jako usługi (PaaS), który ułatwia tworzenie warstwy przechowywania danych o wysokiej dostępności i wydajności dla aplikacji i rozwiązań w Azure. Za pomocą edytora bez kodu można skonfigurować zadania usługi Azure Stream Analytics, aby zapisywać przetworzone dane w istniejącej tabeli w usłudze SQL Database.
Aby skonfigurować usługę Azure SQL Database jako dane wyjściowe, wybierz pozycję SQL Database w sekcji Dane wyjściowe na wstążce. Następnie wprowadź informacje potrzebne do nawiązania połączenia z bazą danych SQL i wybierz tabelę, do której chcesz zapisać dane.
Ważne
Tabela usługi Azure SQL Database musi istnieć przed dodaniem jej jako danych wyjściowych do zadania usługi Stream Analytics. Schemat tabeli musi być zgodny z polami i ich typami w danych wyjściowych zadania.
Aby uzyskać więcej informacji na temat danych wyjściowych usługi Azure SQL Database dla zadania usługi Stream Analytics, zobacz Dane wyjściowe usługi Azure SQL Database z usługi Azure Stream Analytics.
Centra zdarzeń
W przypadku danych w czasie rzeczywistym przychodzących do usługi ASA edytor bez kodu może przekształcać i wzbogacać dane, a następnie wysyłać dane do innego centrum zdarzeń. Możesz wybrać wyjście Event Hubs podczas konfigurowania zadania usługi Azure Stream Analytics.
Aby skonfigurować Event Hubs jako dane wyjściowe, wybierz pozycję Event Hub w sekcji Dane wyjściowe na wstążce. Następnie wprowadź informacje potrzebne do nawiązania połączenia z centrum zdarzeń, do którego chcesz zapisać dane.
Aby uzyskać więcej informacji na temat danych wyjściowych usługi Event Hubs dla zadania usługi Stream Analytics, zobacz Dane wyjściowe usługi Event Hubs z usługi Azure Stream Analytics.
Azure Data Explorer
Azure Data Explorer to w pełni zarządzana, wysokiej wydajności platforma analizy danych big data, która ułatwia analizowanie dużych ilości danych. Możesz również użyć Azure Data Explorer jako danych wyjściowych zadania Azure Stream Analytics za pomocą edytora bez kodu.
Aby skonfigurować Azure Data Explorer jako dane wyjściowe, wybierz sekcję Azure Data Explorer w obszarze Outputs na wstążce. Następnie wprowadź wymagane informacje, aby nawiązać połączenie z bazą danych Azure Data Explorer i określ tabelę, do której chcesz zapisywać dane.
Ważne
Tabela musi istnieć w wybranej bazie danych, a schemat tabeli musi dokładnie odpowiadać polam i ich typom w danych wyjściowych zadania.
Aby uzyskać więcej informacji na temat danych wyjściowych usługi Azure Data Explorer dla zadania usługi Stream Analytics, zobacz Dane wyjściowe usługi Azure Data Explorer z usługi Azure Stream Analytics (wersja zapoznawcza).
Power BI
Usługa Power BI oferuje kompleksowe środowisko wizualizacji dla wyniku analizy danych. Korzystając z wyjściowych danych Power BI w usłudze Stream Analytics, przetworzone dane przesyłane strumieniowo są zapisywane w zestawie danych przesyłania strumieniowego Power BI, a następnie zestaw ten można wykorzystać do utworzenia pulpitu nawigacyjnego w Power BI niemal w czasie rzeczywistym.
Aby skonfigurować Power BI jako dane wyjściowe, wybierz sekcję Power BI w obszarze Outputs na wstążce. Następnie wprowadź wymagane informacje, aby połączyć się z obszarem roboczym Power BI i podać nazwy zestawu danych przesyłania strumieniowego i tabeli, do której chcesz zapisać dane. Aby dowiedzieć się więcej na temat szczegółów każdego pola, zobacz Dane wyjściowe usługi Power BI z usługi Azure Stream Analytics.
Podgląd danych, błędy tworzenia, dzienniki środowiska uruchomieniowego i metryki
Doświadczenie przeciągania i upuszczania bez kodu udostępnia narzędzia ułatwiające tworzenie, rozwiązywanie problemów i ocenę wydajności potoku analizy danych przesyłanych strumieniowo.
Podgląd danych w czasie rzeczywistym dla danych wejściowych
Po nawiązaniu połączenia ze źródłem danych wejściowych, takim jak centrum zdarzeń, i wybraniu jego kafelka w widoku diagramu (karta Podgląd danych ), zobaczysz podgląd danych przychodzących na żywo, jeśli spełnione są wszystkie następujące warunki:
- Dane są przesyłane.
- Dane wejściowe są poprawnie skonfigurowane.
- Pola są dodawane.
Jak pokazano na poniższym zrzucie ekranu, jeśli chcesz zobaczyć lub przejść do szczegółów określonego elementu, możesz wstrzymać podgląd (1). Możesz też uruchomić go ponownie, jeśli wszystko będzie gotowe.
Możesz również wyświetlić szczegóły określonego rekordu, komórki w tabeli, wybierając go, a następnie wybierając pozycję Pokaż/Ukryj szczegóły (2). Zrzut ekranu przedstawia szczegółowy widok zagnieżdżonego obiektu w rekordzie.

