Kopiera data från eller till MongoDB med Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder pipelines för kopieringsaktivitet i Azure Data Factory Synapse Analytics för att kopiera data från och till en MongoDB-databas. Den bygger på översiktsartikeln för kopieringsaktivitet som visar en allmän översikt över kopieringsaktiviteten.
Viktigt
Den nya MongoDB-anslutningsappen ger förbättrat inbyggt MongoDB-stöd. Om du använder den äldre MongoDB-anslutningsappen i din lösning, som endast stöds för bakåtkompatibilitet, kan du läsa artikeln om MongoDB-anslutningsprogram (äldre).
Den här MongoDB-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Kopieringsaktivitet (källa/mottagare) | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor/mottagare finns i tabellen Datalager som stöds.
Mer specifikt stöder den här MongoDB-anslutningsappen versioner upp till 4.2. Om ditt arbete kräver versioner som är nyare än 4.2 bör du överväga att använda MongoDB Atlas med MongoDB Atlas-anslutningsappen, som ger mer omfattande support och funktioner.
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Använd följande steg för att skapa en länkad tjänst till MongoDB i Användargränssnittet för Azure-portalen.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter MongoDB och välj MongoDB-anslutningsappen.
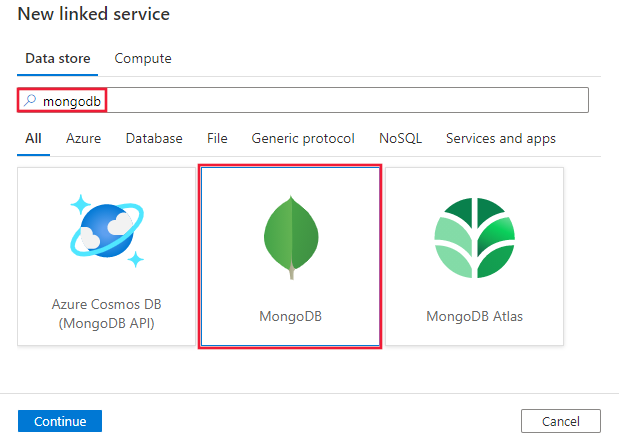
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
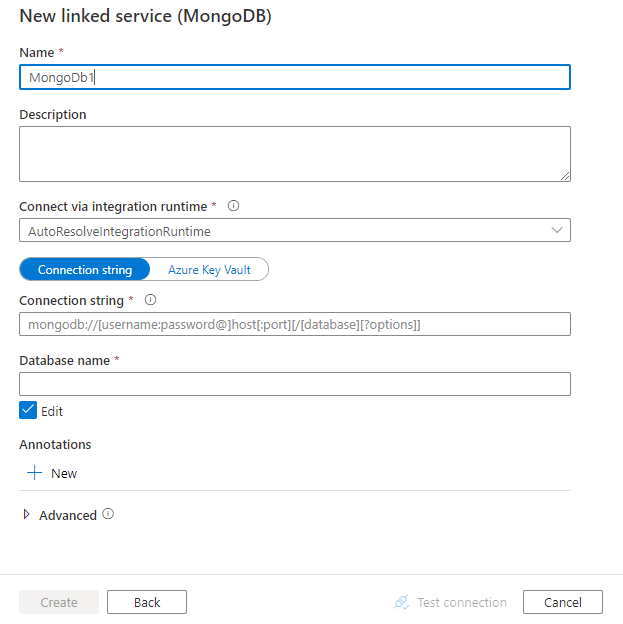
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för MongoDB-anslutningsappen.
Följande egenskaper stöds för den länkade MongoDB-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till: MongoDbV2 | Ja |
| connectionString | Ange MongoDB-niska veze t.ex. mongodb://[username:password@]host[:port][/[database][?options]]. Mer information finns i MongoDB-handbok om niska veze. Du kan också placera en niska veze i Azure Key Vault. Mer information finns i Lagra autentiseringsuppgifter i Azure Key Vault. |
Ja |
| database | Namnet på den databas som du vill komma åt. | Ja |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "MongoDBLinkedService",
"properties": {
"type": "MongoDbV2",
"typeProperties": {
"connectionString": "mongodb://[username:password@]host[:port][/[database][?options]]",
"database": "myDatabase"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i Datauppsättningar och länkade tjänster. Följande egenskaper stöds för MongoDB-datauppsättning:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till: MongoDbV2Collection | Ja |
| collectionName | Namnet på samlingen i MongoDB-databasen. | Ja |
Exempel:
{
"name": "MongoDbDataset",
"properties": {
"type": "MongoDbV2Collection",
"typeProperties": {
"collectionName": "<Collection name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<MongoDB linked service name>",
"type": "LinkedServiceReference"
}
}
}
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av MongoDB-källa och mottagare.