Statyczny podgląd przekształceń i danych wyjściowych
Po dodaniu i skonfigurowaniu jakichkolwiek kroków w widoku diagramu możesz przetestować ich zachowanie, wybierając pozycję Pobierz statyczny podgląd.

Po wybraniu przycisku zadanie usługi Stream Analytics ocenia wszystkie przekształcenia i dane wyjściowe, aby upewnić się, że zostały prawidłowo skonfigurowane. Następnie usługa Stream Analytics wyświetla wyniki w podglądzie danych statycznych, jak pokazano na poniższej ilustracji.

Podgląd można odświeżyć, wybierając pozycję Odśwież statyczną wersję zapoznawcza (1). Po odświeżeniu wersji zapoznawczej zadanie usługi Stream Analytics pobiera nowe dane z danych wejściowych i ocenia wszystkie przekształcenia. Następnie ponownie wysyła dane wyjściowe z aktualizacjami, które mogły zostać wykonane. Dostępna jest również opcja Pokaż/Ukryj szczegóły (2).
Błędy autorskie
Jeśli masz jakiekolwiek błędy tworzenia lub ostrzeżenia, na karcie Błędy tworzenia jest wyświetlana lista, jak pokazano na poniższym zrzucie ekranu. Lista zawiera szczegółowe informacje o błędzie lub ostrzeżeniu, typ karty (dane wejściowe, transformacja lub dane wyjściowe), poziom błędu oraz opis błędu lub ostrzeżenia.

Dzienniki środowiska uruchomieniowego
Dzienniki środowiska uruchomieniowego są wyświetlane na poziomie ostrzeżenia, błędu lub informacji, gdy zadanie jest uruchomione. Te dzienniki są przydatne, gdy chcesz edytować topologię lub konfigurację zadania usługi Stream Analytics na potrzeby rozwiązywania problemów. Włącz dzienniki diagnostyczne i wyślij je do obszaru roboczego Log Analytics w Settings, aby uzyskać więcej szczegółowych informacji na temat uruchomionych zadań do debugowania.

Na poniższym zrzucie ekranu użytkownik konfiguruje dane wyjściowe usługi SQL Database ze schematem tabeli, który nie jest zgodny z polami danych wyjściowych zadania.

Metryki
Jeśli zadanie jest uruchomione, możesz monitorować kondycję zadania na karcie Metryki. Cztery wyświetlane domyślnie metryki to Opóźnienie znaku wodnego, Zdarzenia wejściowe, Zaległe zdarzenia wejściowe i Zdarzenia wyjściowe. Użyj tych metryk, aby dowiedzieć się, czy zdarzenia przepływają do i z zadania bez żadnych zaległości w przetwarzaniu danych wejściowych.