Följande egenskaper stöds i avsnittet kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till: MongoDbV2Source | Ja |
| filter | Anger markeringsfilter med hjälp av frågeoperatorer. Om du vill returnera alla dokument i en samling utelämnar du den här parametern eller skickar ett tomt dokument ({}). | Nej |
| cursorMethods.project | Anger fälten som ska returneras i dokumenten för projektion. Om du vill returnera alla fält i matchande dokument utelämnar du den här parametern. | Nej |
| cursorMethods.sort | Anger i vilken ordning frågan returnerar matchande dokument. Se cursor.sort(). | Nej |
| cursorMethods.limit | Anger det maximala antalet dokument som servern returnerar. Se cursor.limit(). | Nej |
| cursorMethods.skip | Anger antalet dokument som ska hoppa över och varifrån MongoDB börjar returnera resultat. Se cursor.skip(). | Nej |
| batchSize | Anger hur många dokument som ska returneras i varje batch av svaret från MongoDB-instansen. I de flesta fall påverkar det inte användaren eller programmet att ändra batchstorleken. Azure Cosmos DB begränsar varje batch får inte överstiga 40 MB, vilket är summan av batchStorleken för antalet dokument, så minska det här värdet om dokumentstorleken är stor. | Nej (standardvärdet är 100) |
Tips
Tjänsten stöder användning av BSON-dokument i strikt läge. Kontrollera att filterfrågan är i strikt läge i stället för Shell-läge. Mer beskrivning finns i MongoDB-manualen.
Exempel:
"activities":[
{
"name": "CopyFromMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbV2Source",
"filter": "{datetimeData: {$gte: ISODate(\"2018-12-11T00:00:00.000Z\"),$lt: ISODate(\"2018-12-12T00:00:00.000Z\")}, _id: ObjectId(\"5acd7c3d0000000000000000\") }",
"cursorMethods": {
"project": "{ _id : 1, name : 1, age: 1, datetimeData: 1 }",
"sort": "{ age : 1 }",
"skip": 3,
"limit": 3
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Följande egenskaper stöds i avsnittet Kopieringsaktivitetsmottagare:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetsmottagaren måste anges till MongoDbV2Sink. | Ja |
| writeBehavior | Beskriver hur du skriver data till MongoDB. Tillåtna värden: infoga och upsert. Upserts beteende är att ersätta dokumentet om ett dokument med samma _id redan finns. Annars infogar du dokumentet.Obs! Tjänsten genererar automatiskt ett _id för ett dokument om ett _id inte har angetts i det ursprungliga dokumentet eller efter kolumnmappning. Det innebär att du måste se till att ditt dokument har ett ID för att upsert ska fungera som förväntat. |
Nej (standardvärdet är insert) |
| writeBatchSize | Egenskapen writeBatchSize styr storleken på dokument som ska skrivas i varje batch. Du kan prova att öka värdet för writeBatchSize för att förbättra prestanda och minska värdet om dokumentstorleken är stor. | Nej (standardvärdet är 10 000) |
| writeBatchTimeout | Väntetiden för att batchinfogningsåtgärden ska slutföras innan tidsgränsen uppnås. Det tillåtna värdet är tidsintervall. | Nej (standardvärdet är 00:30:00 –30 minuter) |
Tips
Om du vill importera JSON-dokument som de är läser du avsnittet Importera eller exportera JSON-dokument . Om du vill kopiera från tabellformade data läser du Schemamappning.
Exempel
"activities":[
{
"name": "CopyToMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "MongoDbV2Sink",
"writeBehavior": "upsert"
}
}
}
]
Du kan använda den här MongoDB-anslutningsappen för att enkelt:
- Kopiera dokument mellan två MongoDB-samlingar som de är.
- Importera JSON-dokument från olika källor till MongoDB, bland annat från Azure Cosmos DB, Azure Blob Storage, Azure Data Lake Store och andra filbaserade butiker som stöds.
- Exportera JSON-dokument från en MongoDB-samling till olika filbaserade arkiv.
Om du vill uppnå en sådan schemaagnostisk kopia hoppar du över avsnittet "struktur" (kallas även schema) i datauppsättningen och schemamappningen i kopieringsaktiviteten.
Om du vill kopiera data från MongoDB till tabellmottagare eller omvänd, se schemamappning.
Här följer steg som hjälper dig att uppgradera din länkade tjänst och relaterade frågor:
Skapa en ny Länkad MongoDB-tjänst och konfigurera den genom att referera till länkade tjänstegenskaper.
Om du använder SQL-frågor i dina pipelines som refererar till den gamla Länkade MongoDB-tjänsten ersätter du dem med motsvarande MongoDB-frågor. Se följande tabell för ersättningsexempel:
SQL-fråga Motsvarande MongoDB-fråga SELECT * FROM usersdb.users.find({})SELECT username, age FROM usersdb.users.find({}, {username: 1, age: 1})SELECT username AS User, age AS Age, statusNumber AS Status, CASE WHEN Status = 0 THEN "Pending" CASE WHEN Status = 1 THEN "Finished" ELSE "Unknown" END AS statusEnum LastUpdatedTime + interval '2' hour AS NewLastUpdatedTime FROM usersdb.users.aggregate([{ $project: { _id: 0, User: "$username", Age: "$age", Status: "$statusNumber", statusEnum: { $switch: { branches: [ { case: { $eq: ["$Status", 0] }, then: "Pending" }, { case: { $eq: ["$Status", 1] }, then: "Finished" } ], default: "Unknown" } }, NewLastUpdatedTime: { $add: ["$LastUpdatedTime", 2 * 60 * 60 * 1000] } } }])SELECT employees.name, departments.name AS department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.id;db.employees.aggregate([ { $lookup: { from: "departments", localField: "department_id", foreignField: "_id", as: "department" } }, { $unwind: "$department" }, { $project: { _id: 0, name: 1, department_name: "$department.name" } } ])
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.