Możesz wybrać więcej metryk z listy. Aby szczegółowo zrozumieć wszystkie metryki, zobacz Metryki zadań usługi Azure Stream Analytics.
Rozpocznij zadanie usługi Stream Analytics
Zadanie można zapisać w dowolnym momencie podczas jego tworzenia. Po skonfigurowaniu danych wejściowych przesyłania strumieniowego, przekształceń i danych wyjściowych przesyłania strumieniowego dla zadania można uruchomić zadanie.
Uwaga
Mimo że edytor bez kodu w portalu usługi Azure Stream Analytics jest w wersji zapoznawczej, usługa Azure Stream Analytics jest ogólnie dostępna.

Możesz skonfigurować następujące opcje:
-
Czas rozpoczęcia: Po uruchomieniu zadania wybierz czas, kiedy powinno zacząć się tworzenie danych wyjściowych.
- Teraz: ta opcja sprawia, że punkt początkowy strumienia zdarzeń wyjściowych jest taki sam jak podczas uruchamiania zadania.
- Niestandardowy: wybierz punkt początkowy danych wyjściowych.
- Gdy zostało ostatnio zatrzymane: Ta opcja jest dostępna, gdy zadanie zostało wcześniej uruchomione, ale zostało zatrzymane ręcznie lub nie powiodło się. Po wybraniu tej opcji ostatni czas wyjściowy jest używany do ponownego uruchomienia zadania, więc żadne dane nie zostaną utracone.
- Jednostki przesyłania strumieniowego: jednostki przesyłania strumieniowego (SU) reprezentują ilość zasobów obliczeniowych i pamięci przydzielonych do zadania podczas jego działania. Jeśli nie masz pewności, ile jednostek SU wybrać, zacznij od trzech i dostosuj ich liczbę zgodnie z potrzebami.
- Obsługa błędów danych wyjściowych: zasady obsługi błędów danych wyjściowych mają zastosowanie tylko wtedy, gdy zdarzenie wyjściowe wygenerowane przez zadanie usługi Stream Analytics nie jest zgodne ze schematem ujścia docelowego. Skonfiguruj politykę, wybierając pozycję Ponów próbę lub Odrzuć. Aby uzyskać więcej informacji, zobacz Polityka błędów danych wyjściowych w Azure Stream Analytics.
- Uruchom: ten przycisk uruchamia zadanie usługi Stream Analytics.

Lista zadań usługi Stream Analytics w portalu usługi Azure Event Hubs
Aby wyświetlić listę wszystkich zadań usługi Stream Analytics utworzonych przy użyciu funkcji przeciągania i upuszczania bez kodu w portalu Azure Event Hubs, wybierz Przetwarzanie danych> zadania usługi Stream Analytics.

Oto elementy karty zadań usługi Stream Analytics :
- Filtr: filtruj listę według nazwy zadania.
- Odśwież: obecnie lista nie odświeża się automatycznie. Użyj przycisku Odśwież, aby odświeżyć listę i wyświetlić najnowszy stan.
- Nazwa zadania: Nazwa w tym obszarze to ta podana w pierwszym kroku tworzenia zadania. Nie można go edytować. Wybierz nazwę zadania, aby otworzyć zadanie w środowisku przeciągania i upuszczania bez kodu, w którym można zatrzymać zadanie, edytować je i uruchomić ponownie.
- Stan: w tym obszarze jest wyświetlany stan zadania. Wybierz pozycję Odśwież na początku listy, aby wyświetlić najnowszy stan.
- Jednostki przesyłania strumieniowego: w tym obszarze jest wyświetlana liczba jednostek przesyłania strumieniowego wybranych podczas uruchamiania zadania.
- Watermark danych wyjściowych: ten obszar zawiera wskaźnik żywotności dla danych tworzonych przez zadanie. Wszystkie zdarzenia przed sygnaturą czasową są już obliczone.
- Monitorowanie zadań: wybierz pozycję Otwórz metryki , aby wyświetlić metryki związane z tym zadaniem usługi Stream Analytics. Aby uzyskać więcej informacji na temat metryk, których można użyć do monitorowania zadania usługi Stream Analytics, zobacz Metryki zadań usługi Azure Stream Analytics.
- Operacje: Uruchamianie, zatrzymywanie lub usuwanie zadania.
Następne kroki
Dowiedz się, jak używać edytora no-code do rozwiązywania typowych scenariuszy przy użyciu wstępnie zdefiniowanych szablonów: